stroke prediction model
تفاصيل العمل
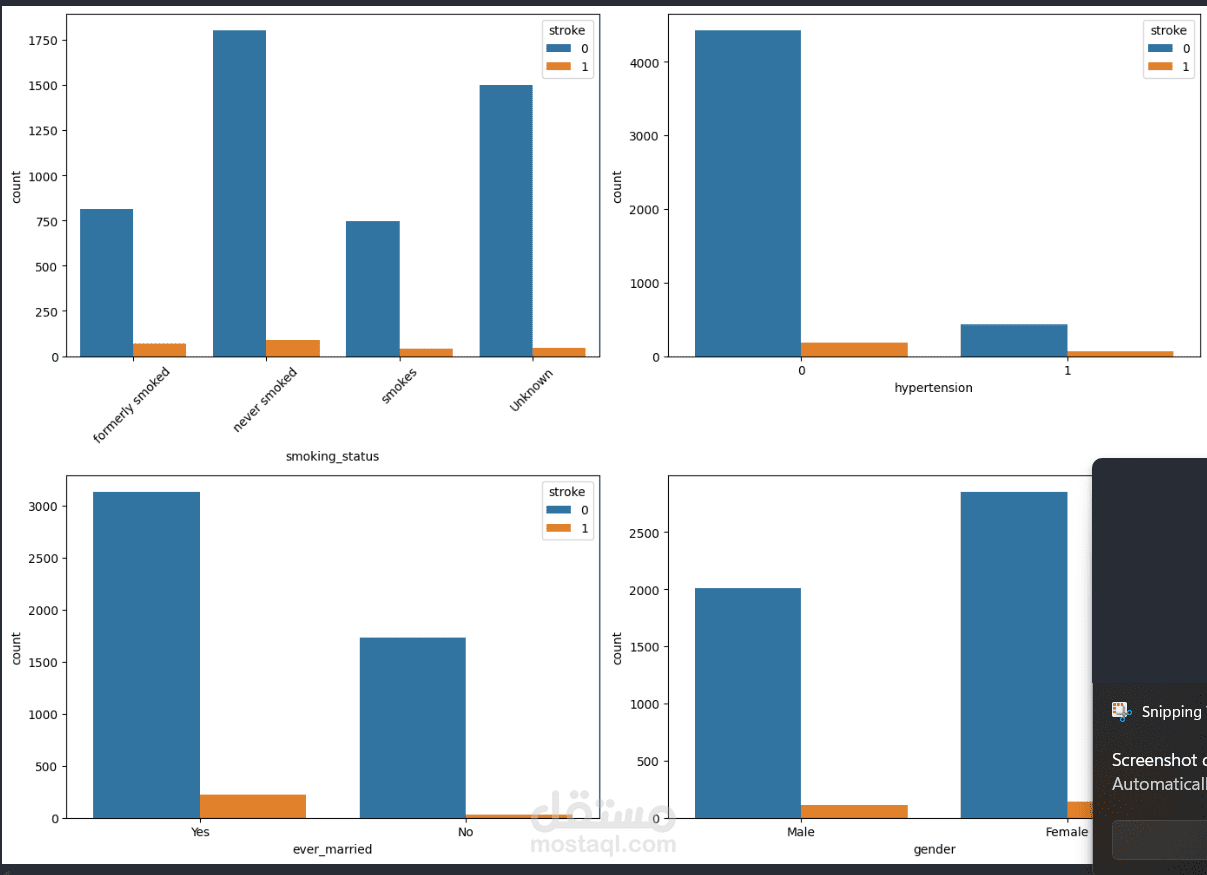
Project Overview — Stroke Prediction Data Analysis & Preprocessing
This project focuses on analyzing and preparing a healthcare dataset used to predict the likelihood of stroke based on patient medical attributes. The dataset contains demographic, lifestyle, and clinical features such as age, gender, hypertension, heart disease, average glucose level, BMI, work type, and smoking status.
Objectives
Understand key patterns and risk factors associated with strokes.
Perform full exploratory data analysis (EDA) to identify trends and correlations.
Clean, preprocess, and encode the dataset to make it ready for machine learning models.
Key Data Processing Steps
Data Cleaning:
Removed invalid gender entries (e.g., “Other”).
Converted BMI values from string to numeric and replaced missing values with the mean.
