تنظيف البيانات (Data Cleaning Project)
تفاصيل العمل







هذا المشروع يهدف إلى تنظيف ومعالجة البيانات الخام لتصبح جاهزة للتحليل والاستخدام في النماذج الإحصائية أو التنبؤية.
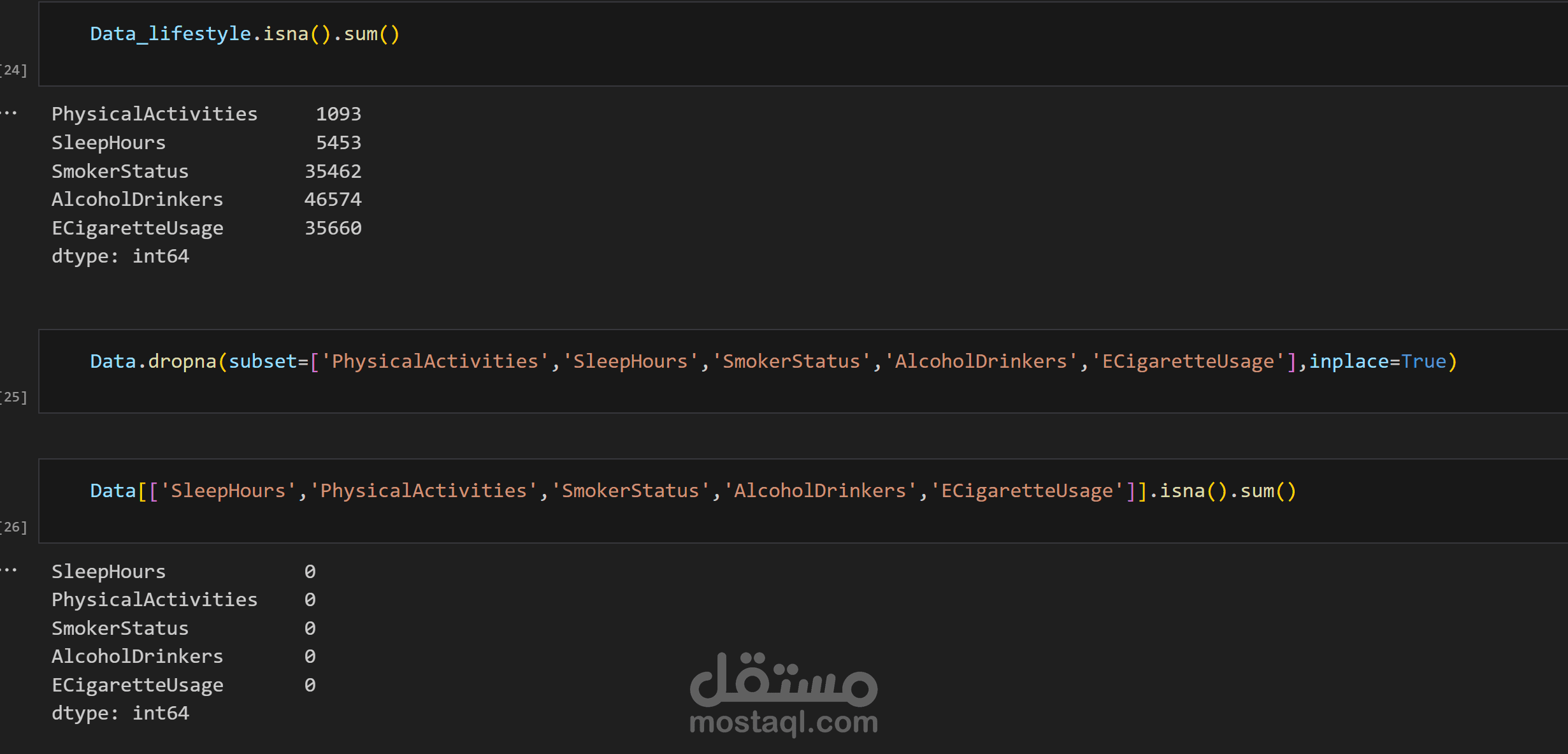
