مشروع تحليل المشاعر من تقييمات الأفلام
تفاصيل العمل
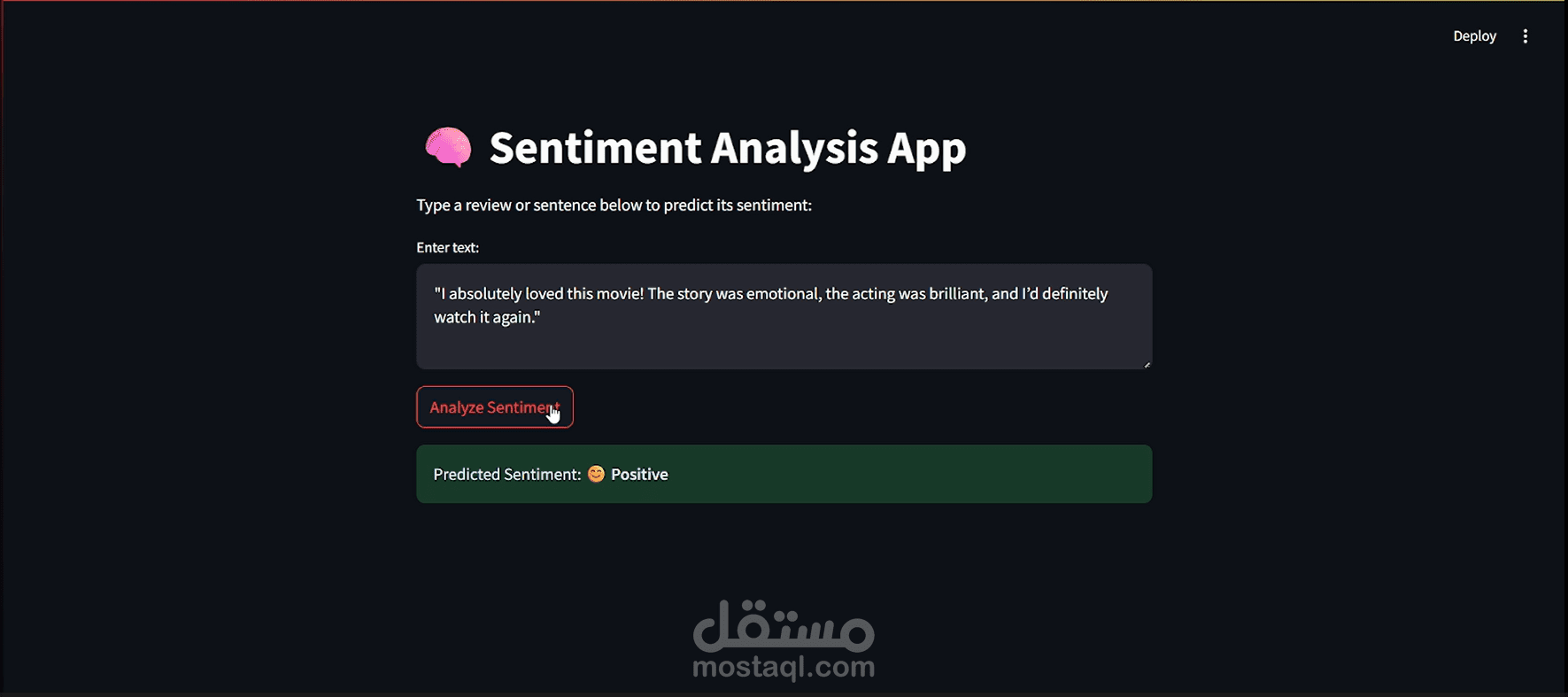
نظرة عامة على المشروعهذا المشروع عبارة عن نموذج ذكاء اصطناعي لتحليل المشاعر (Sentiment Analysis) يقوم بتصنيف تقييمات الأفلام تلقائياً إلى إيجابية أو سلبية. تم تدريب النموذج على قاعدة بيانات IMDB الشهيرة التي تحتوي على 50,000 تقييم حقيقي من مستخدمين، مما يجعله قادراً على فهم وتحليل آراء المستخدمين بدقة عالية. الهدف من المشروعتطوير نظام ذكي قادر على:
قراءة وفهم التقييمات النصية المكتوبة بالإنجليزية
تحليل المشاعر واستخراج الرأي العام (إيجابي/سلبي)
التصنيف التلقائي للمراجعات الجديدة بدقة تصل إلى 86.5%
توفير الوقت والجهد في تحليل آلاف التقييمات يدوياً
البيانات المستخدمةمصدر البيانات
القاعدة: IMDB Dataset
حجم البيانات: 50,000 تقييم
التوزيع: متوازن تماماً (25,000 إيجابي + 25,000 سلبي)
اللغة: الإنجليزية
خصائص البيانات
تقييمات حقيقية من مستخدمين فعليين
تغطي مختلف أنواع الأفلام والآراء
تحتوي على نصوص بأطوال متفاوتة
متنوعة في أسلوب الكتابة والتعبير
المراحل التقنية للمشروعالمرحلة الأولى: تنظيف وتحضير البيانات1. إزالة HTML Tags
التقييمات كانت تحتوي على علامات HTML مثل <br /> و <p>، تم إزالتها بالكامل للحصول على نص نظيف.2. توحيد الحروف
تحويل جميع الحروف إلى صغيرة (lowercase) لتجنب التكرار في التحليل.3. إزالة الرموز الخاصة
حذف جميع علامات الترقيم والرموز الخاصة والاحتفاظ فقط بالحروف والأرقام.4. النتيجة
نصوص نظيفة وجاهزة للمعالجة، مثال:
قبل: "A wonderful little production. <br /><br />The..."
بعد: "a wonderful little production the filming technique"
المرحلة الثانية: تحويل النصوص إلى أرقام (Feature Extraction)استخدام تقنية TF-IDFTF-IDF تعني (Term Frequency - Inverse Document Frequency)، وهي تقنية متقدمة لتحويل النصوص إلى أرقام بطريقة ذكية:إعدادات TF-IDF المستخدمة:
