توليد وصف للصور آلياً باستخدام التعلم العميق (Image Captioning AI)
تفاصيل العمل
قمت بتطوير نظام ذكاء اصطناعي متقدم لتوليد وصف دقيق للصور (Image Captioning) يجمع بين تقنيات الرؤية الحاسوبية (Computer Vision) ومعالجة اللغات الطبيعية (NLP). يعتمد النظام على معمارية حديثة (CNN-Transformer Architecture) لمحاكاة قدرة الإنسان على فهم محتوى الصورة والتعبير عنها نصياً.
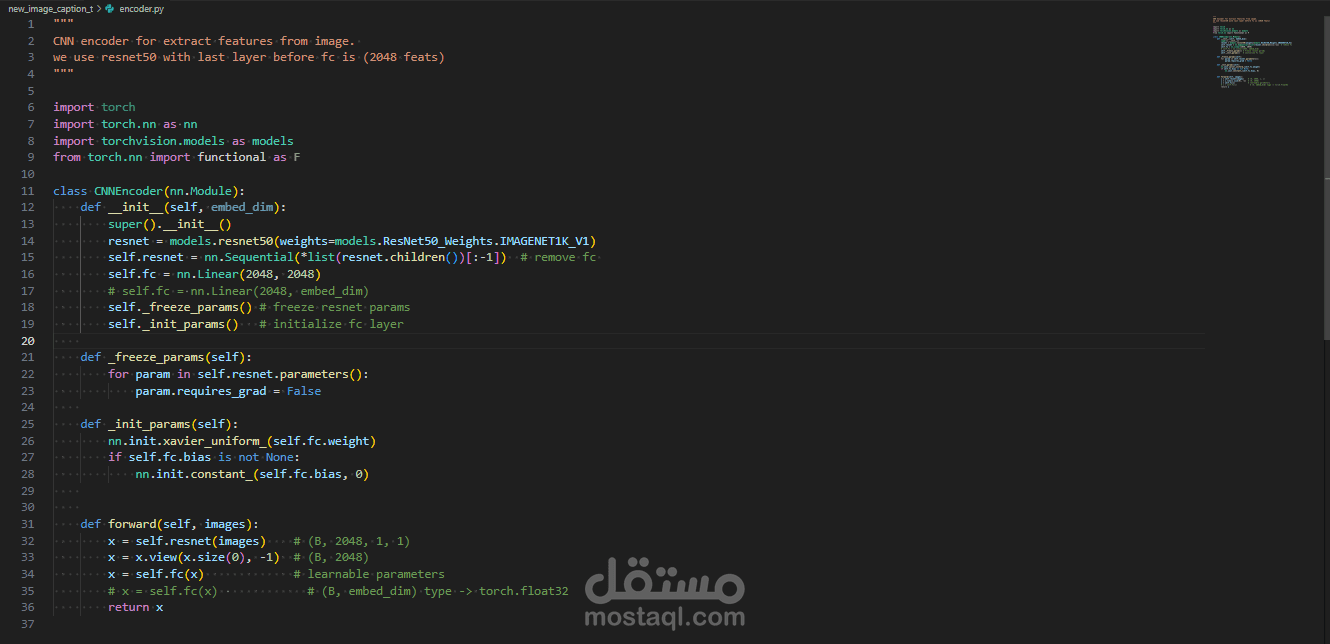
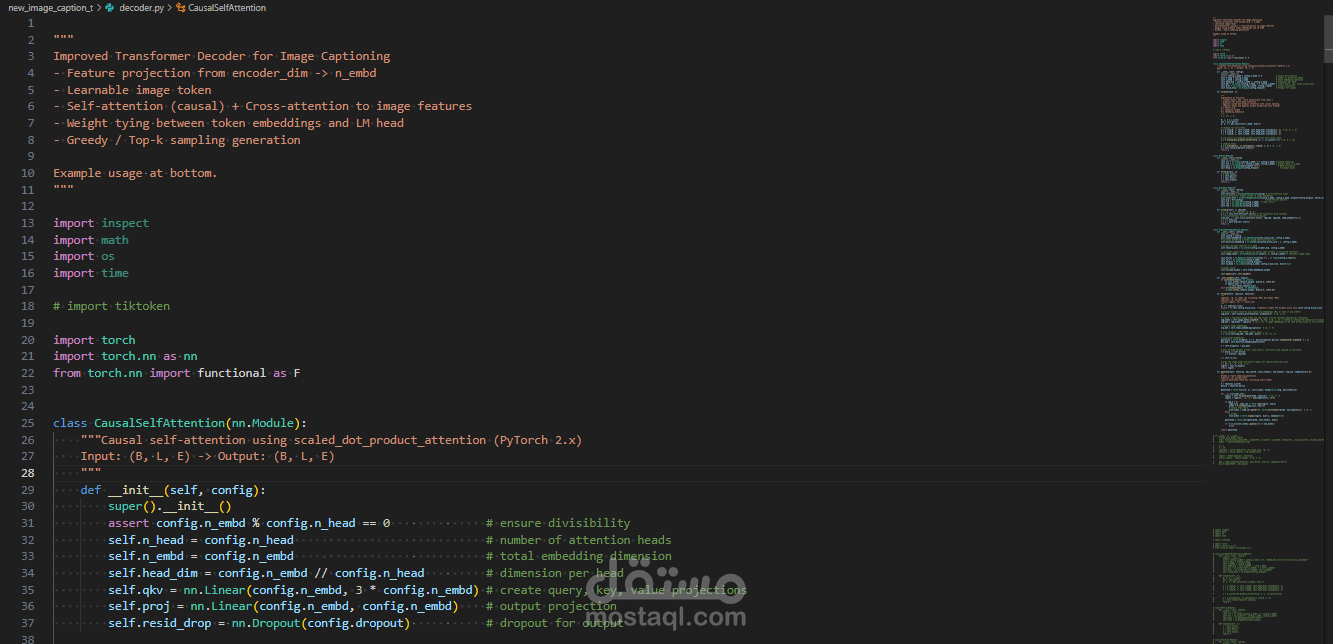
المعمارية التقنية (Model Architecture): تم بناء النموذج باستخدام هيكلية Encoder-Decoder المتطورة:
