Spotify Churn Model
تفاصيل العمل

يهدف هذا المشروع إلى بناء نموذج تعلم آلي (Machine Learning) قادر على التنبؤ بالمستخدمين المحتمل توقفهم عن استخدام خدمة بث الموسيقى (مثل Spotify). يعتبر "تسرب العملاء" (Churn) من أكبر التحديات التي تواجه شركات الاشتراكات، ولذلك يساعد هذا المشروع في تحديد هؤلاء العملاء مبكراً لاتخاذ إجراءات استباقية للحفاظ عليهم.
الخطوات المنجزة في المشروع:
معالجة وتنظيف البيانات (Data Cleaning):
التعامل مع القيم المفقودة (Null Values) في أعمدة مثل user_id و gender باستخدام القيم الوسيطة (Median) والمنوال (Mode).
إزالة البيانات المكررة لضمان دقة التحليل.
حذف الأعمدة غير المؤثرة (مثل user_id، gender، country).
تحليل البيانات الاستكشافي (EDA):
دراسة توزيع البيانات باستخدام الرسوم البيانية (Histograms, Countplots).
تحليل الارتباط (Correlation Heatmap) بين الميزات المختلفة وسلوك الإلغاء.
استخدام اختبار "مربع كاي" (Chi-Square) لتحديد أهم الميزات المؤثرة.
هندسة الميزات (Feature Engineering):
إنشاء ميزات جديدة لزيادة دقة النموذج، مثل:
EngagementScore: مقياس لمستوى تفاعل المستخدم.
PremiumMobile: لتحديد مستخدمي الهواتف باشتراكات مدفوعة.
AdsEngagement: نسبة التفاعل مع الإعلانات مقارنة بوقت الاستماع.
تحويل البيانات الفئوية (Categorical) إلى رقمية باستخدام LabelEncoder.
معالجة عدم توازن البيانات (Handling Imbalanced Data):
لوحظ أن عدد العملاء "المغادرين" أقل بكثير من "المستمرين".
