text extraction from a pdf
تفاصيل العمل
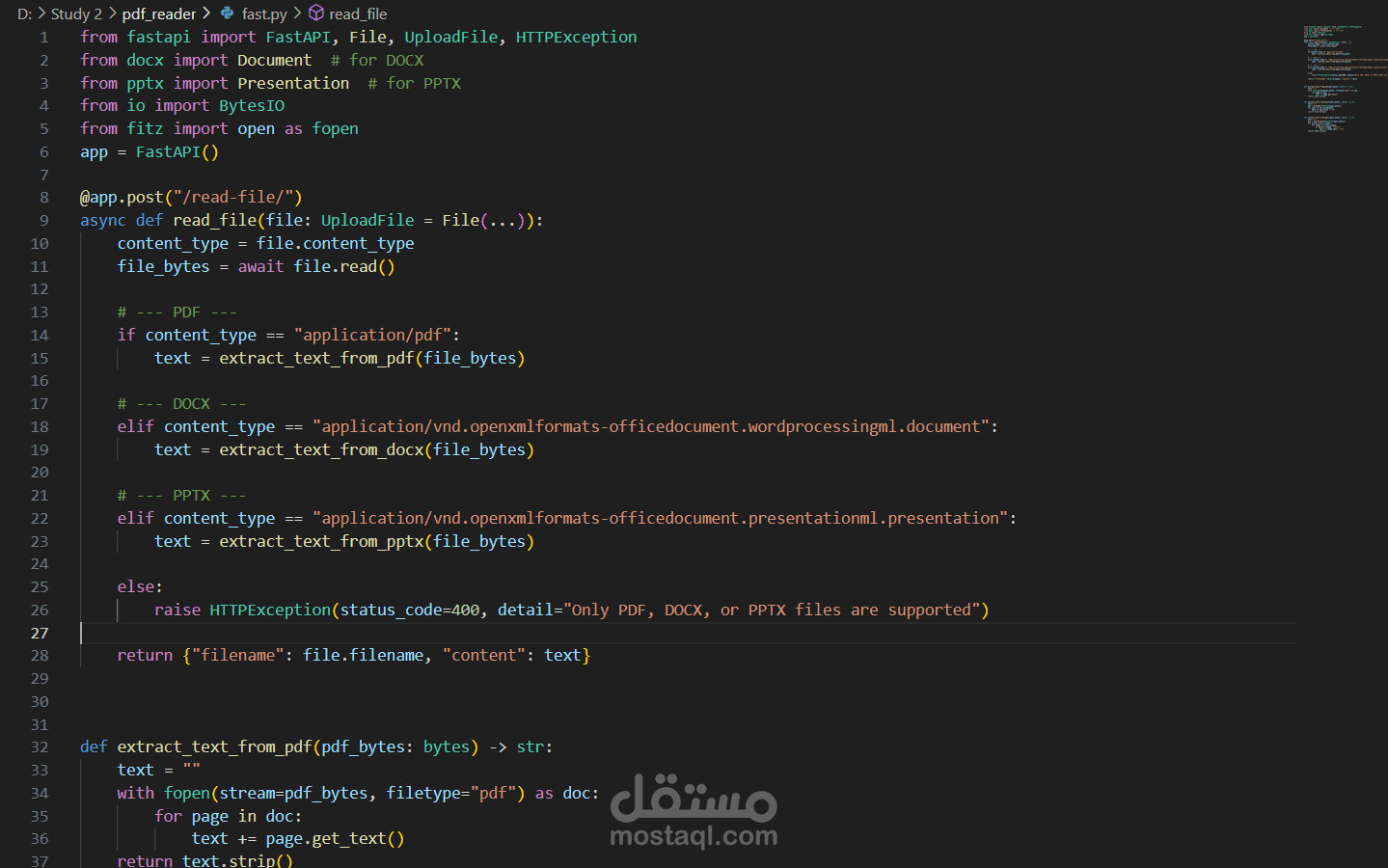
This project focuses on developing a Python-based application that extracts text content from PDF files. The system allows users to upload a PDF document, processes it using libraries like PyMuPDF (fitz) or pdfminer, and returns the extracted text in a readable format. It efficiently handles various document types — including scanned PDFs (with OCR support, if added) — and can be extended to extract specific elements such as titles, paragraphs, or tables.