Predicting Football Match Result
تفاصيل العمل
Kicking Off My First ML Project: Predicting Football Match Outcomes! ?
I’m excited to share the journey of my very first dive into Machine Learning—centered entirely around football. Here’s what I did, step by step:
Data Preparation
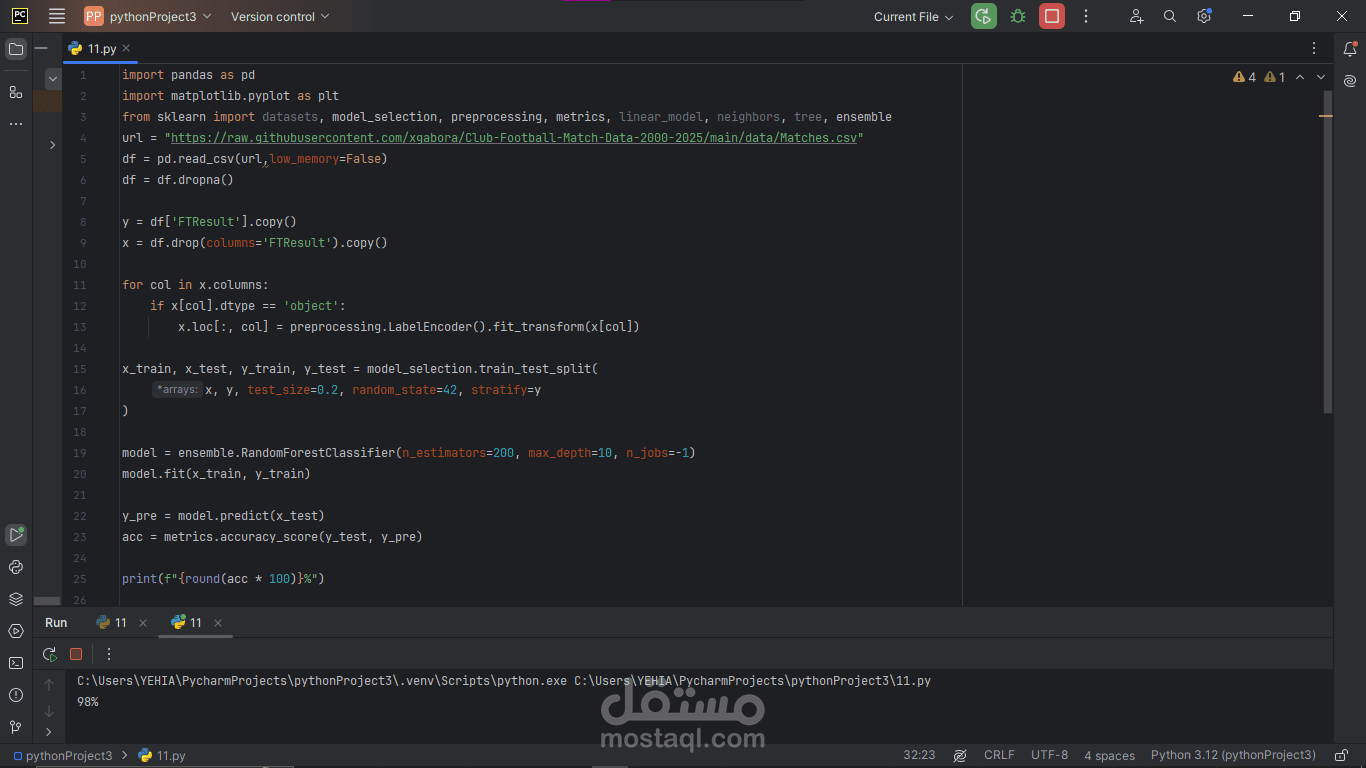
Loading & Cleaning: Read a CSV of 31,500+ club matches (July 6, 2019 – June 1, 2025) with low_memory=False and dropped any rows missing values.