Exploratory Data Analysis (EDA):
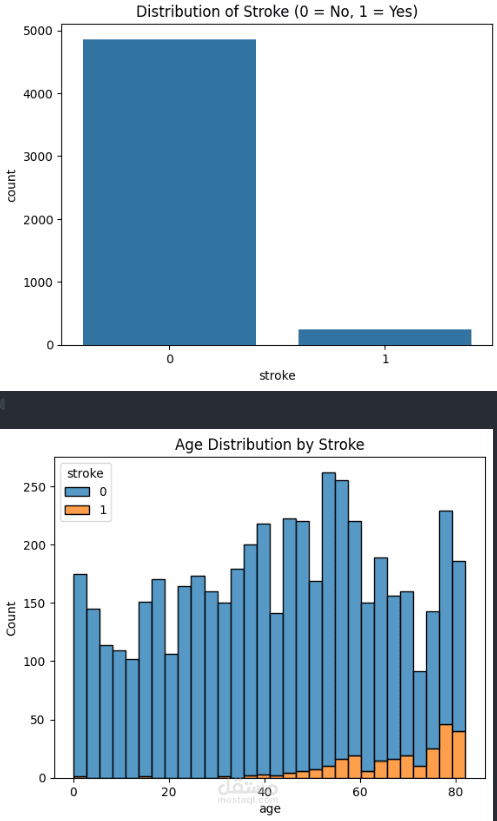
Visualized the distribution of stroke cases.
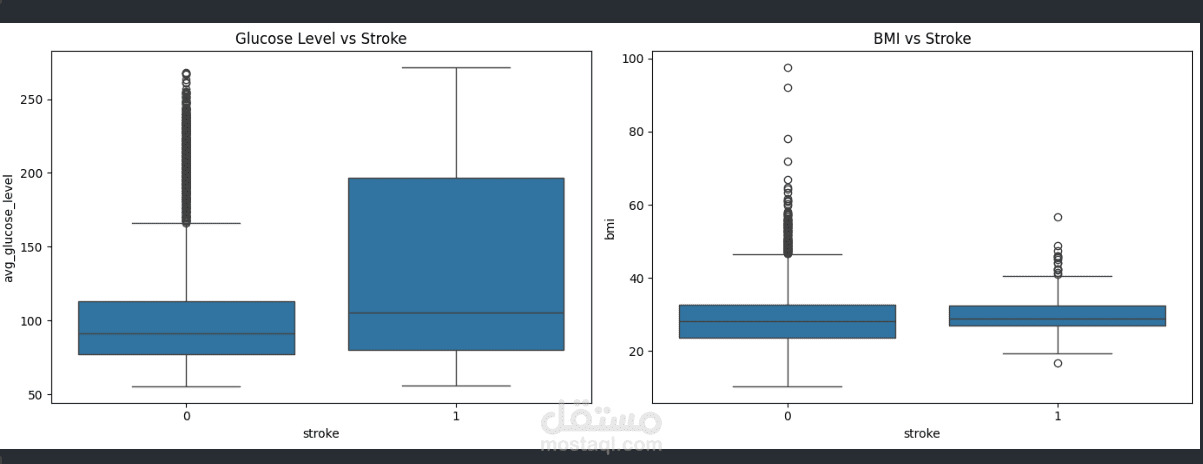
Analyzed how age, BMI, and glucose levels differ for stroke vs. non-stroke patients.
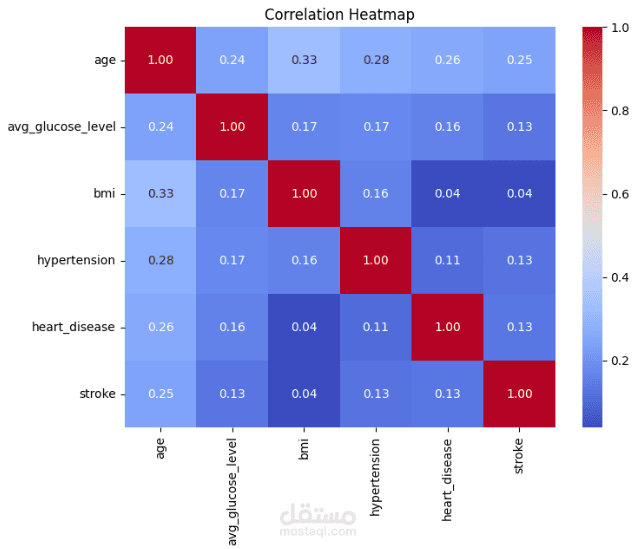
Created correlation heatmaps to identify strong relationships between numerical features.
