From Pixels to Predictions: Building a Custom DNN for MNIST
تفاصيل العمل
Diving into Deep Neural Networks with MNIST!
I built a custom DNN to recognize handwritten digits (0-9), and it was a fascinating journey:
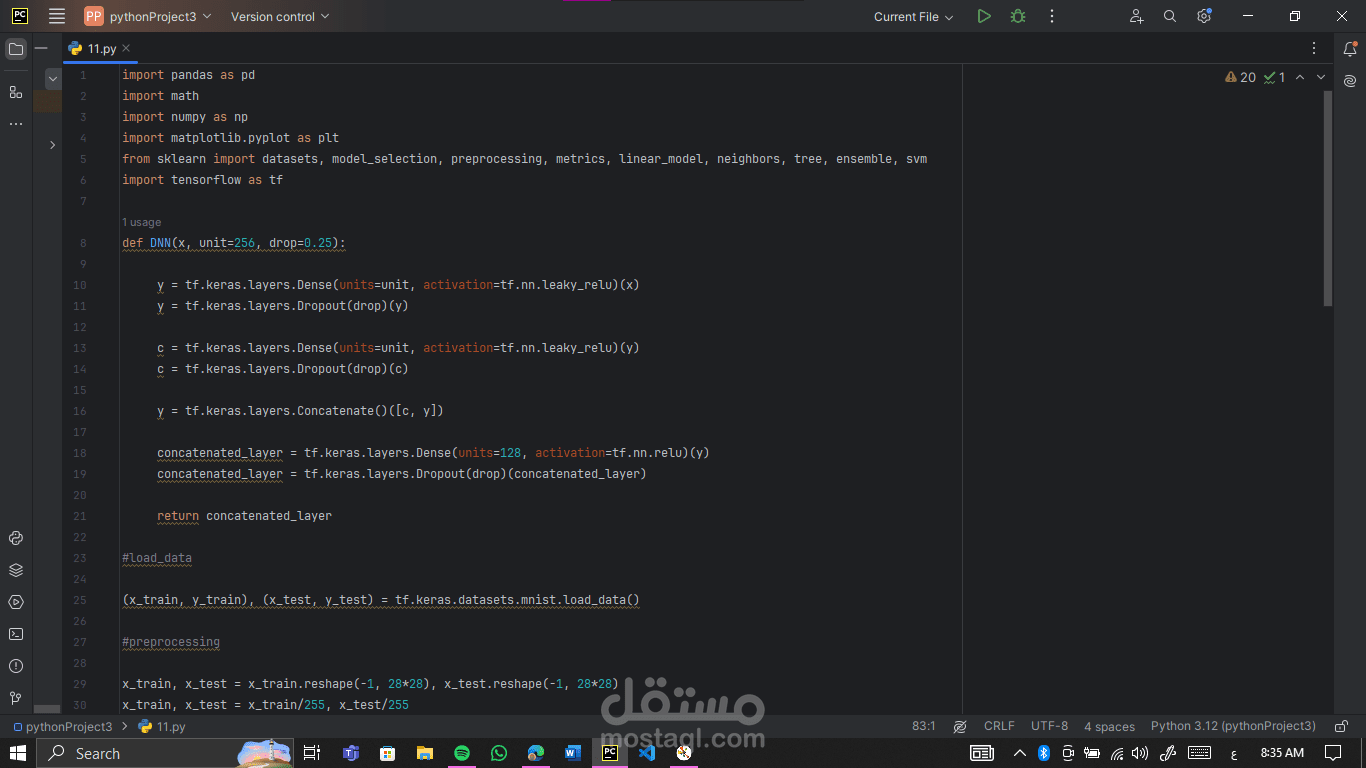
Preprocessing: Each 28x28 image was flattened into a 784-length vector, and pixel values were scaled to [0,1]. Labels were one-hot encoded. Simple, but it makes learning faster and more stable.