Encoding: Converted every text column (team names, league, dates, and the result label H/D/A) into numeric codes so the model could understand them.
Splitting: Separated the FTResult column (our target) from all other features, then split into 80% training and 20% testing sets, stratified by result.
️️ Modeling
Algorithm: Random Forest classifier with 200 trees and a maximum depth of 10.
Training: Fitted the model on the training set until it learned patterns in possession, form, and odds.
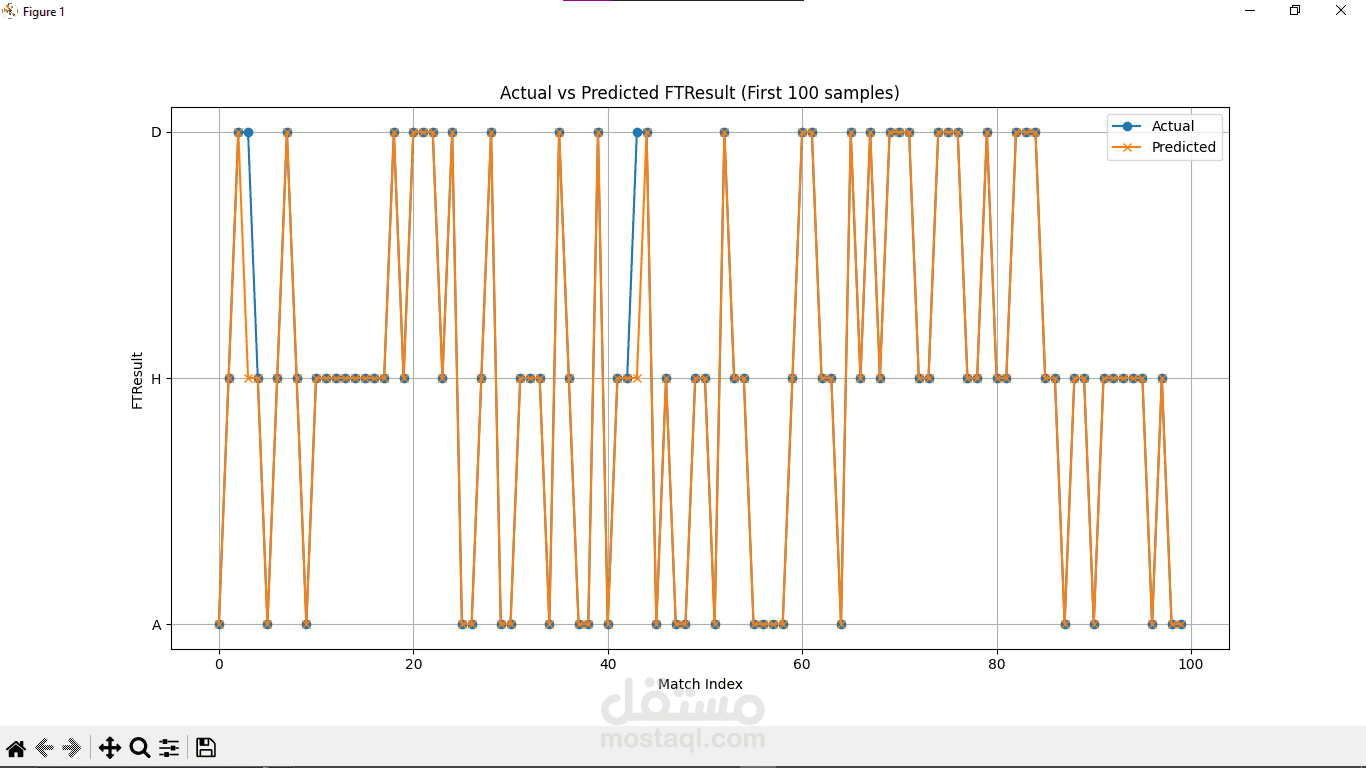
Performance: Achieved 98% accuracy on the unseen test matches—far beyond my initial expectations!