المشفّر (Encoder): استخدام شبكة ResNet50 المدربة مسبقاً لاستخراج الخصائص البصرية (Feature Extraction) من الصور بكفاءة عالية.
فك التشفير (Decoder): قمت ببناء Transformer Decoder مخصص من الصفر (وليس LSTM التقليدية)، يعتمد على طبقات الانتباه متعددة الرؤوس (Multi-Head Attention) وآلية Causal Self-Attention لفهم السياق بين الكلمات والصورة.
مراحل التنفيذ:
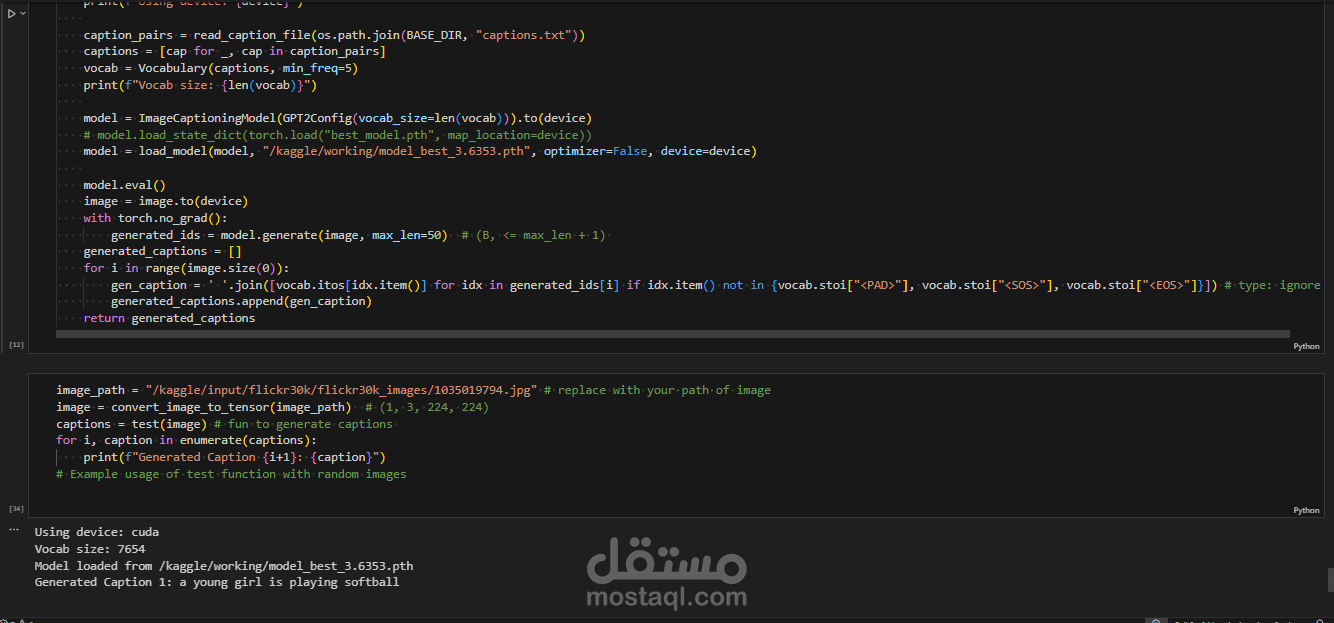
تجهيز البيانات: استخدام قاعدة بيانات Flickr30k، وبناء Vocabulary مخصص، ومعالجة النصوص (Tokenization) والصور (Normalization & Resizing).