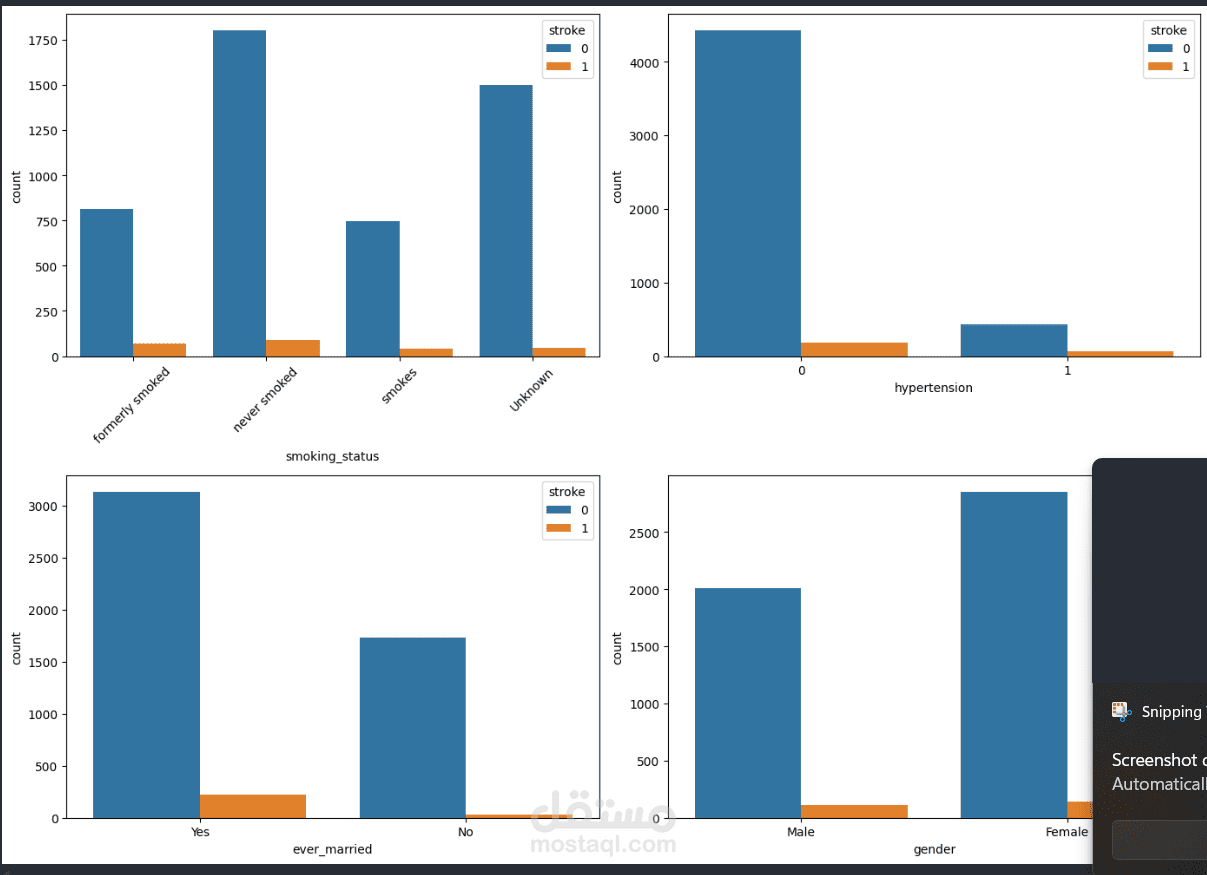
Examined categorical risk factors such as smoking status, gender, hypertension, and marriage status.
Data Encoding & Scaling:
Applied One-Hot Encoding to all categorical variables.
Standardized numerical features (age, glucose level, BMI) using StandardScaler.
Train-Test Split:
Prepared final model-ready training and testing datasets and ensured balanced splitting using stratification.
Results
The final cleaned and preprocessed dataset is suitable for training powerful machine learning models (such as Random Forest, Logistic Regression, SVM) to predict stroke risk with high reliability.