تم استخدام تقنية SMOTE لموازنة عينة التدريب فقط، لضمان عدم انحياز النموذج للفئة الأكبر.
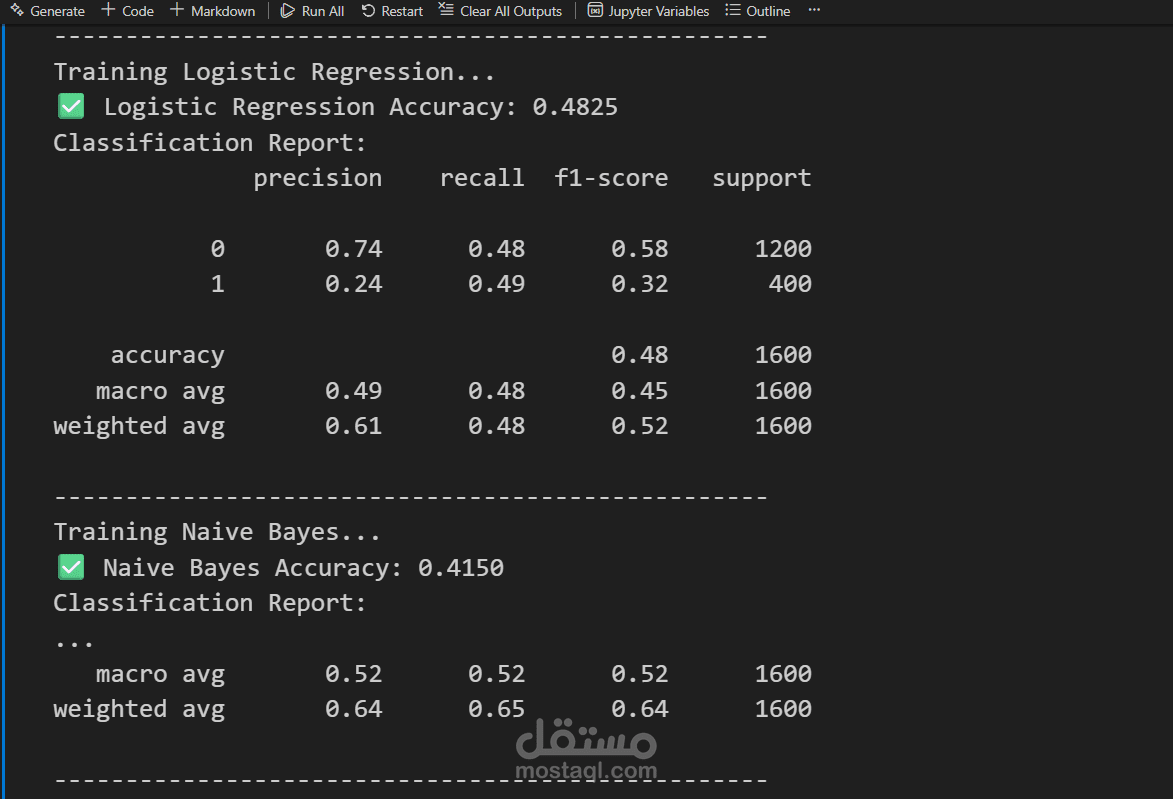
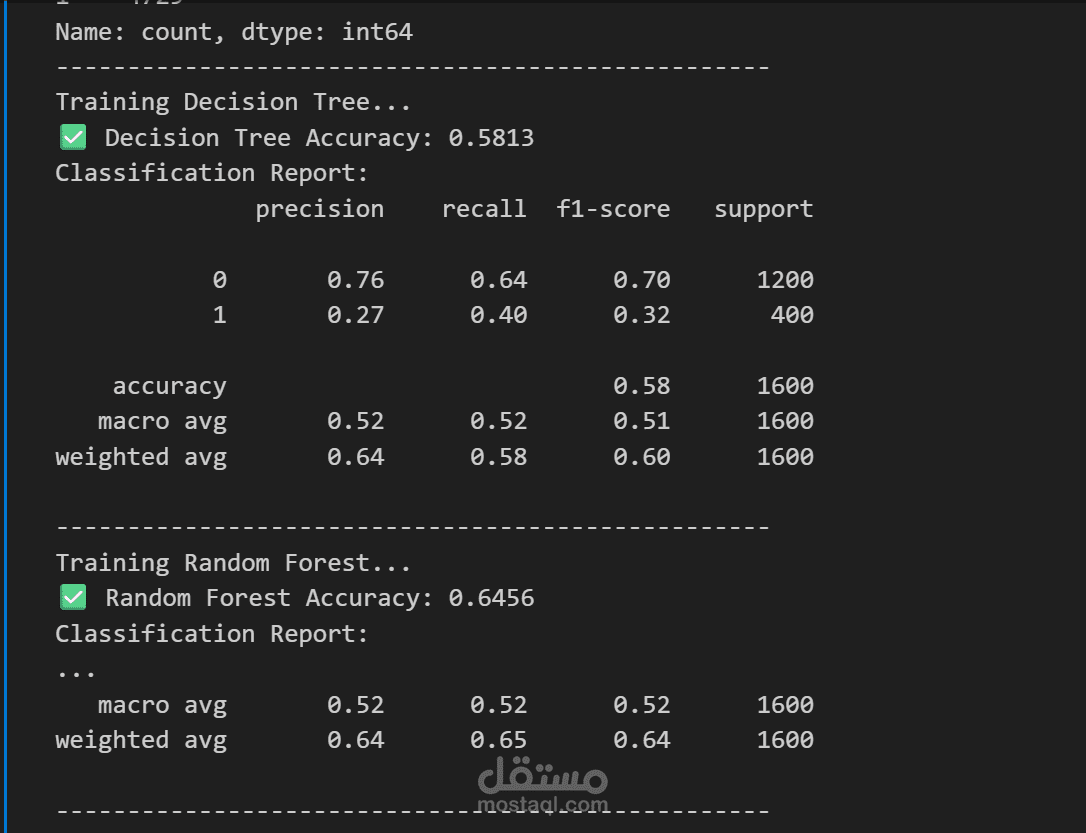
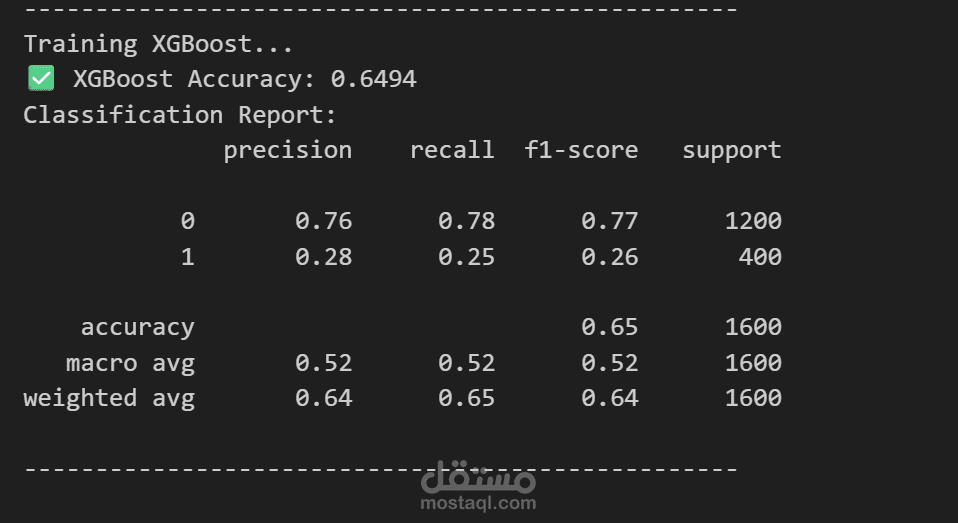
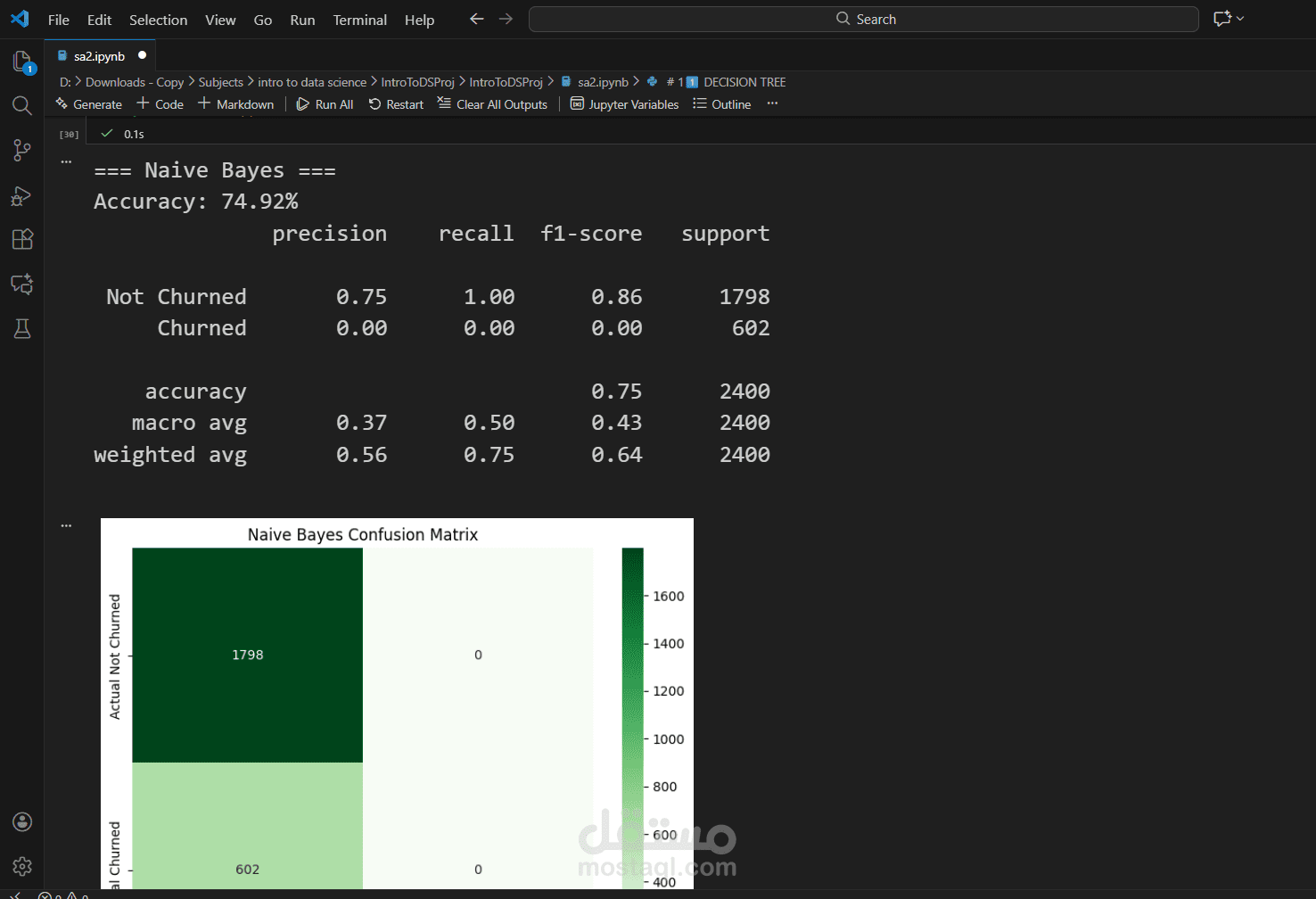
بناء النماذج وتقييمها (Modeling & Evaluation):
تم تجربة خوارزميات قوية مثل Random Forest و XGBoost.
تم تقييم النماذج باستخدام مقاييس الدقة (Accuracy)، الاستدعاء (Recall)، و F1-Score، مع التركيز على مصفوفة الارتباك (Confusion Matrix) لفهم أداء النموذج بشكل دقيق.
التقنيات المستخدمة:
Python (Pandas, NumPy, Matplotlib, Seaborn).
Scikit-Learn (RandomForest, LabelEncoder, StandardScaler).
Imbalanced-learn (SMOTE).
XGBoost.