مشروع تصنيف الفطر
تفاصيل العمل

يهدف هذا المشروع إلى تصنيف الفطر إلى فئتين: صالح للأكل (e) أو سام (p)، وذلك اعتمادًا على 20 سمة وصفية مثل شكل القبعة، لونها، خصائص الساق، البيئة، والموسم.
يُعد هذا المشروع مشكلة تصنيف ثنائية، حيث تمثل فئة الفطر المتغير المستهدف في النموذج.
مراحل تنفيذ المشروع
1. تحليل البيانات الاستكشافي (EDA)
فحص هيكل مجموعة البيانات (عدد الصفوف، الأعمدة، وأنواع البيانات).
التحقق من القيم المفقودة والمكررة.
عرض الخصائص الفئوية باستخدام الرسوم البيانية العمودية، والخصائص العددية باستخدام المدرجات التكرارية ومربعات القيم.
تحليل الارتباط بين الخصائص والفئة المستهدفة.
التحقق من توازن الفئات بين الفطر الصالح للأكل والفطر السام.
توزيع الفئات قبل وبعد تطبيق SMOTE:
2. تنظيف البيانات والمعالجة المسبقة
معالجة القيم المفقودة أو غير المعروفة.
ترميز الخصائص الفئوية باستخدام Label Encoding وOne-Hot Encoding.
تقييس الخصائص العددية باستخدام StandardScaler أو MinMaxScaler.
تطبيق تقسيم تدريبي واختباري طبقي (Stratified Train-Test Split) للحفاظ على توازن الفئات.
استخدام SMOTE لمعالجة مشكلة عدم التوازن في البيانات.
3. اختيار الخصائص المهمة (Feature Selection)
طرق الترشيح: اختبار كاي-تربيع (Chi-Square)، اختبار ANOVA F، والمعلومات المتبادلة (Mutual Information).
الطرق المغلفة: إزالة الميزات التكرارية (RFE).
الطرق المدمجة: استخراج أهمية الخصائص باستخدام شجرة القرار (Decision Tree) والغابة العشوائية (Random Forest).
الخصائص المختارة:
['stem-width', 'cap-diameter', 'ring-type_z', 'stem-surface_g', 'gill-attachment_p', ...]
4. تدريب النماذج وتقييمها
تم تدريب النماذج التالية لتصنيف الفطر:
الانحدار اللوجستي (Logistic Regression)
شجرة القرار (Decision Tree)
الغابة العشوائية (Random Forest)
آلة الدعم الناقل (SVM)
أقرب الجيران (KNN)
نايف بايز (Naive Bayes)
مقاييس التقييم:
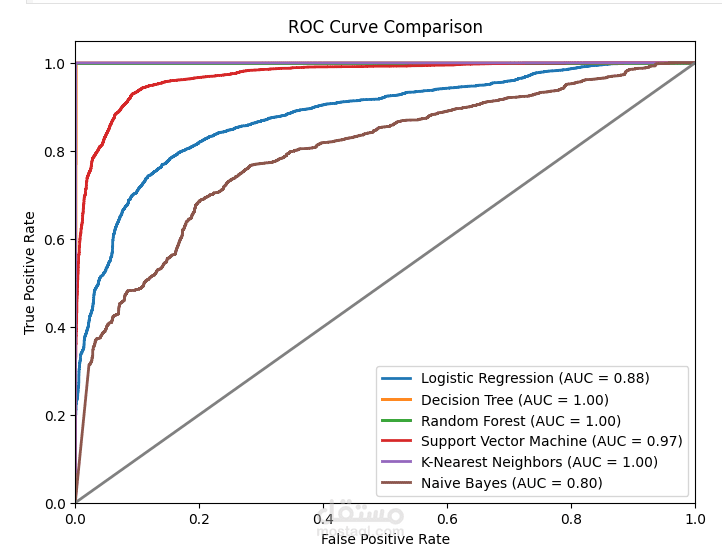
الدقة (Accuracy)، الدقة الإيجابية (Precision)، الاستدعاء (Recall)، درجة F1، مصفوفة الالتباس (Confusion Matrix)، منحنيات ROC-AUC، والتحقق المتقاطع (Cross-validation).