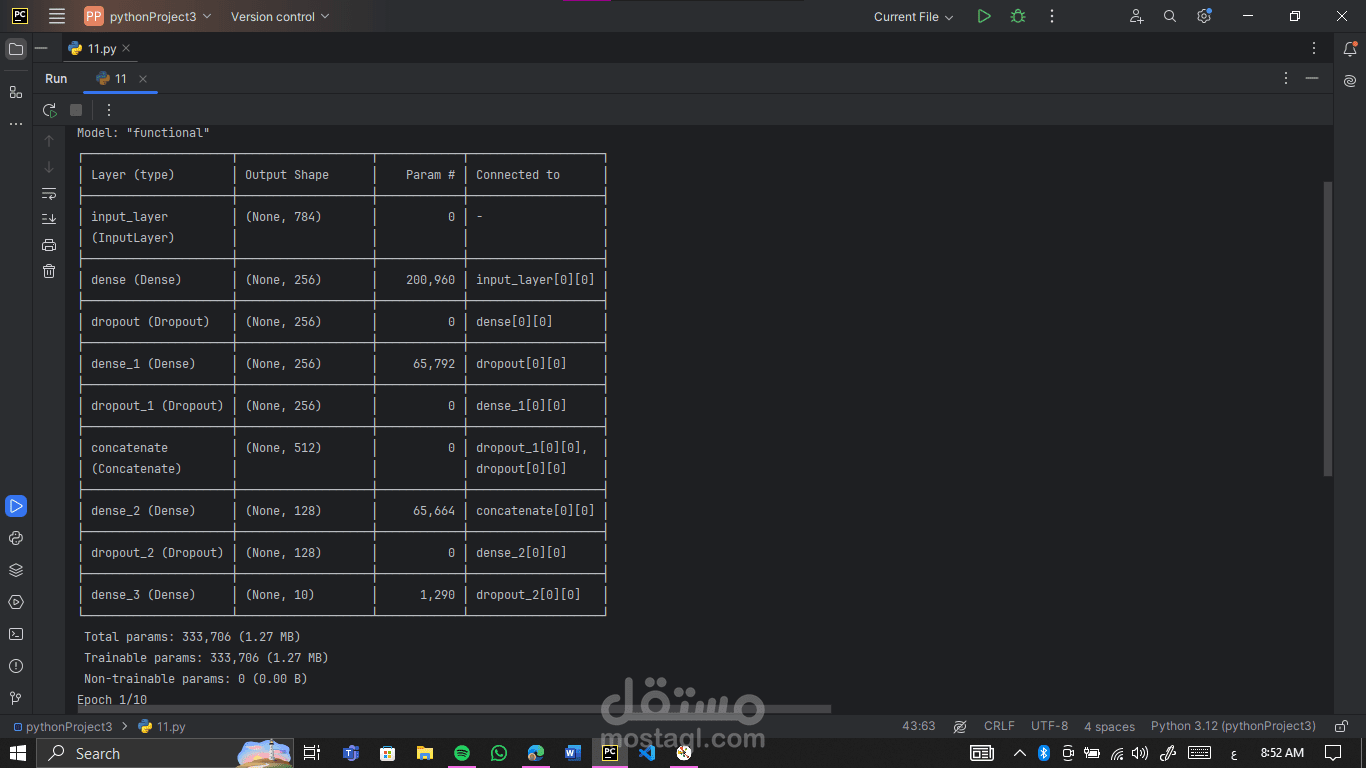
Dense layers with Leaky ReLU: Capture complex patterns while avoiding “dead neurons.” These layers help the network think smarter.
Dropout layers: Strategically placed to prevent overfitting. Randomly disabling neurons during training forces the model to generalize instead of memorizing.
Layer concatenation: Merging outputs from multiple layers gives the network richer insights. Think of it as giving the model multiple perspectives on the same data.
concatenated layer with ReLU: Adds non-linearity and captures more intricate relationships before passing information to the output layer. A mini “decision hub” inside the network.
