حل المتاهات باستخدام خوارزمية Q-Learning وتعلم التعزيز
تفاصيل العمل



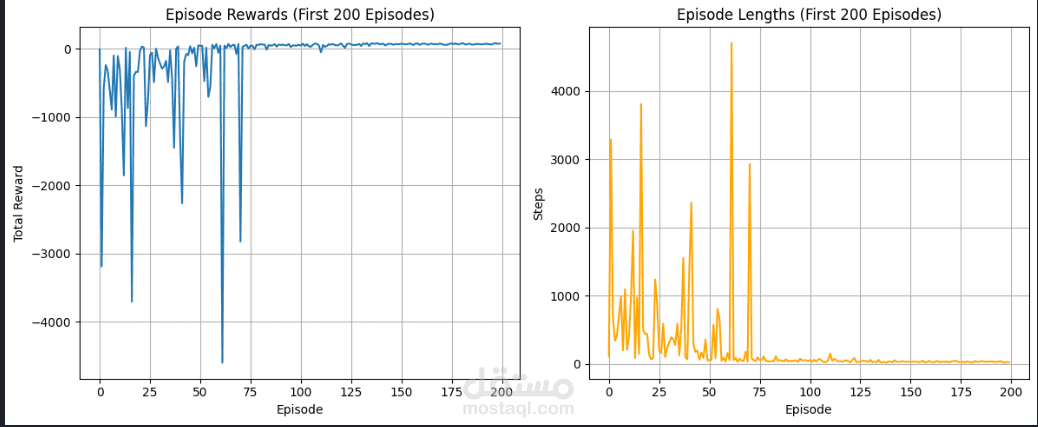
قمت بتطوير وكيل (Agent) يعتمد على خوارزمية Q-Learning لحل متاهات بحجم 11×11 يتم توليدها بشكل عشوائي في كل تشغيل.
يعمل النظام على تعلم المسار الأمثل للوصول إلى الهدف رغم ندرة المكافآت (Sparse Rewards)، وذلك عبر:
بناء بيئة متاهة تُنشأ تلقائيًا (Procedurally Generated Mazes)
تطبيق خوارزمية Q-Learning مع مصفوفة Q-Table لتحديث القيم
ضبط الهايبر بارامترز مثل: معدل التعلم، معدل الخصم، عدد الحلقات
تنفيذ استراتيجية الاستكشاف Epsilon-Greedy لتحقيق توازن بين التجربة والاستغلال
تتبع تطوّر أداء الوكيل وتحسينه عبر العديد من الحلقات التدريبية
تصوير عملية التعلّم والانتقال داخل المتاهة في الزمن الحقيقي باستخدام Pygame
هذا المشروع يُظهر مهاراتي في بناء بيئات Reinforcement Learning، وضبط النموذج، وفهم آليات اتخاذ القرار المعتمدة على المكافآت.