5. ضبط المعاملات الفائقة (Hyperparameter Tuning)
تطبيق تقنيات Grid Search وRandom Search لتحسين أداء النماذج.
مقارنة النماذج الأساسية بالنماذج المحسّنة لقياس التحسين في النتائج.
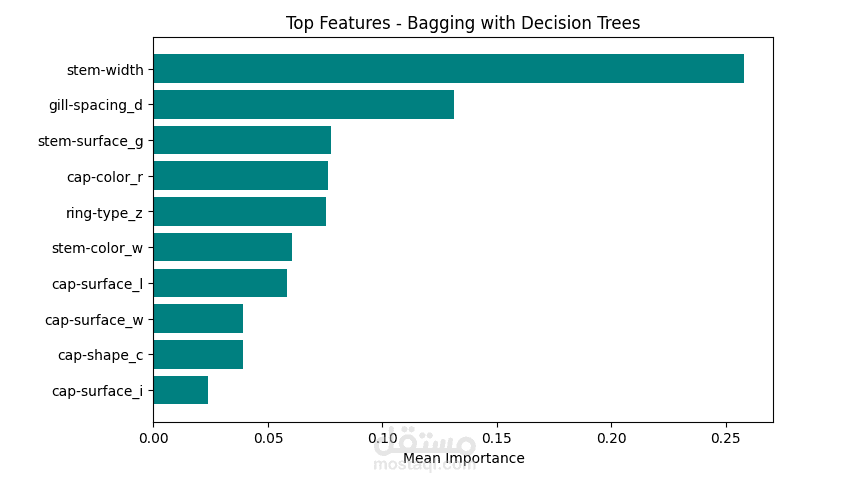
6. أهمية الخصائص (Feature Importance)
استخراج أهمية الخصائص باستخدام Decision Tree وRandom Forest.
ترتيب الخصائص الأكثر تأثيرًا في عملية التصنيف.
أفضل نموذج أداءً:
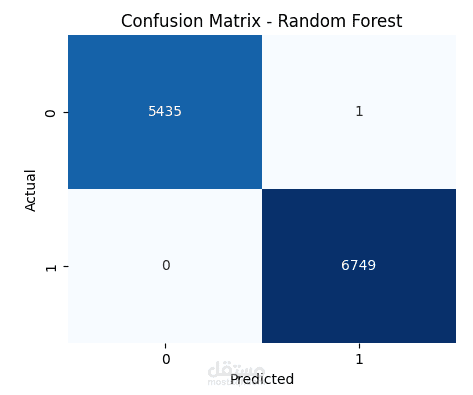
نموذج Random Forest بدقة 99.99%.
المرئيات
منحنيات ROC-AUC: عرض أداء النماذج في التمييز بين الفئات.
أهمية الخصائص: تحديد الخصائص الأكثر تأثيرًا في التنبؤ بالنتائج.
مصفوفات الالتباس: مقارنة أداء النماذج من خلال مصفوفات الالتباس.
النتائج الرئيسية
تحقيق دقة بلغت 99.99% باستخدام نموذج Random Forest.
تحديد عرض الساق وقطر القبعة كأكثر الخصائص تنبؤية.
تحقيق توازن فعّال بين الفئات باستخدام SMOTE.
بناء نظام تعلم آلي متكامل يشمل جميع المراحل من تحليل البيانات وحتى النشر.
معلومات المشروع
تم تطوير المشروع باستخدام Jupyter Notebook بالكامل.
الأدوات المستخدمة: Python، Scikit-learn، Pandas، NumPy، Matplotlib، Seaborn.
يتضمن جميع مراحل العمل من البيانات الخام حتى النتائج الجاهزة للنشر.