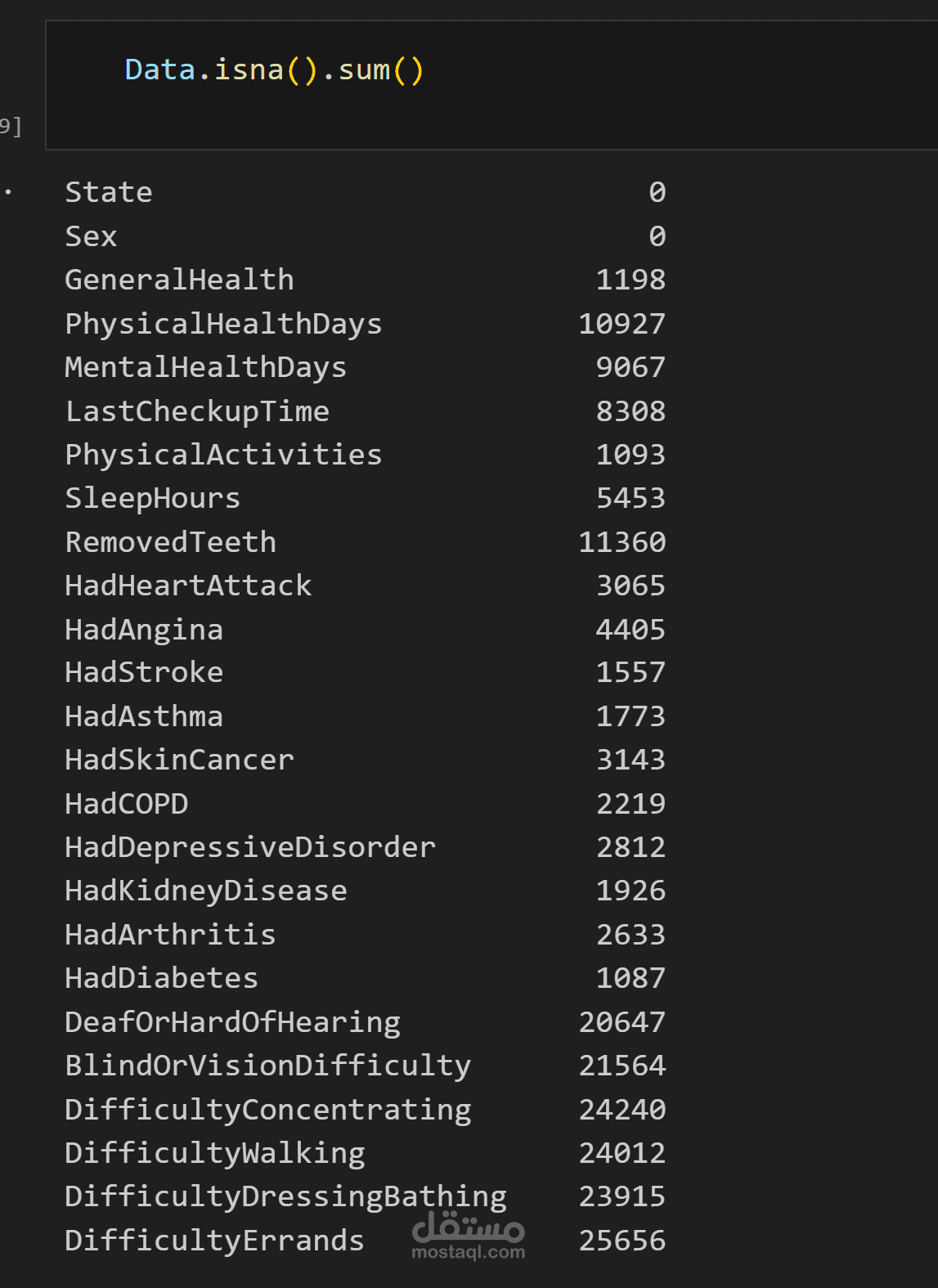
البيانات الأولية كانت تحتوي على قيم مفقودة، متكررة، وغير متسقة، وتم التعامل معها باستخدام خطوات منهجية دقيقة تضمن الحفاظ على جودة البيانات ودقتها.
