income prediction model
تفاصيل العمل
Project Dataset Overview & Processing Summary
This project uses a structured dataset containing both numerical and categorical features related to the target prediction task. Before model training, several data-quality and preprocessing steps were applied to ensure the dataset was clean, consistent, and ready for machine-learning modeling.
1. Data Understanding
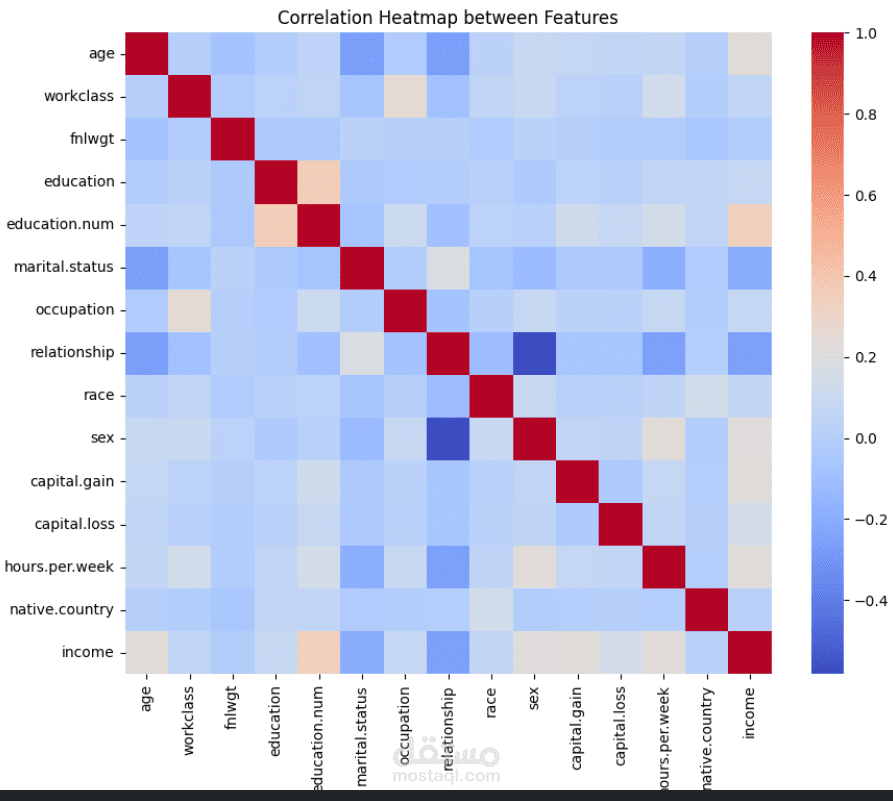
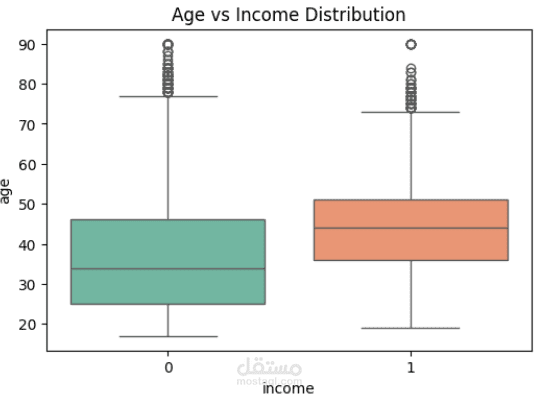
The dataset includes multiple features representing different attributes of the problem domain (e.g., demographic details, measurements, or categorical characteristics depending on the project).
The target column was prepared for supervised learning using classification.
Data exploration showed the presence of missing values, inconsistent categories, and varying data scales.
2. Data Cleaning
Handled missing values using appropriate techniques (either removal or imputation depending on the column type).
Corrected inconsistent categories (e.g., lowercase/uppercase mismatches, typos).
Removed duplicates to improve training accuracy and reduce model noise.
3. Feature Engineering
Label Encoding:
All categorical columns were encoded using LabelEncoder.
Each encoder was saved as a .pkl file for deployment to ensure consistent encoding during inference.
Feature Selection:
The most relevant features were kept to improve model efficiency and avoid overfitting.
