House Price Prediction
تفاصيل العمل


الهدف من هذا المشروع لم يكن مجرد بناء موديل يتوقع أسعار المنازل، بل بناء Production-Ready Pipeline يتفوق على الحلول التقليدية (Baselines) باستخدام معمارية هجينة (Hybrid Ensemble Architecture).
المشكلة في الـ Datasets الصغيرة هي الـ Overfitting. لذلك، بدلاً من الاعتماد على خوارزمية واحدة، قمت بدمج قوة الـ Gradient Boosting مع استقرار الـ Linear Models.
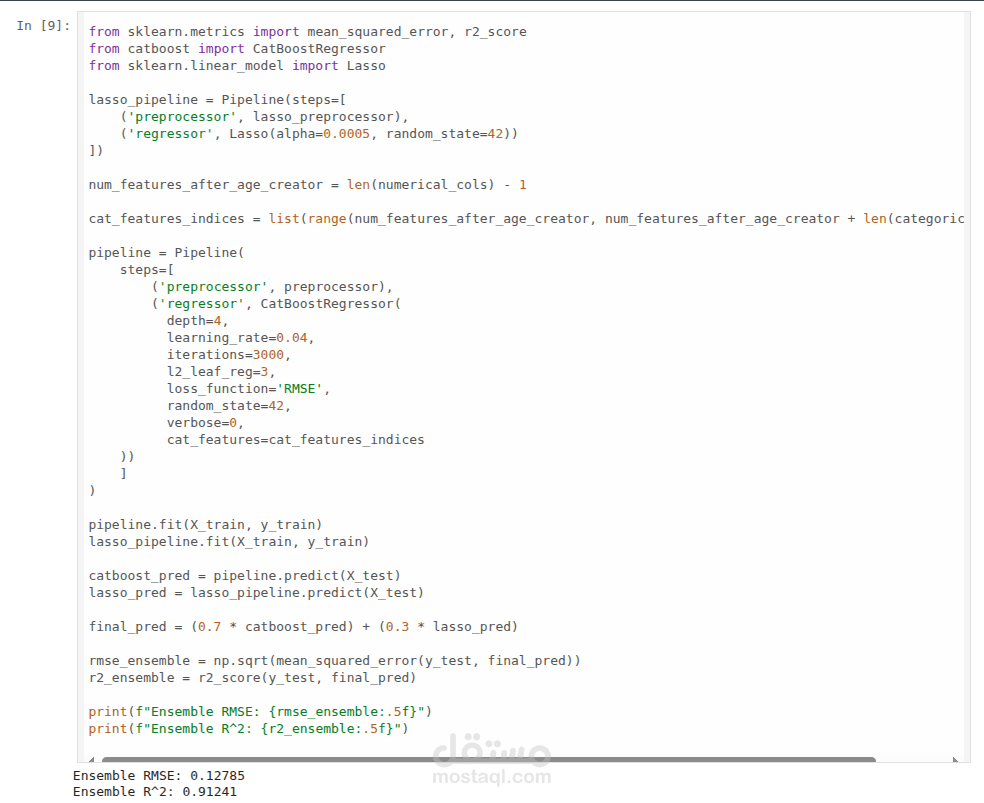
كيف يعمل الـ System؟ بنيت Voting Regressor يقوم بدمج التوقعات من نموذجين مختلفين بنسب موزونة (Weighted Average) لتقليل نسبة الخطأ (Variance Reduction):
CatBoost Regressor (Weight: 70%):
وظيفته التقاط الـ Non-Linear Patterns والعلاقات المعقدة في البيانات (مثل تأثير الحي السكني على السعر).
استخدمته لأنه يتعامل بذكاء مع الـ Categorical Features دون الحاجة لـ One-Hot Encoding ضخم.
Lasso Regression (Weight: 30%):
وظيفته التقاط الـ Linear Trends الأساسية (مساحة أكبر = سعر أعلى).
استخدمت الـ Lasso تحديداً لأنه يقوم بـ Feature Selection ويقلل الـ Noise.
الهندسة البرمجية (Engineering & Pipelines): أهم جزء في هذا المشروع هو الـ Robustness:
Preventing Data Leakage: كل عمليات الـ Feature Engineering تمت داخل Scikit-Learn Pipelines لضمان عدم تسرب أي معلومات من الـ Test Set أثناء التدريب.
Target Transformation: قمت بتطبيق Log-transform على أسعار المنازل لمعالجة الـ Skewness في البيانات وتحسين دقة التوقع.
النتائج (Performance): النتيجة كانت نظاماً قوياً ومستقراً جداً على البيانات الجديدة:
R² Score: 0.91 (النموذج يفسر 91% من حركة الأسعار بدقة).
RMSE: 0.1275.
التقنيات المستخدمة:
Core: Python, Scikit-Learn.
Models: CatBoost, Lasso Regression.
Data Prep: Pandas, NumPy, Pipelines.
هذا المشروع يثبت قدرتي على التعامل مع Complex Architectures وفهم الـ Trade-offs بين الموديلات المختلفة للحصول على أفضل دقة.