خلال تنفيذ المشروع قمت بالآتي:
استكشاف البيانات (Data Exploration):
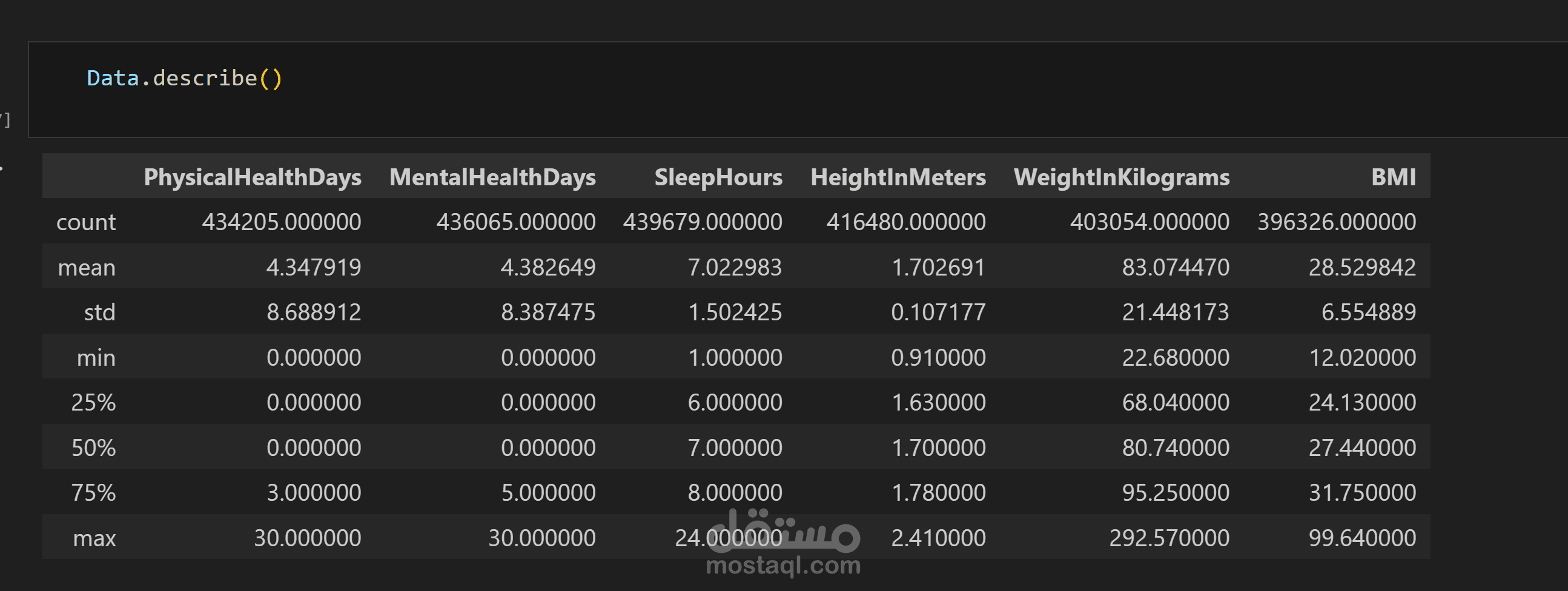
فحص حجم البيانات ونوعها وتحديد المشكلات الرئيسية (Missing Values، Duplicates، Outliers).
تحليل الإحصاءات الوصفية لكل عمود لتكوين فكرة أولية عن التوزيعات والقيم.
تنظيف ومعالجة البيانات (Data Cleaning & Preprocessing):
إزالة الصفوف أو الأعمدة غير المفيدة.
