Credit Card Fraud Detection
تفاصيل العمل


الهدف من هذا المشروع هو بناء نظام ذكي لحساب احتمالية الاحتيال (Fraud Probability) للمعاملات البنكية بدقة متناهية، بدلاً من مجرد التصنيف التقليدي.
تم تدريب النظام على مجموعة بيانات ضخمة (Credit Card Fraud Dataset 2023) تحتوي على أكثر من 284,000 معاملة، مع التركيز على استراتيجية تقسيم صارمة (90/5/5 Split) لضمان موثوقية النتائج.
المنهجية الهندسية (Methodology): بدلاً من الاعتماد على خوارزميات التصنيف العمياء، قمت بتطبيق نهج Regression-Based Scoring:
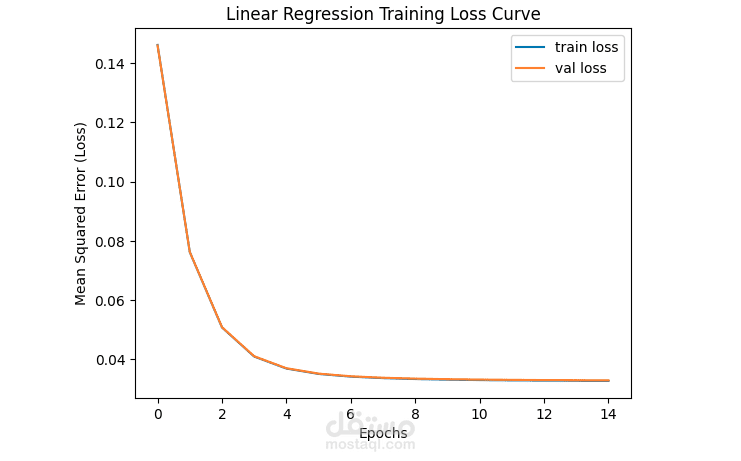
Linear Regression via SGD:
استخدمت Stochastic Gradient Descent (SGD) لبناء نموذج خفيف وسريع قادر على التعلم التكراري (Iterative Learning).
تم ضبط الـ Hyperparameters بدقة (Learning Rate: constant, Penalty: l2) لضمان استقرار الـ Loss Curve.
K-Nearest Neighbors (KNN Regressor):
تطبيق خوارزمية KNN لحساب درجة الخطورة بناءً على "الجيران" الأقرب للمعاملة (Local Anomalies).
استخدمت تقنيات Parallel Processing (n_jobs=-1) لتسريع عملية التدريب على البيانات الضخمة.
معالجة البيانات (Data Pipeline):
Zero Data Leakage: تم تطبيق الـ StandardScaler على بيانات التدريب فقط، ثم استخدامه لتحويل بيانات الاختبار، لضمان عدم تسرب أي معلومات مستقبلية للموديل.
Feature Engineering: التعامل مع 29 Feature رقمية معقدة (V1-V28).
النتائج (Performance): النظام حقق أداءً استثنائياً يثبت كفاءة التصميم:
KNN Accuracy: 99.97%.
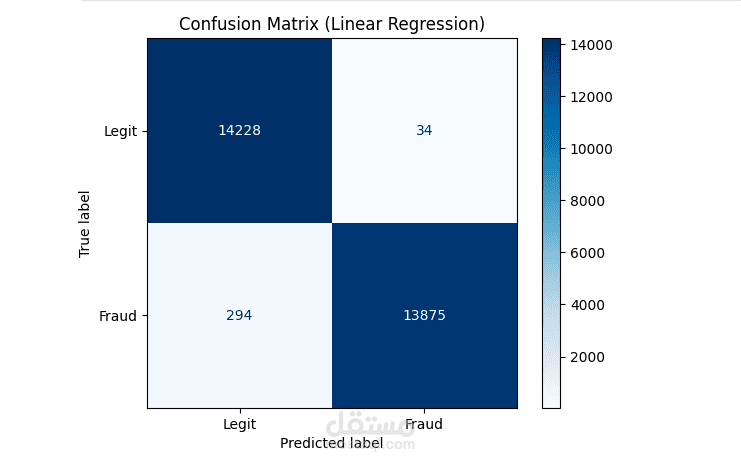
Linear Model Accuracy: 98.97%.
ROC AUC Score: ~1.00 (مما يعني قدرة مثالية على الفصل بين المعاملات السليمة والمزورة).
التقنيات المستخدمة:
Algorithms: SGDRegressor, KNeighborsRegressor.
Validation: ROC Curve, Confusion Matrix, Loss Curves.
Stack: Python, Scikit-Learn.