Web scraping
تفاصيل العمل
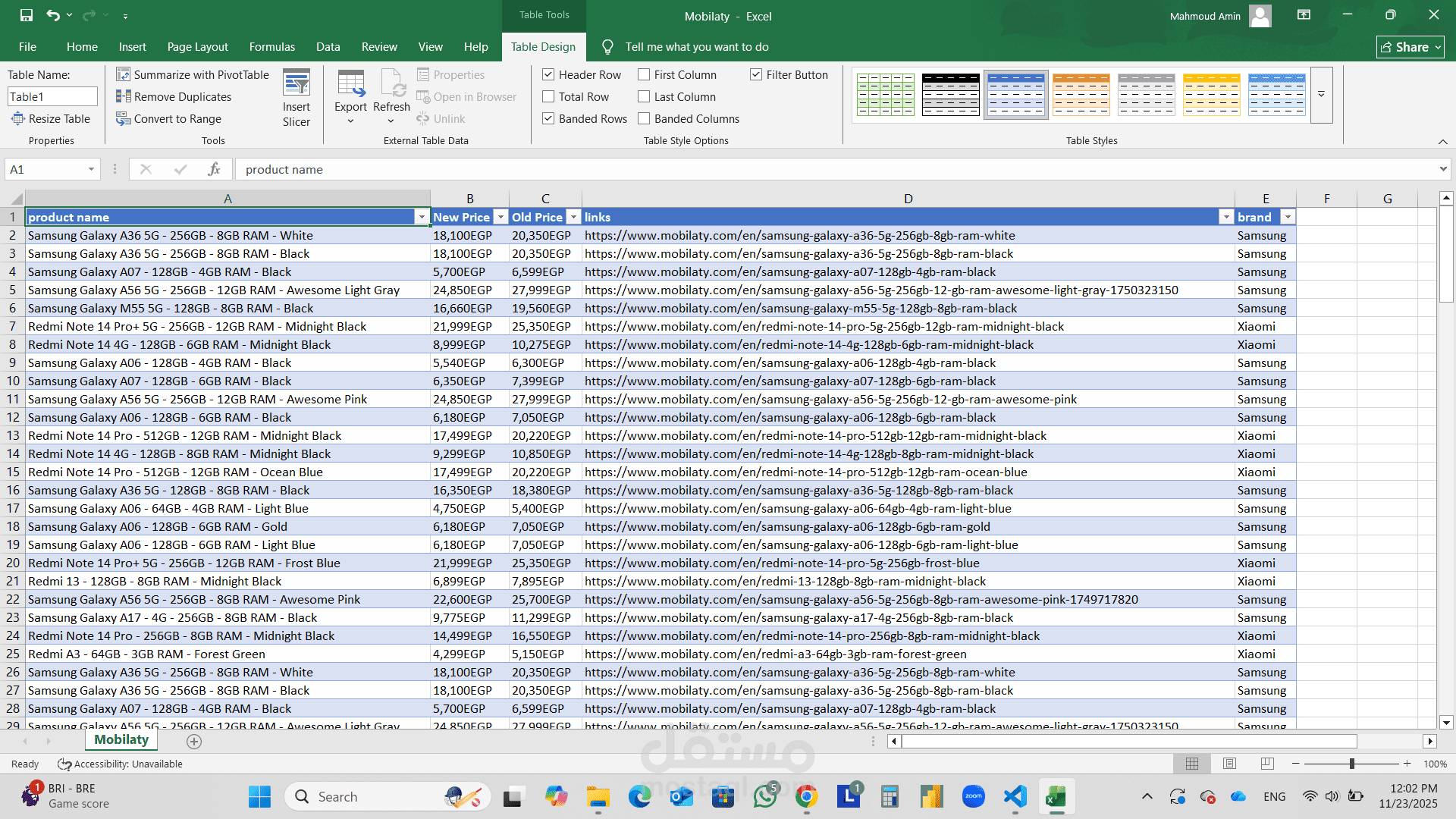
مشروع Web scraping
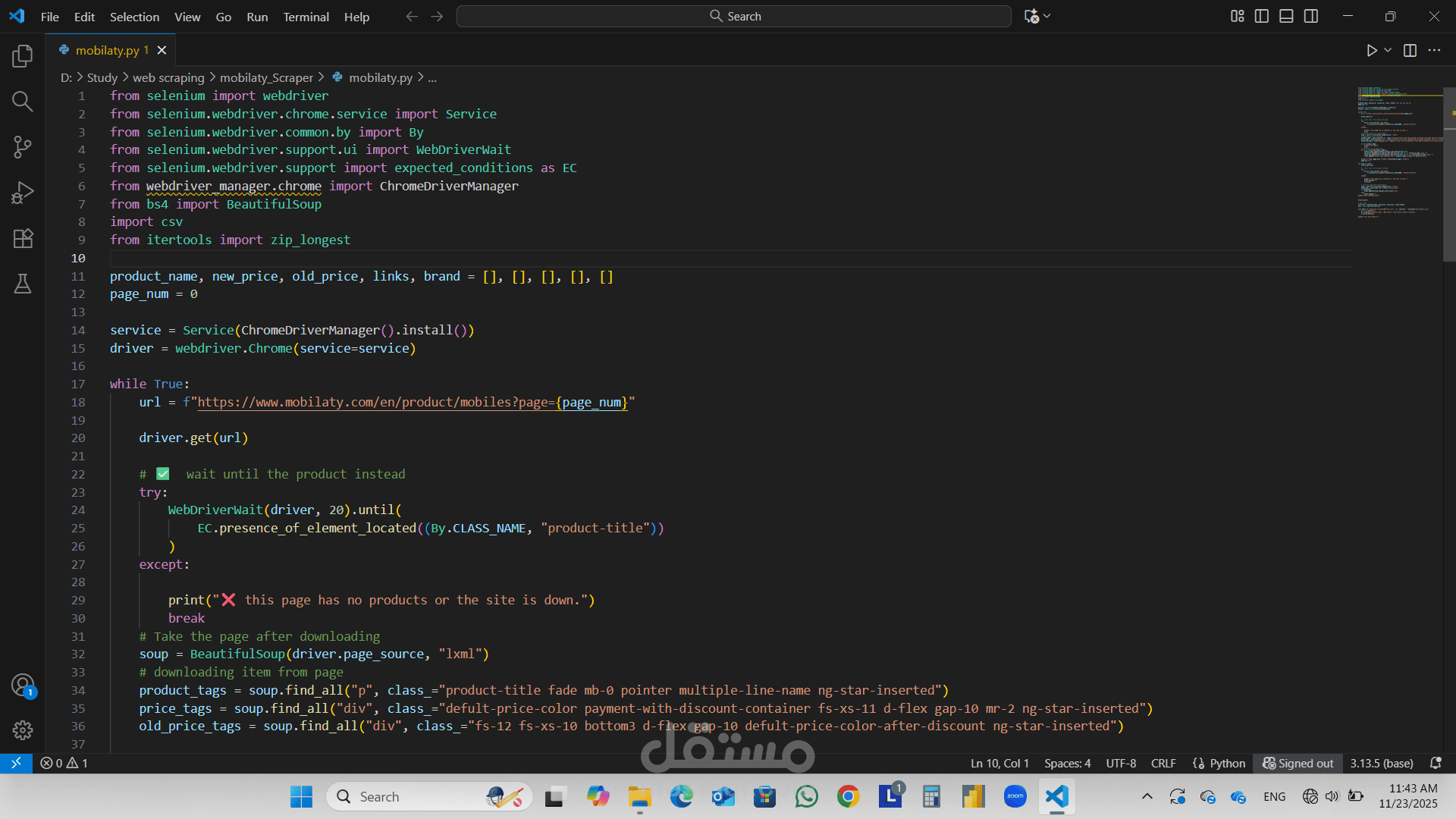
عملتُ مؤخرًا على مشروع استخراج بيانات الهواتف المحمولة من موقع
Mobilaty، بما في ذلك اسم المنتج، والعلامة التجارية، والسعر الجديد والقديم، وروابط المنتجات.
كان من أكبر التحديات في هذا المشروع أن Mobilaty موقع ويب مُصمم بلغة JavaScript، مما يعني أن المحتوى لا يظهر في مصدر HTML الأصلي.
ولهذا السبب، لم تكن أدوات استخراج البيانات التقليدية مثل Requests وBeautifulSoup كافية.
