food vision
تفاصيل العمل
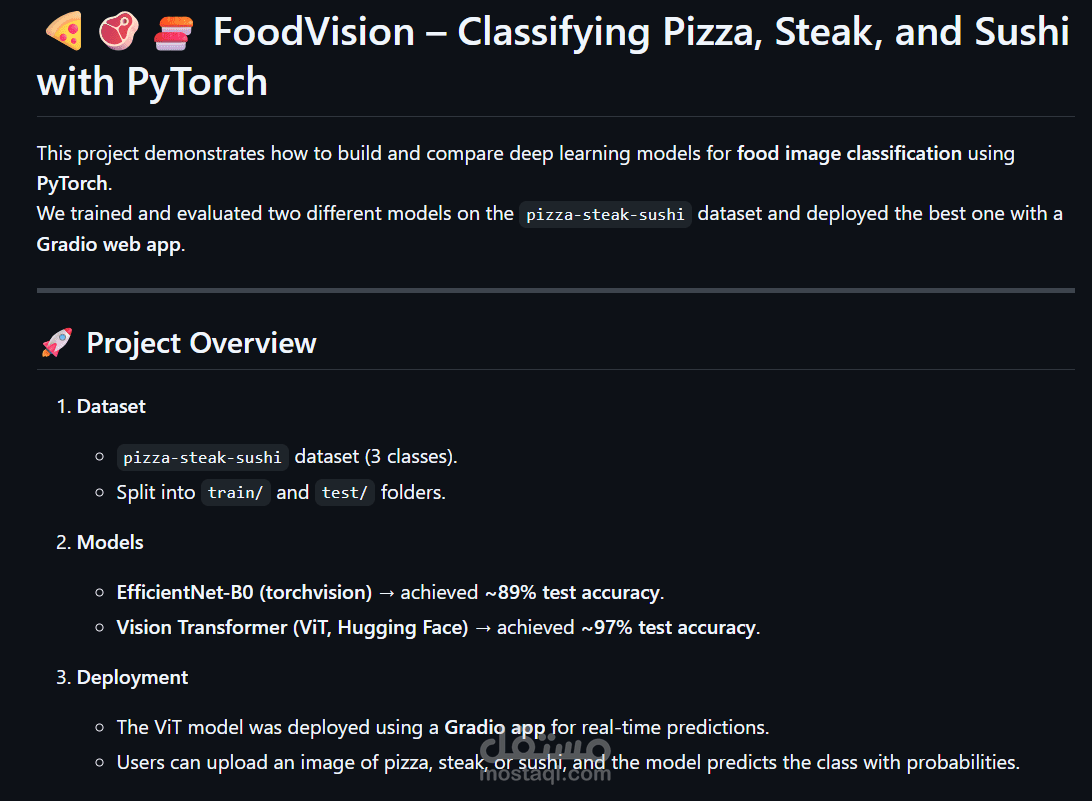
Developed an end-to-end image classification system to distinguish
between pizza, steak, and sushi images.
Built and compared EfficientNet-B0 (89% accuracy) and Vision
Transformer (ViT, 97% accuracy) with Hugging Face.
Applied data augmentation (Albumentations) and monitored training
with Tensorboard.
Deployed the ViT model as a Gradio web app for real-time predictions
with confidence scores