4. Model Training
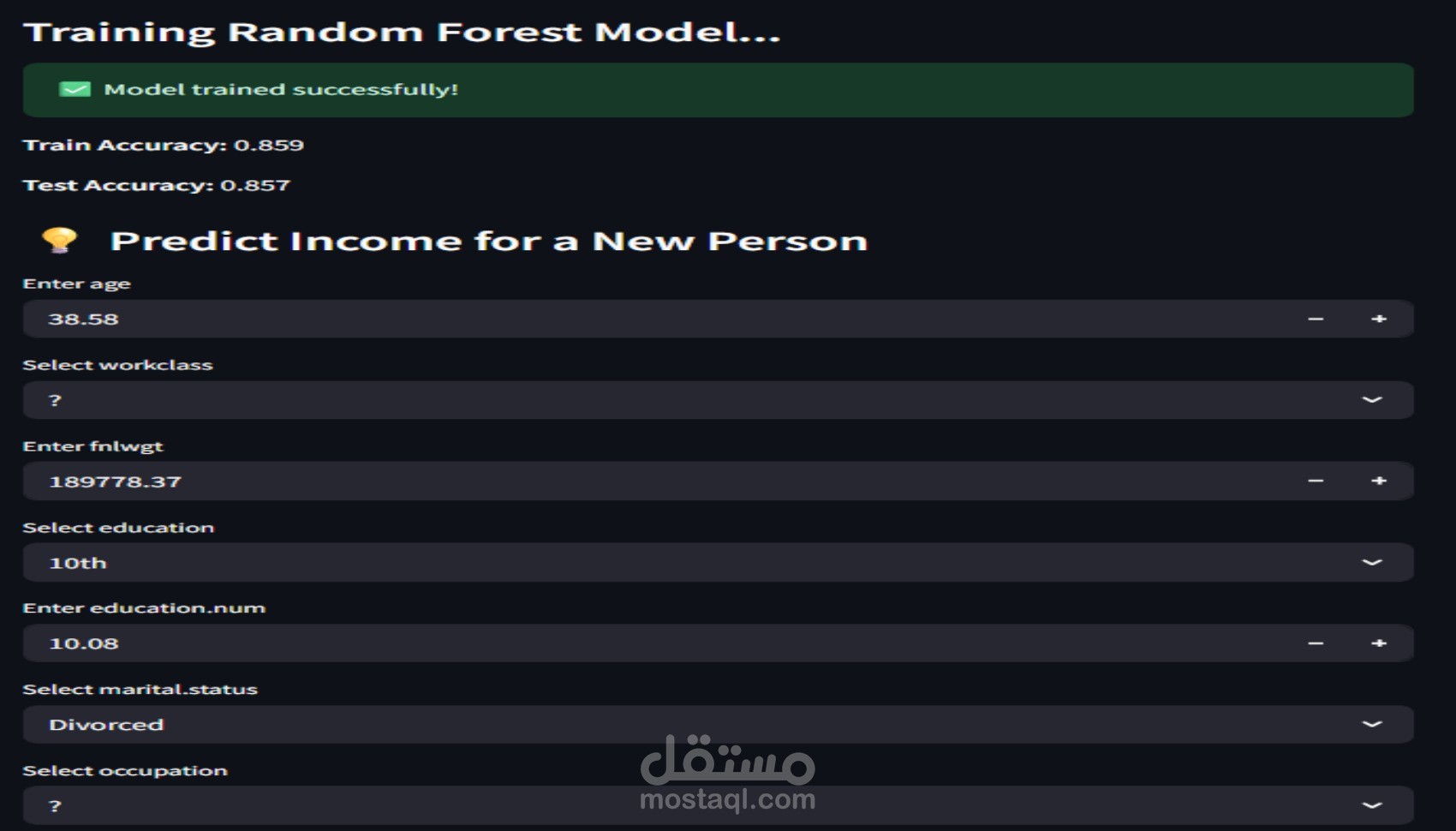
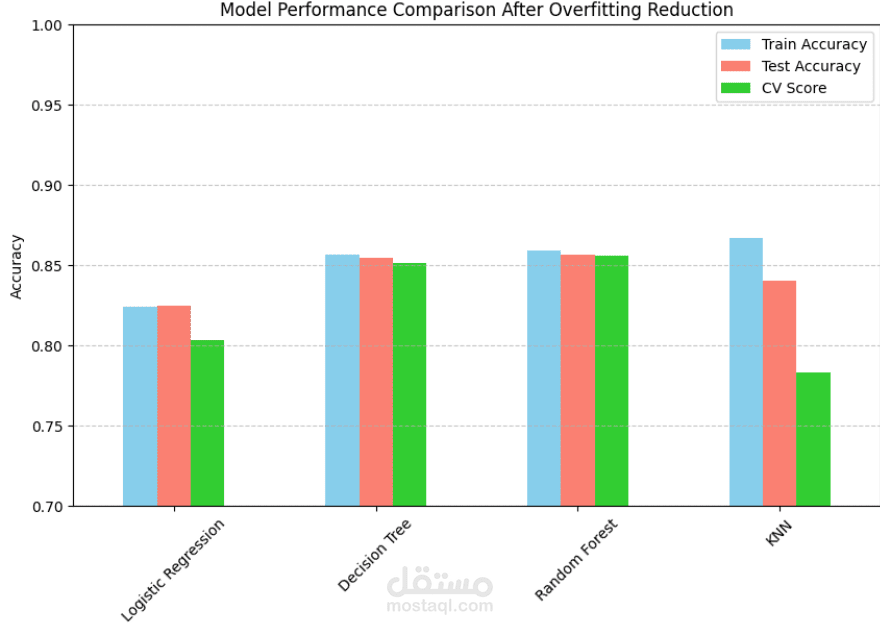
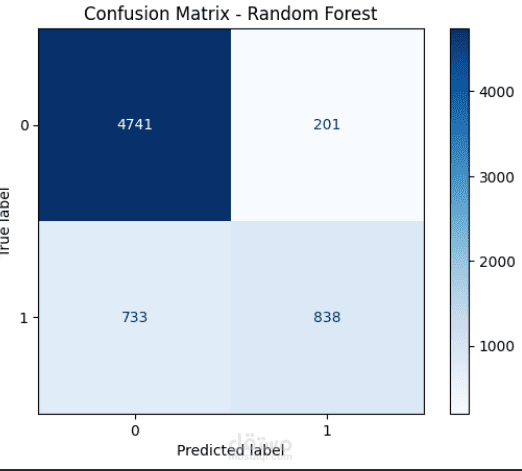
A Random Forest Classifier was trained on the processed dataset.
The model was tuned to improve accuracy and generalization.
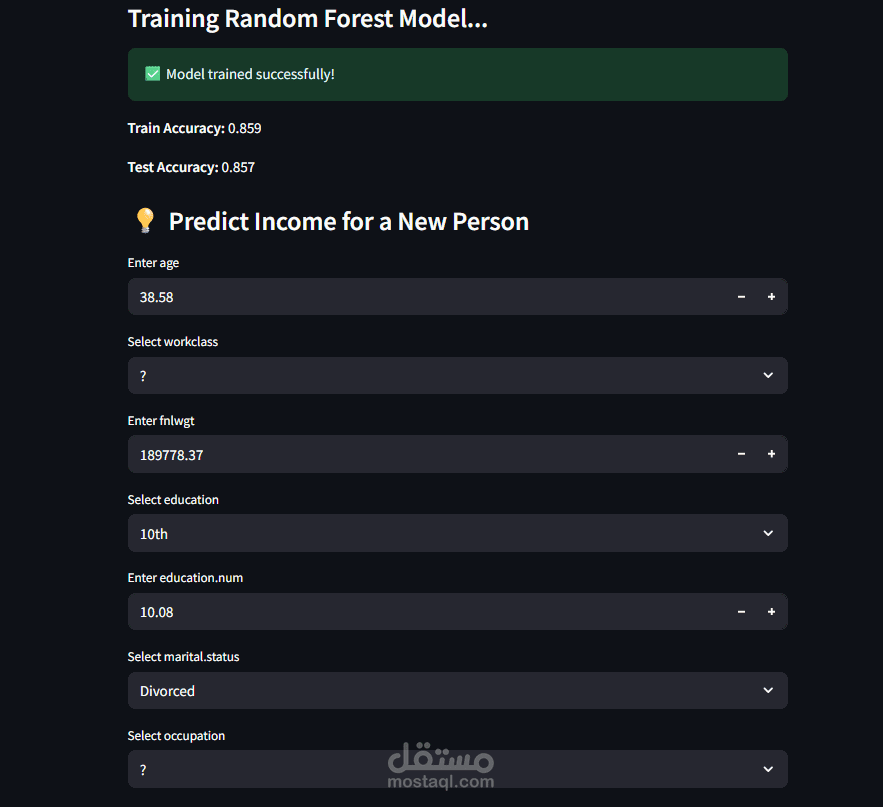
After training, the final model was exported as a .pkl file to be used in the Streamlit deployment.
5. Deployment Preparation
Both the LabelEncoder objects and the Random Forest model were saved as separate .pkl files.
The Streamlit app loads these .pkl files to perform:
Encoding of user input
Prediction using the trained model
Display of results in real time
6. Final Output
The deployed application provides instant predictions based on user inputs, ensuring a smooth experience backed by a fully processed and well-trained machine-learning pipeline.