Visualization
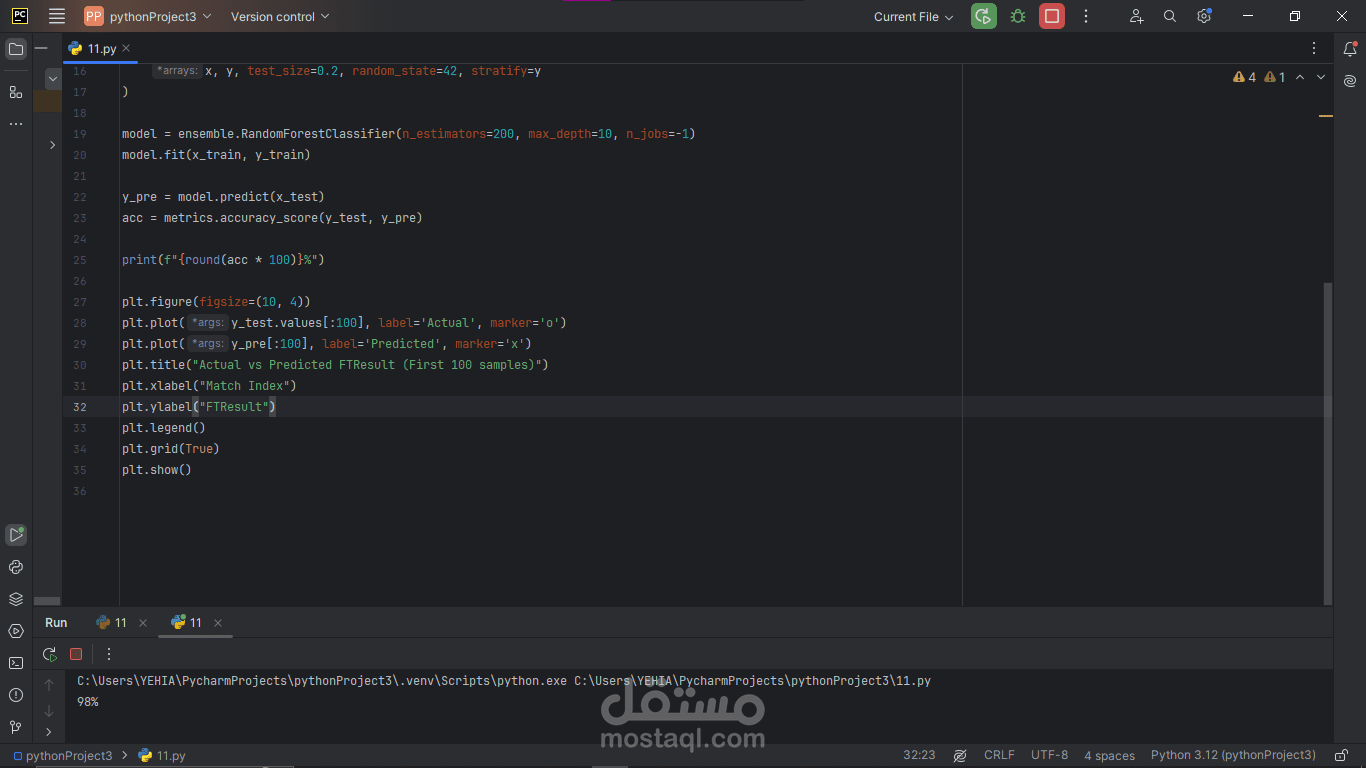
Plotted the first 100 actual vs. predicted FTResult values, marking each point by H (home win), D (draw), or A (away win). Watching the markers overlap so closely was truly exhilarating.
I’m looking forward to building stronger models across diverse domains!
Tools & Tech: Python | pandas | matplotlib | scikit-learn
Data Source: Club Football Match Data (2000–2025)