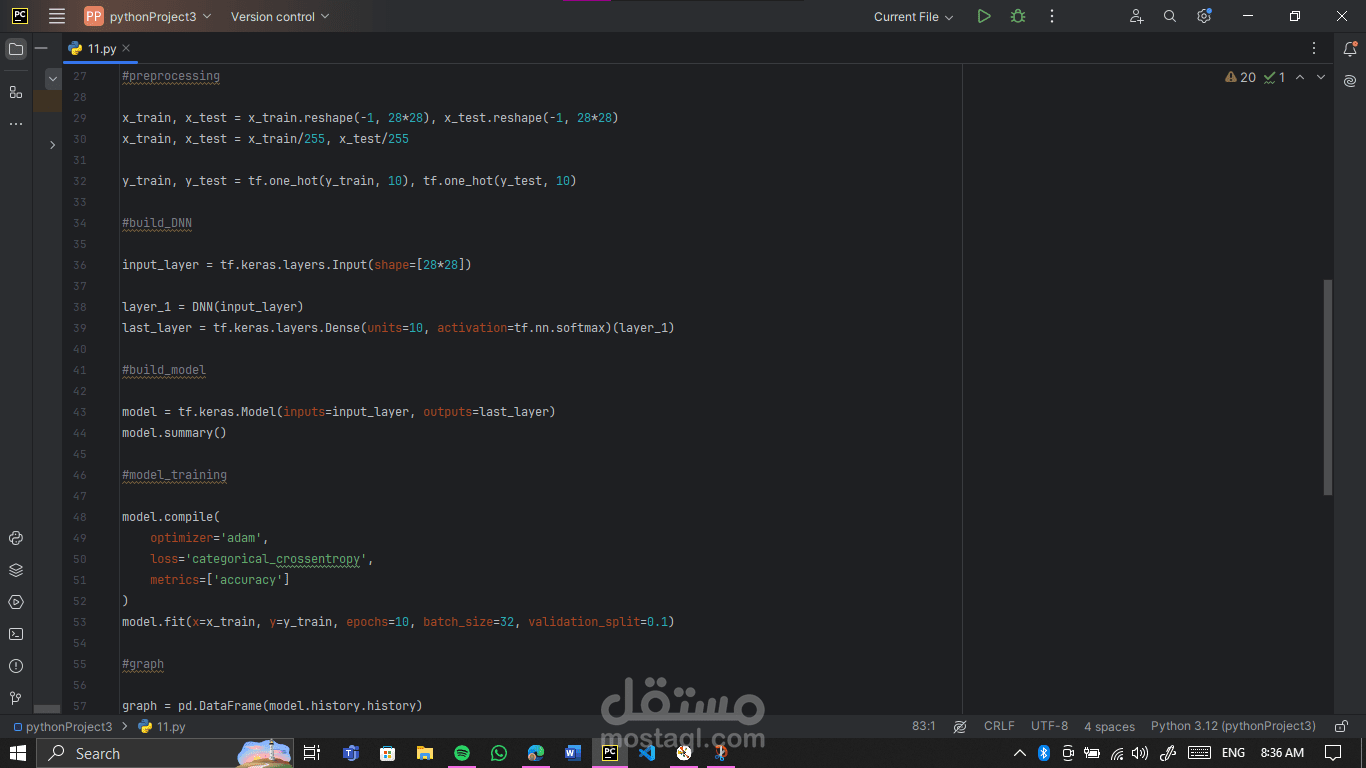
Model compilation & Softmax output: Using Adam optimizer and categorical crossentropy ensures efficient learning. Softmax converts outputs into probabilities for each digit.
