collect data and preprocessing
تفاصيل العمل
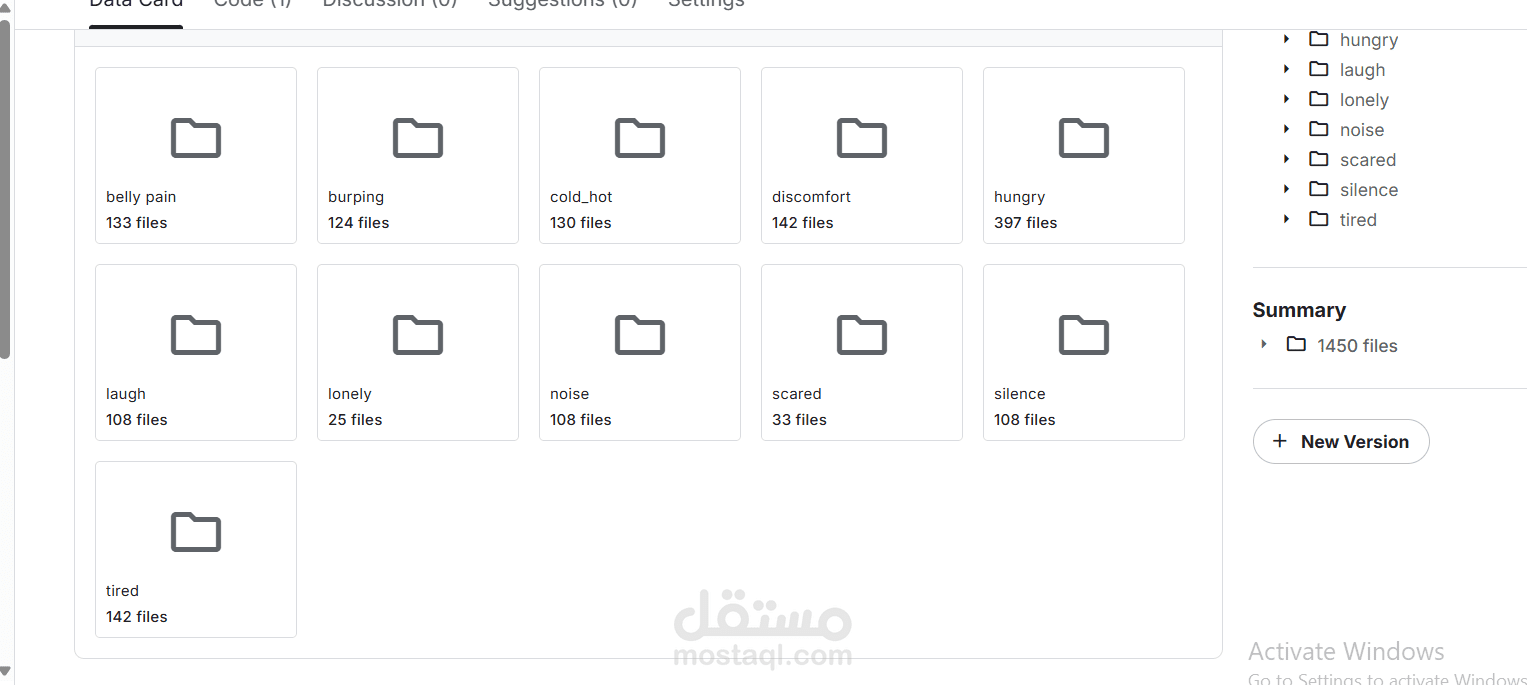
The "Baby Cry Sense" dataset emerges as a groundbreaking and meticulously curated resource, poised to revolutionize research in infant cry analysis by unlocking new frontiers in understanding neonatal needs through artificial intelligence. This dataset comprises 512 audio samples, thoughtfully compiled from open-access sources on Kaggle and GitHub, capturing authentic recordings of infant cries in their natural environments. The samples are precisely categorized into eight distinct classes representing various reasons for crying, including belly pain (16 files), burping (18 files), cold or hot conditions (7 files), discomfort (30 files), hunger (382 files), loneliness (11 files), fear (20 files), and tiredness (28 files). The dataset’s diversity, spanning a wide range of everyday scenarios for infants, lends it exceptional value for training deep learning models. Recorded in high-quality WAV format, it preserves the intricate audio details essential for signal analysis. This richness and precision position the dataset as a vital tool for developing intelligent systems capable of accurately interpreting infants’ emotional and physiological needs, thereby enhancing the role of technology in maternal care.