Loan Approval Prediction System
تفاصيل العمل
كان الهدف من المشروع مش بس بناء نموذج تعلم آلي، لكن كمان التعامل مع تحديات البيانات الحقيقية—وأهمها عدم توازن الفئات.
استخدمت SMOTENC لأنه مناسب للبيانات اللي بتجمع بين خصائص رقمية وتصنيفية، زي بيانات القروض اللي اشتغلت عليها.
علشان أطبّقه بشكل صحيح، صممت بايبلاين معالجة من 3 مراحل:
قبل SMOTE: استخدمت RobustScaler للخصائص الرقمية وOrdinalEncoder للتصنيفية علشان تجهيز البيانات قبل توليد العينات.
SMOTENC: موازنة البيانات بإنشاء عينات صناعية بدون الإخلال بالمتغيرات التصنيفية.
بعد SMOTE: تطبيق التحويلات الخاصة بالنمذجة—الاحتفاظ بالخصائص الرقمية المقيّسة وتطبيق OneHotEncoder على التصنيفية.
النهج ده سمح لي أعالج عدم توازن البيانات بدون ما أشوّه القيم التصنيفية—وده خطأ شائع بيحصل مع معظم طرق oversampling.
بعد مقارنة عدة نماذج (Logistic Regression، Decision Tree، Naive Bayes، Random Forest)، تفوّق Random Forest بدقة 98% وF1-score 0.98.
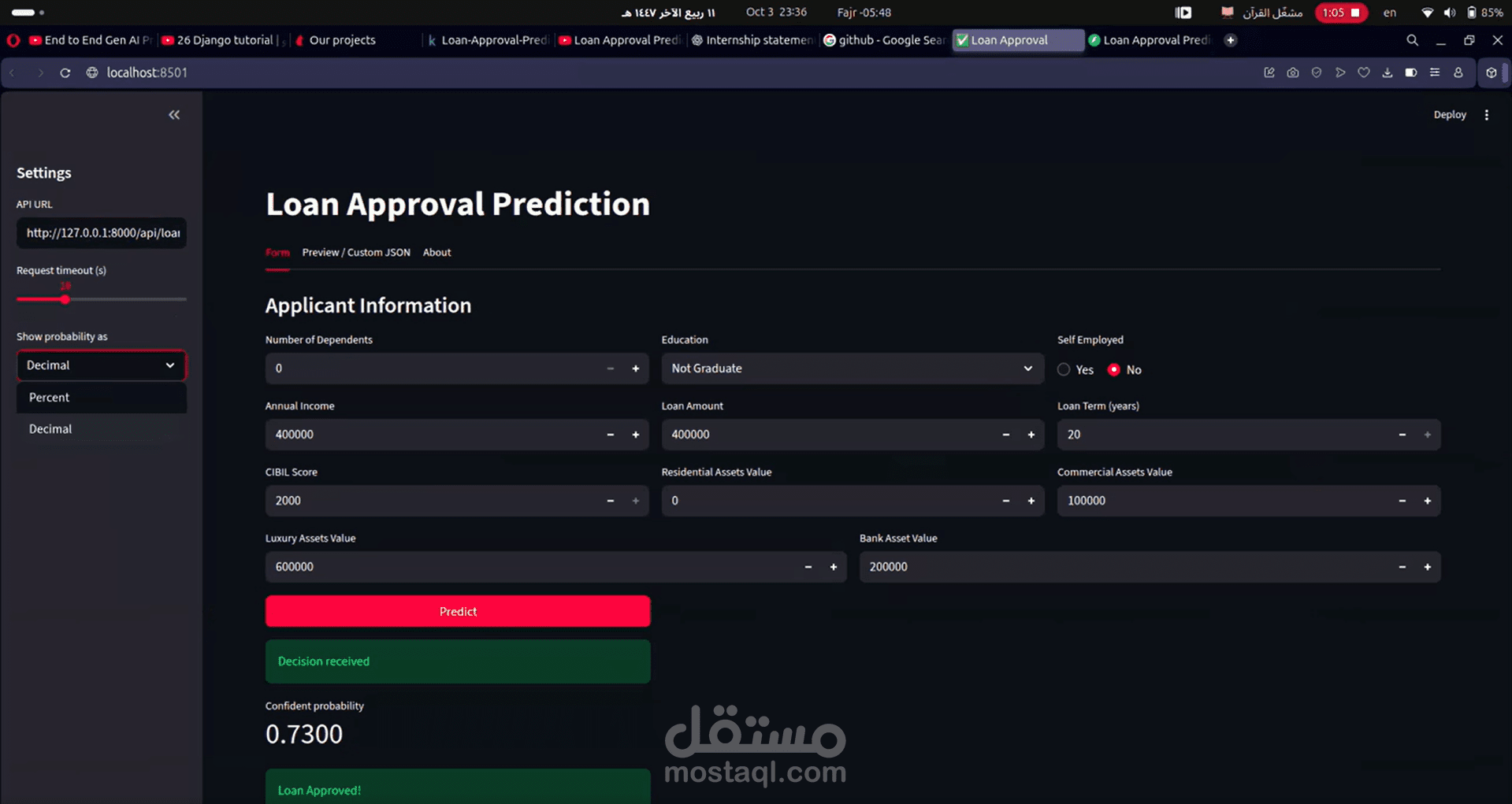
ولجعل المشروع عملي، بنيت FastAPI backend لتقديم التوقعات، وواجهة Streamlit علشان المستخدم يدخل بيانات المتقدّم ويشوف قرار القرض مباشرة.
المشروع ده أضاف لي خبرة قوية في التعامل مع البيانات غير المتوازنة باستخدام SMOTENC، وتصميم بايبلاينات معالجة قبل وبعد إعادة أخذ العينات، وبناء نماذج دقيقة وقابلة للتفسير.
لو عندك أي أسئلة عن خطوات المعالجة أو النماذج، يسعدني جداً النقاش!