max_features=10000: استخدام أهم 10,000 كلمة فقط
ngram_range=(1,2): تحليل الكلمات المفردة والمزدوجة
stop_words='english': إزالة الكلمات الشائعة مثل (the, is, are)
min_df=5: تجاهل الكلمات النادرة جداً
max_df=0.8: تجاهل الكلمات الشائعة جداً
لماذا TF-IDF أفضل من الطرق التقليدية؟
تعطي وزن أكبر للكلمات المميزة
تقلل تأثير الكلمات الشائعة التي لا تحمل معنى
تحافظ على السياق من خلال Bigrams
تنتج تمثيل رقمي دقيق للنصوص
المرحلة الثالثة: تقسيم البياناتتم تقسيم البيانات إلى:
80% للتدريب (40,000 تقييم): لتعليم النموذج
20% للاختبار (10,000 تقييم): لتقييم الأداء
stratify=y: للحفاظ على التوازن بين الفئات
المرحلة الرابعة: بناء وتدريب النموذجاختيار خوارزمية Multinomial Naive Bayesلماذا هذه الخوارزمية؟
سريعة جداً في التدريب والتنبؤ
فعالة مع البيانات النصية الكبيرة
دقة عالية في تصنيف النصوص
بسيطة وسهلة الفهم والتطبيق
لا تحتاج موارد ضخمة للتشغيل
كيف تعمل؟
تعتمد على نظرية الاحتمالات (Bayes Theorem)
تحسب احتمال كل كلمة في كل فئة
تتنبأ بالفئة الأكثر احتمالاً بناءً على الكلمات الموجودة
نتائج الأداءالمقاييس الرئيسية1. الدقة الإجمالية (Accuracy)
86.53% - نسبة التنبؤات الصحيحة من إجمالي التنبؤات2. تفاصيل الأداء لكل فئةالتقييمات السلبية (Negative):
Precision: 88% - من كل 100 تقييم تنبأ النموذج أنه سلبي، 88 كانوا فعلاً سلبيين
Recall: 85% - من كل 100 تقييم سلبي حقيقي، النموذج اكتشف 85 منهم
F1-Score: 86% - المتوسط الموزون بين Precision و Recall
التقييمات الإيجابية (Positive):
Precision: 85% - من كل 100 تقييم تنبأ النموذج أنه إيجابي، 85 كانوا فعلاً إيجابيين
Recall: 88% - من كل 100 تقييم إيجابي حقيقي، النموذج اكتشف 88 منهم
F1-Score: 87% - المتوسط الموزون بين Precision و Recall