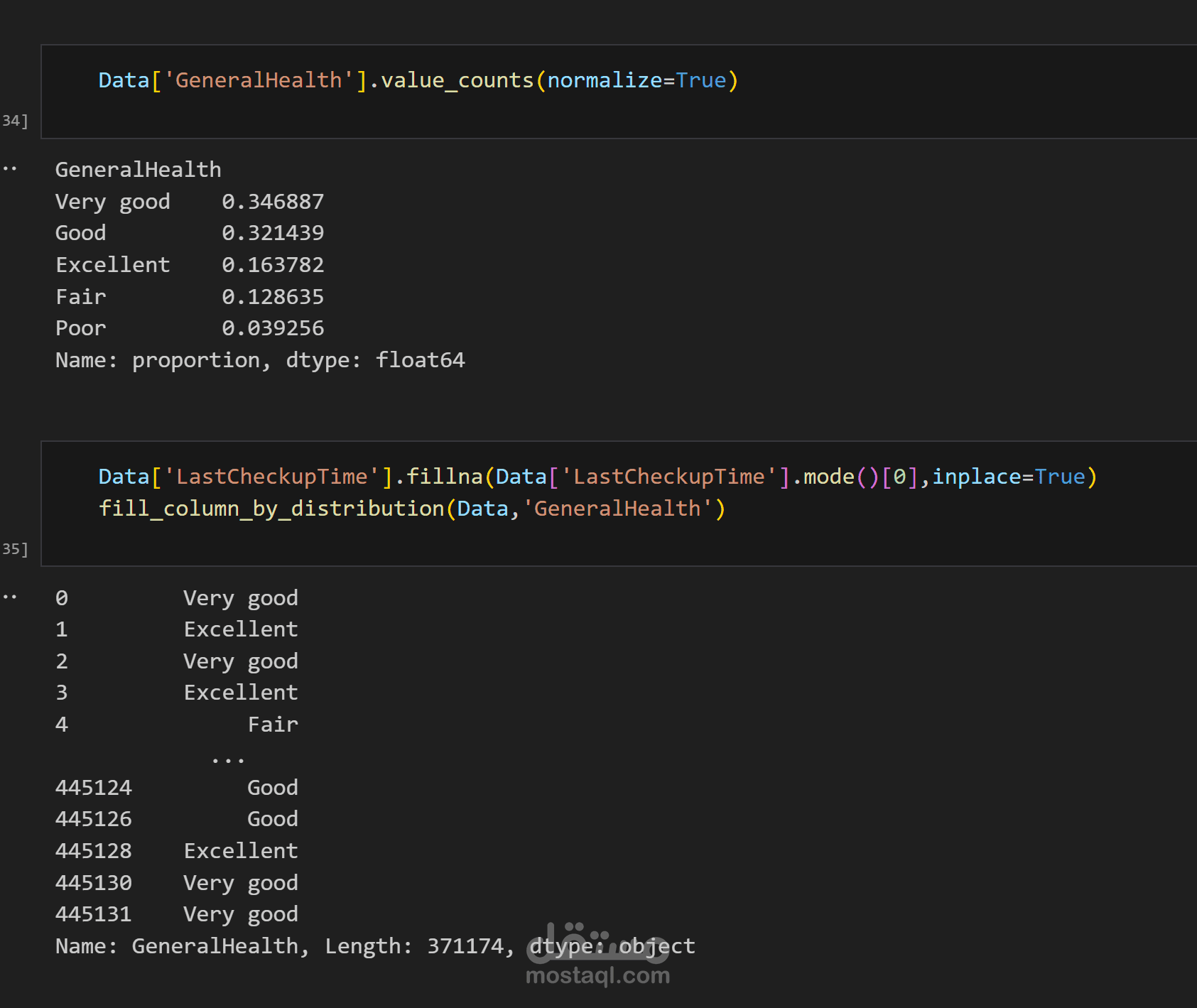
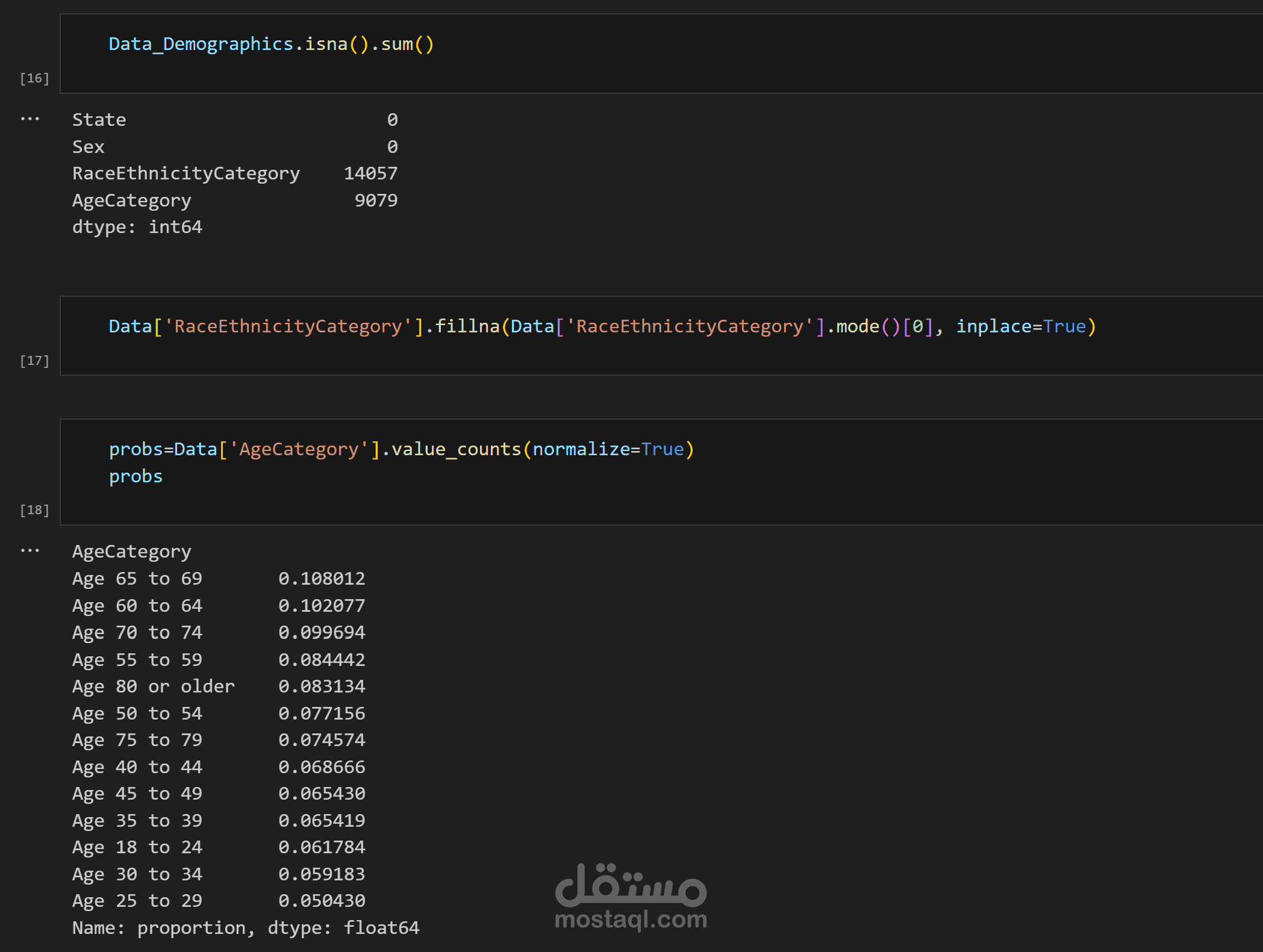
تعويض القيم المفقودة بطرق منطقية (مثل المتوسط أو الوسيط).
تنسيق الأعمدة النصية وتصحيح القيم غير المتسقة.
اكتشاف وإزالة القيم المتطرفة (Outliers).
إعادة تسمية الأعمدة وتوحيد التنسيقات لتسهيل التحليل اللاحق.
التحقق من الجودة (Quality Check):
التأكد من خلو البيانات من التكرار.
التحقق من أنواع البيانات (Data Types).
ضمان جاهزية البيانات للمرحلة التالية من التحليل أو النمذجة.
الأدوات المستخدمة:
Python (Pandas, NumPy)
Jupyter Notebook
Matplotlib / Seaborn (للتأكد بصريًا من سلامة التنظيف)