لذلك استخدمتُ مجموعةً من الأدوات للتعامل مع المحتوى الديناميكي بكفاءة:
التقنيات والمكتبات المستخدمة
-Selenium WebDriver → لعرض جافا سكريبت وتحميل محتوى الصفحة بالكامل
-ChromeDriverManager → لتثبيت وإدارة إصدار ChromeDriver الصحيح تلقائيًا
-WebDriverWait + Expected Conditions (EC) → لانتظار تحميل عناصر محددة بالكامل
BeautifulSoup → لتحليل واستخراج البيانات المنظمة بعد عرض الصفحة
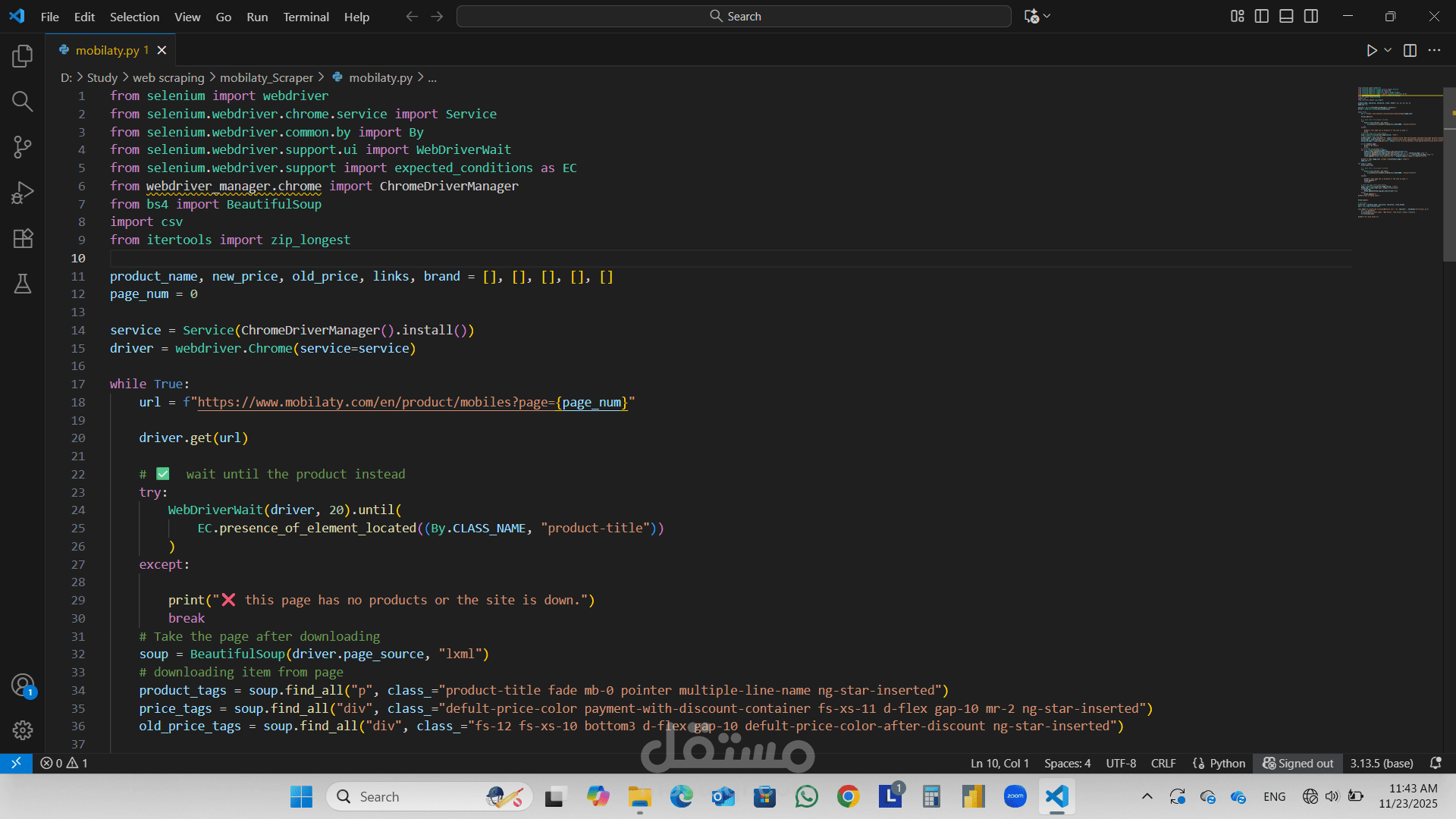
كيفية تعاملي مع عرض جافا سكريبت
يُحمّل Mobilaty بيانات المنتج بشكل غير متزامن، لذلك طبقتُ:
- Explicit Waits — انتظار ظهور عنصر product-title (عنوان المنتج)
- Paginated Scraping — تكرار جميع الصفحات حتى لا توجد أي عناصر أخرى
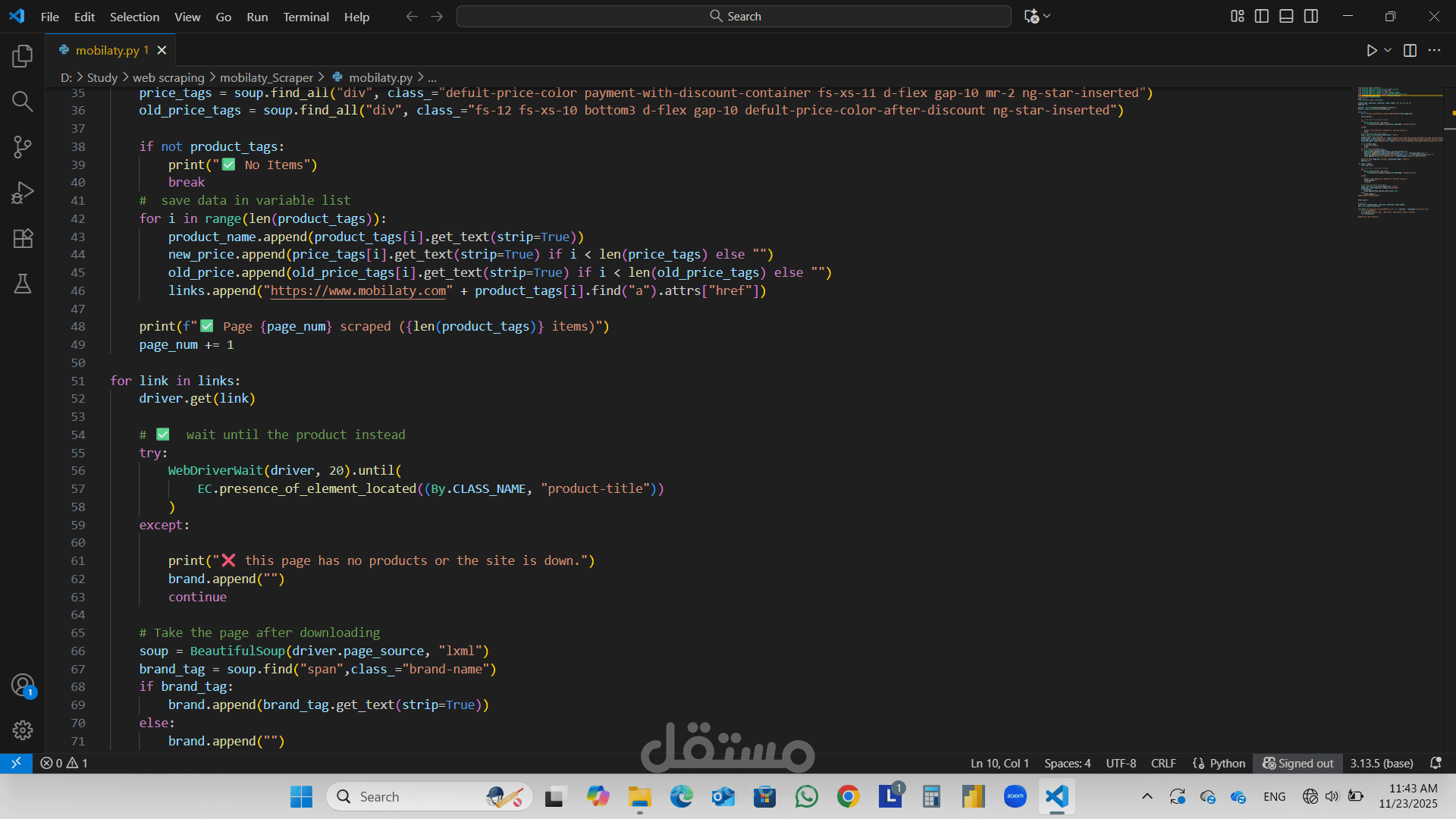
- Secondary Requests — فتح كل رابط منتج على حدة لاستخراج العلامة التجارية