التدريب (Training): تدريب النموذج باستخدام مُحسّن AdamW وجدولة معدل التعلم (Cosine Annealing LR) لضمان استقرار التدريب وتقليل نسبة الخطأ (Loss).
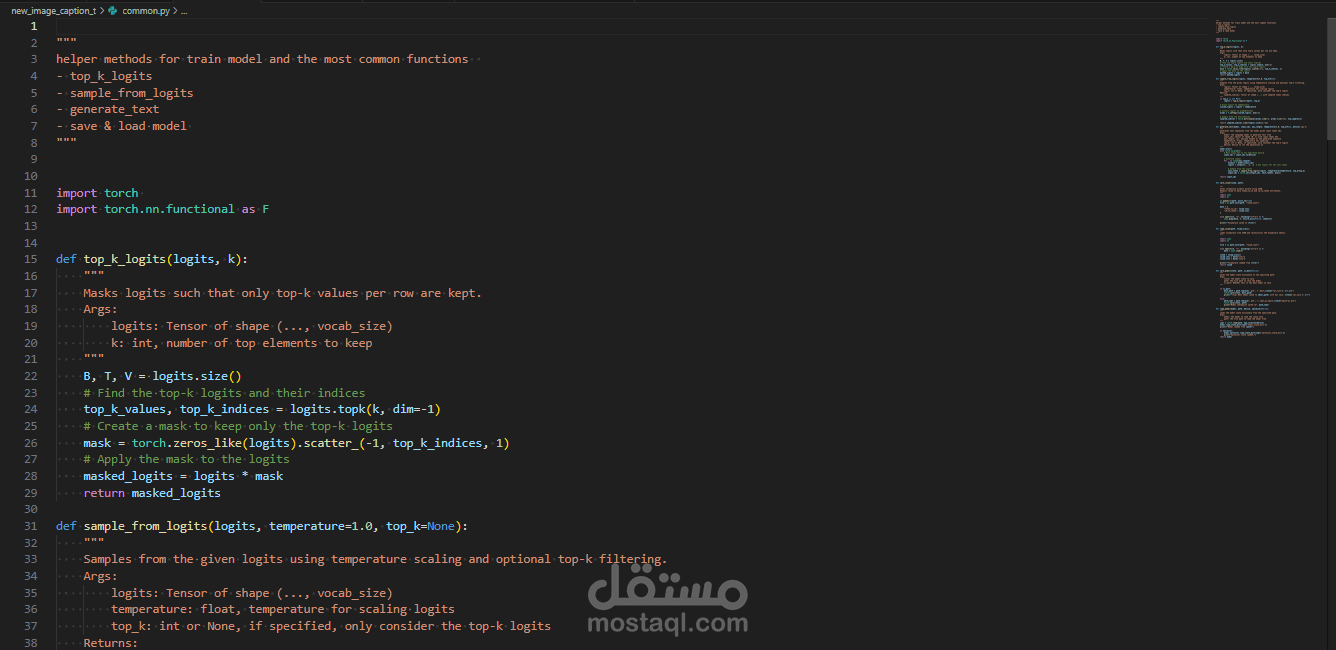
التوليد (Generation): تطبيق خوارزميات Top-k Sampling لضمان توليد جمل طبيعية ومتنوعة وغير مكررة.
التقنيات والأدوات المستخدمة:
الإطار البرمجي: PyTorch (Torch, Torchvision).
الشبكات العصبية: ResNet50, Transformers (Custom Implementation).
المكتبات المساعدة: PIL, NumPy, Regex.
النتيجة النهائية: نموذج قادر على استلام أي صورة جديدة وتوليد وصف نصي دقيق لها باللغة الإنجليزية، مع كود مصدري منظم (Clean Code) وقابل لإعادة الاستخدام.
مرفق صور توضح دقة النموذج في وصف عينات من صور الاختبار.