sales of electronic store
تفاصيل العمل
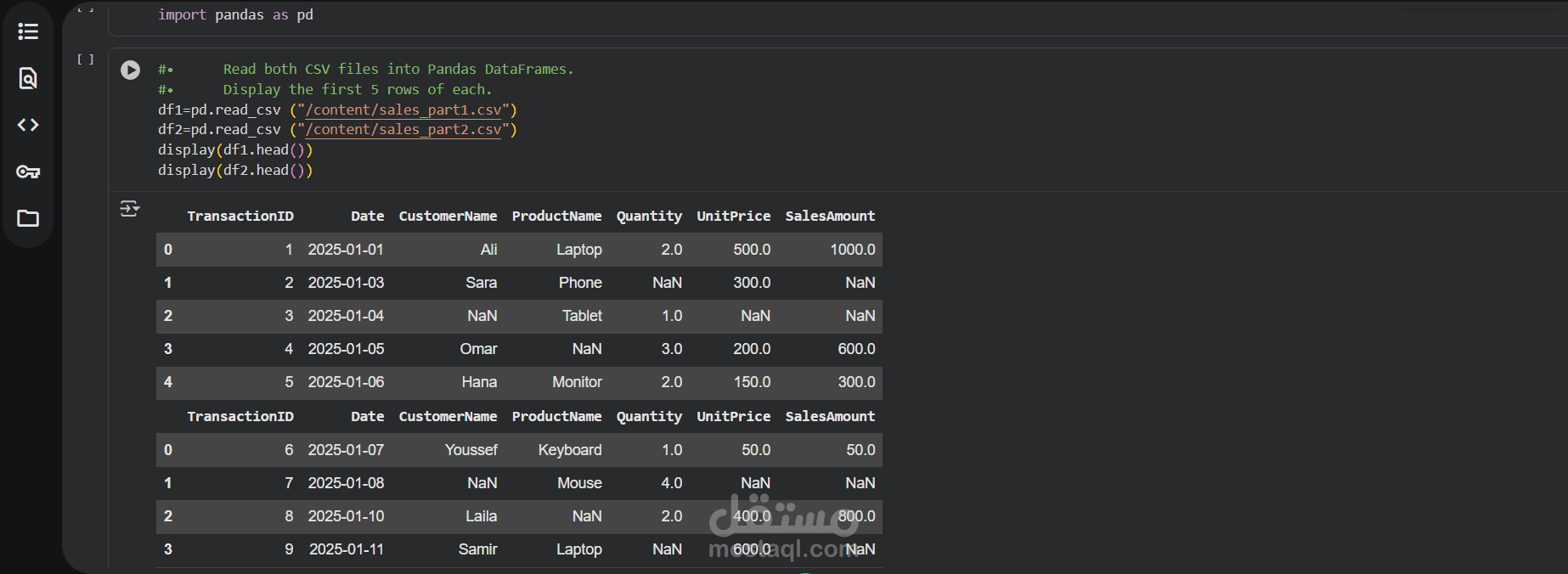
وصف مشروع تحليل بيانات المبيعات وتنظيفها باستخدام Python و Pandas
يتضمن هذا الملف الحل الكامل لـ "مهمة تحليل بيانات المبيعات"، والذي يغطي مراحل معالجة البيانات وتنظيفها وتجهيزها للاستخدامات التحليلية اللاحقة. تم استخدام لغة Python ومكتبة Pandas القوية لتنفيذ جميع الخطوات بكفاءة ودقة عالية.
️ الخطوات المنفذة في المشروع
تم تنفيذ المشروع وفقاً لخطوات منهجية لضمان جودة البيانات وسلامتها:
1. تحميل البيانات (Load Data)
قراءة ملفي بيانات المبيعات: sales_part1.csv و sales_part2.csv وتحميلهما في إطاري بيانات (DataFrames) منفصلين باستخدام مكتبة Pandas.
عرض الأسطر الخمسة الأولى من كل إطار بيانات للتحقق الأولي.
2. استكشاف البيانات (Data Exploration)
الشكل والحجم: تحديد عدد الصفوف والأعمدة لكل مجموعة بيانات. كلتا المجموعتين تحتويان على 5 صفوف و 7 أعمدة.
أنواع البيانات: فحص أنواع البيانات (dtypes) وعدد القيم غير الفارغة (Non-Null Count) لكل عمود. تم ملاحظة الأعمدة ذات القيم المفقودة في كلتا المجموعتين:
الأعمدة المفقودة (لكل ملف):
CustomerName: 1 قيمة مفقودة.
ProductName: 1 قيمة مفقودة.
Quantity: 1 قيمة مفقودة.
UnitPrice: 1 قيمة مفقودة.
SalesAmount: 2 قيم مفقودة.
الإحصائيات الوصفية: عرض الملخصات الإحصائية للبيانات الرقمية (.describe()) مثل المتوسط، الانحراف المعياري، والحد الأدنى والأقصى للتحقق من التوزيع الأولي للبيانات.
3. معالجة القيم المفقودة (Handle Missing Values)
تم معالجة القيم المفقودة باستخدام تقنيات تعبئة مخصصة لكل عمود لضمان اتساق البيانات:
الأعمدة الرقمية (Quantity, UnitPrice, SalesAmount): تم تعبئة القيم المفقودة فيها باستخدام المتوسط الحسابي (Mean) للعمود المعني.
مثال: تعبئة القيم المفقودة في عمود Quantity بـ 2.0 (المتوسط) في df1، وفي عمود UnitPrice بـ 337.5 في df2 (بعد عملية التعبئة).
العمود النصي (CustomerName): تم تعبئة القيم المفقودة بالسلسلة النصية "Unknown" (غير معروف).
العمود النصي (ProductName): تم استخدام طريقة التعبئة الأمامية (Forward Fill - ffill) لملء القيم المفقودة بأحدث قيمة صحيحة معروفة سابقة في العمود.
التحقق: تم التأكد من عدم وجود أي قيم مفقودة متبقية في أي من إطاري البيانات بعد التنظيف.
4. دمج البيانات (Merge Data)
تم دمج إطاري البيانات المنظفين (df1 و df2) عمودياً باستخدام الدالة pd.concat وتجاهل الفهرس الأصلي (ignore_index=True)، مما نتج عنه إطار البيانات المدمج والمنظف df_concat الذي يحتوي على 10 معاملات.
تم التأكد من عدم وجود تكرار في عمود TransactionID.
5. التصفية والاختيار (Filtering & Selection)
التصفية: تم تصفية مجموعة البيانات المدمجة للاحتفاظ فقط بالمعاملات التي تزيد فيها قيمة SalesAmount عن 100.
اختيار الأعمدة: تم اختيار مجموعة محددة من الأعمدة المطلوبة للتحليل النهائي: TransactionID, Date, CustomerName, ProductName, Quantity, SalesAmount لإنشاء إطار البيانات النهائي df_filtered.
6. تصدير البيانات النهائية (Export Clean Data)
تم تصدير مجموعة البيانات النظيفة والمُصفاة df_filtered إلى ملف CSV جديد باسم sales_cleaned.csv، جاهز للتحليل المتقدم.