- Error Processing — الكشف عن عدم وجود منتجات في الصفحة أو انتهاء مهلة التسجيل
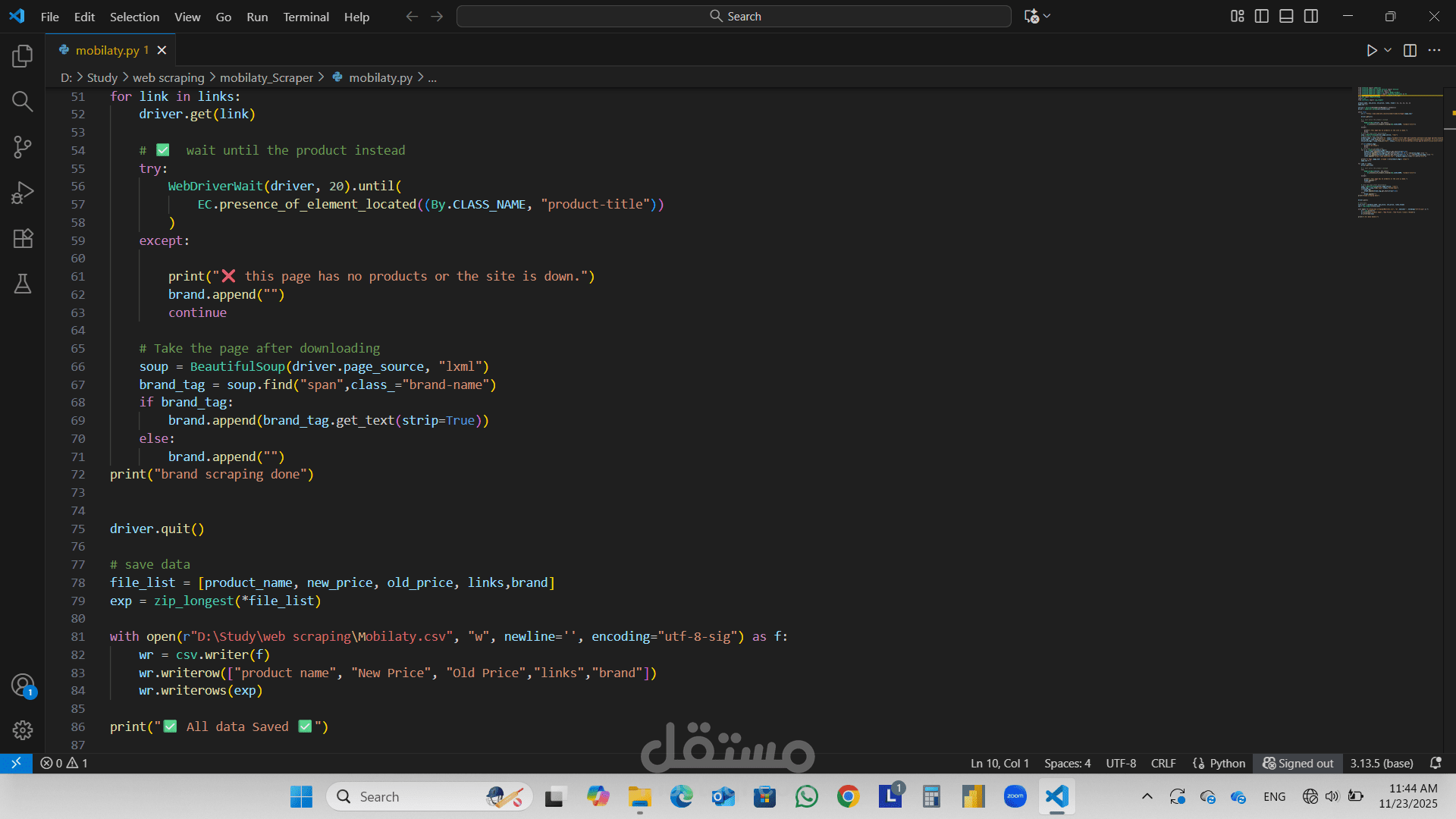
النتيجة النهائية
تم تصدير جميع البيانات المستخرجة إلى ملف Excel نظيف، بما في ذلك:
اسم المنتج
جديد السعر
السعر السابق
العلامة التجارية
يمكن الآن استخدام مجموعة البيانات هذه لمزيد من تحليل البيانات، أو رؤى التسعير.