منصة التحليل الذكي للصور
تفاصيل العمل
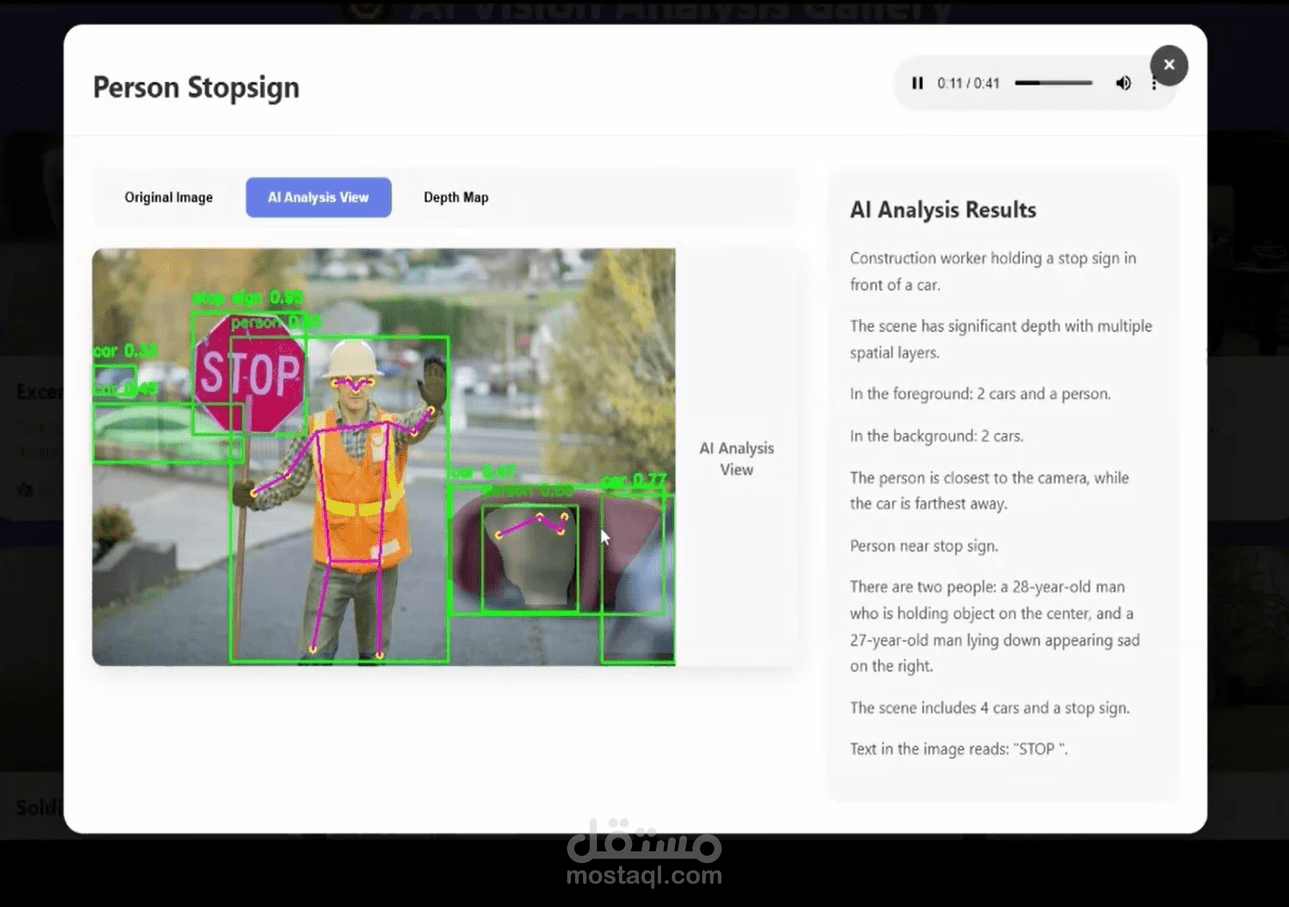
طورت منصة شاملة لتحليل الصور الثابتة باستخدام مجموعة من النماذج الذكية (6+ نماذج AI) لإنتاج وصف تفصيلي ودقيق للمشاهد.
تقوم المنصة بمهام كشف الأجسام (Object Detection)، فهم المشهد (Scene Understanding)، تقدير العمق (Depth Estimation)، التجزئة (Segmentation)، وتوليد الوصف اللغوي (Captioning).
تم دمج نماذج متعددة مثل:
YOLO لاكتشاف وتتبع الأجسام.
BLIP لتوليد أوصاف لغوية ذكية.
MiDaS لتقدير العمق وفهم البنية ثلاثية الأبعاد.
CLIP للتعرف على الأنشطة داخل المشهد.
بالإضافة إلى دمج تحويل النص إلى صوت (TTS) لتوليد وصف صوتي تفاعلي.
تم حل تحديات تقنية متقدمة مثل تحميل النماذج المتعددة ودمجها في تسلسل متناسق عالي الأداء، مع بنية قوية للتعامل مع الأخطاء والاسترجاع التلقائي.