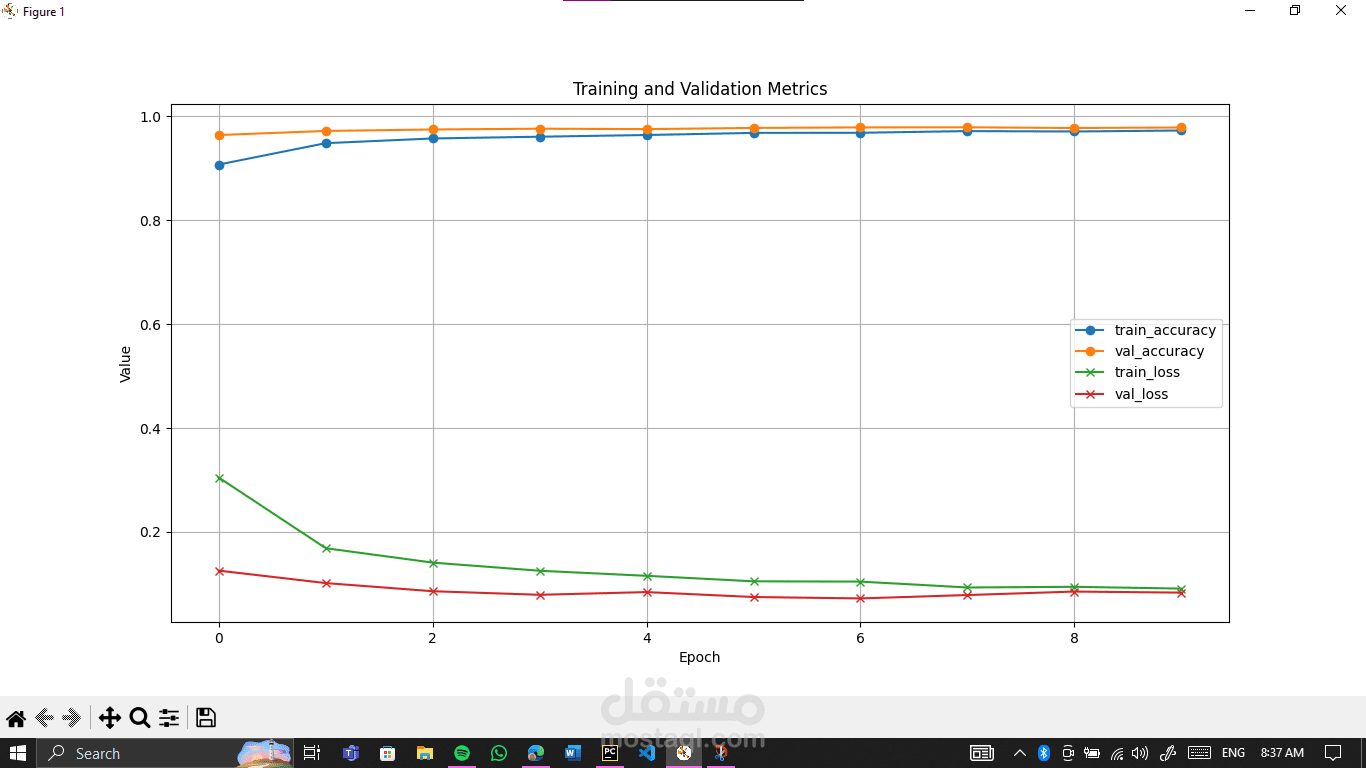
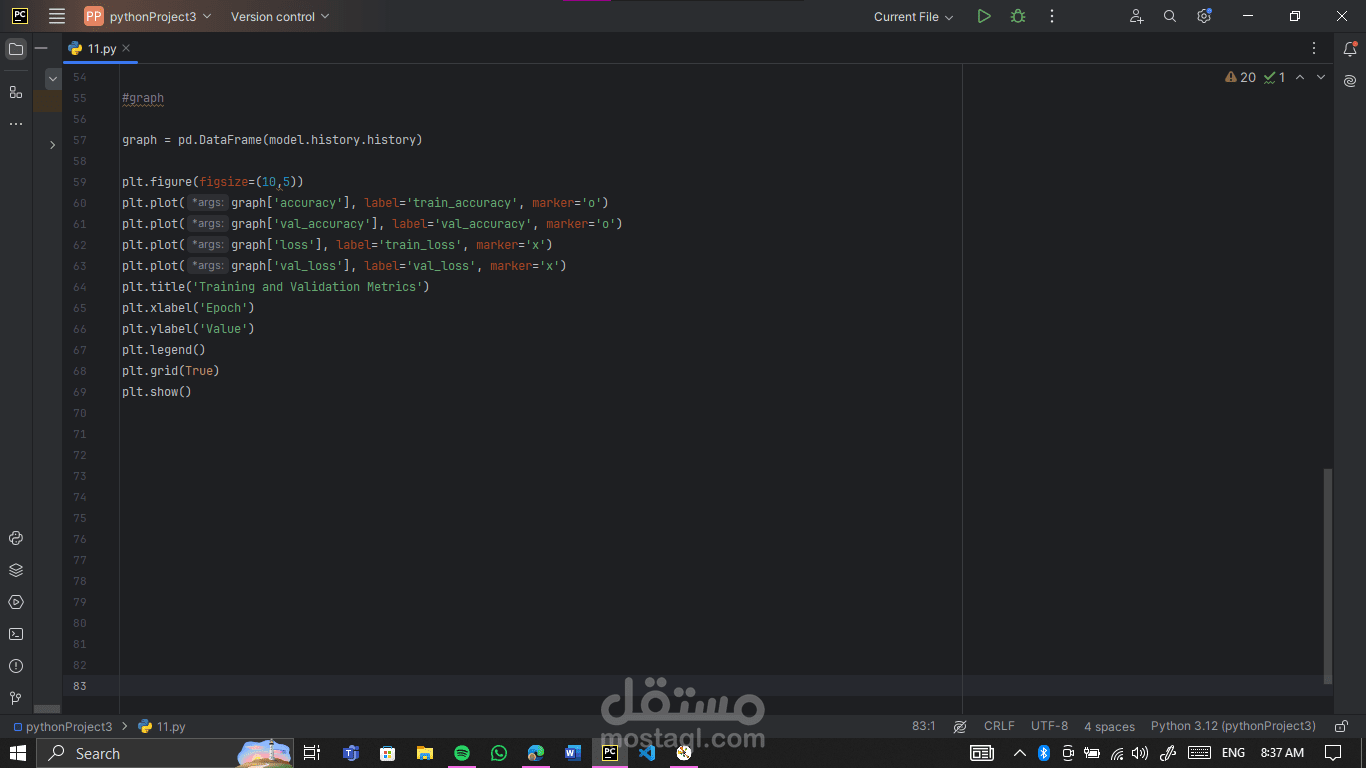
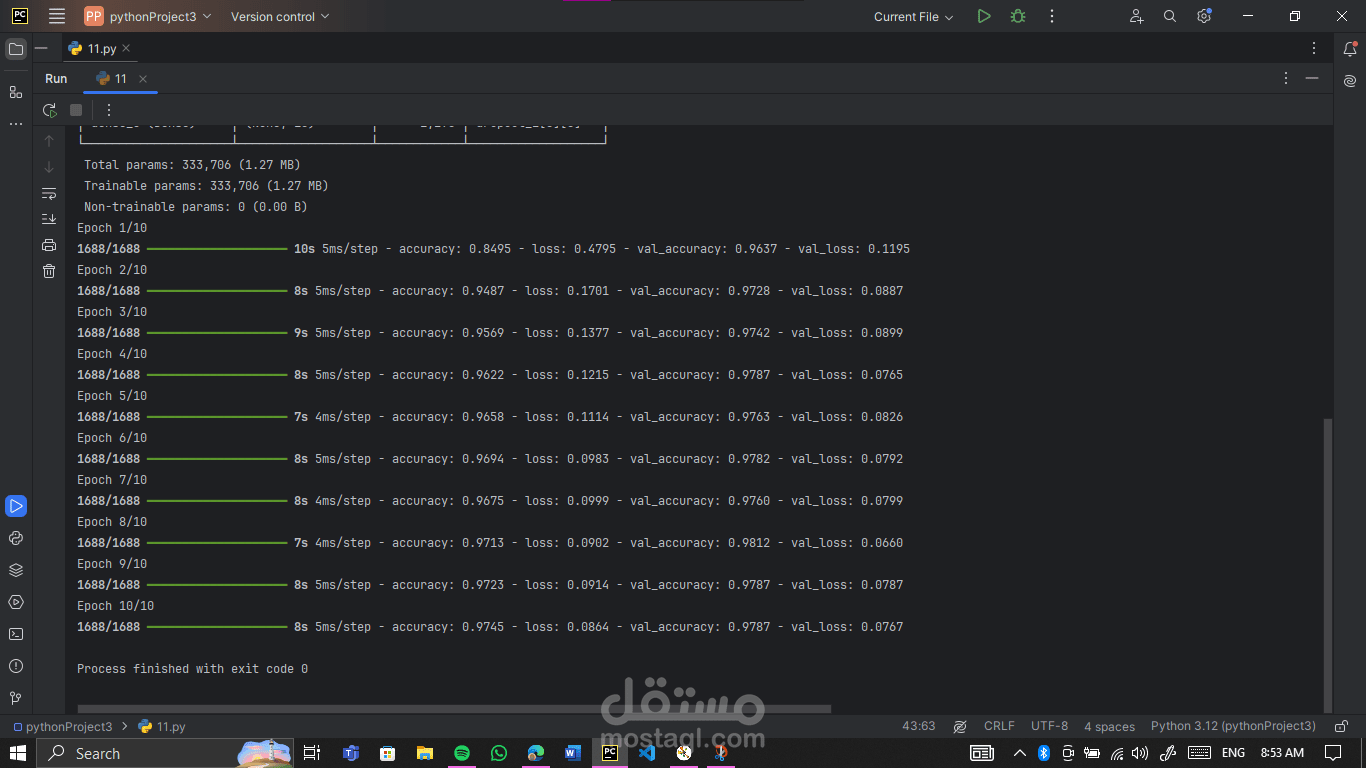
Trained on 90% of the data and validated on 10%, watching accuracy rise and loss drop over epochs was incredibly satisfying. Visualizing metrics gives a peek into how the network “thinks” and evolves.
I’m excited to keep learning and experimenting with more complex architectures and datasets!