banknote authentication Prediction
تفاصيل العمل
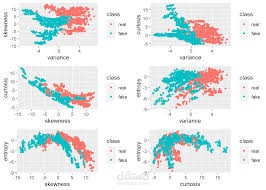
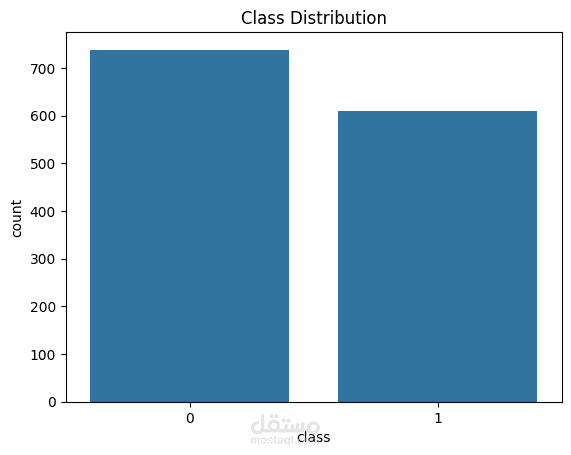
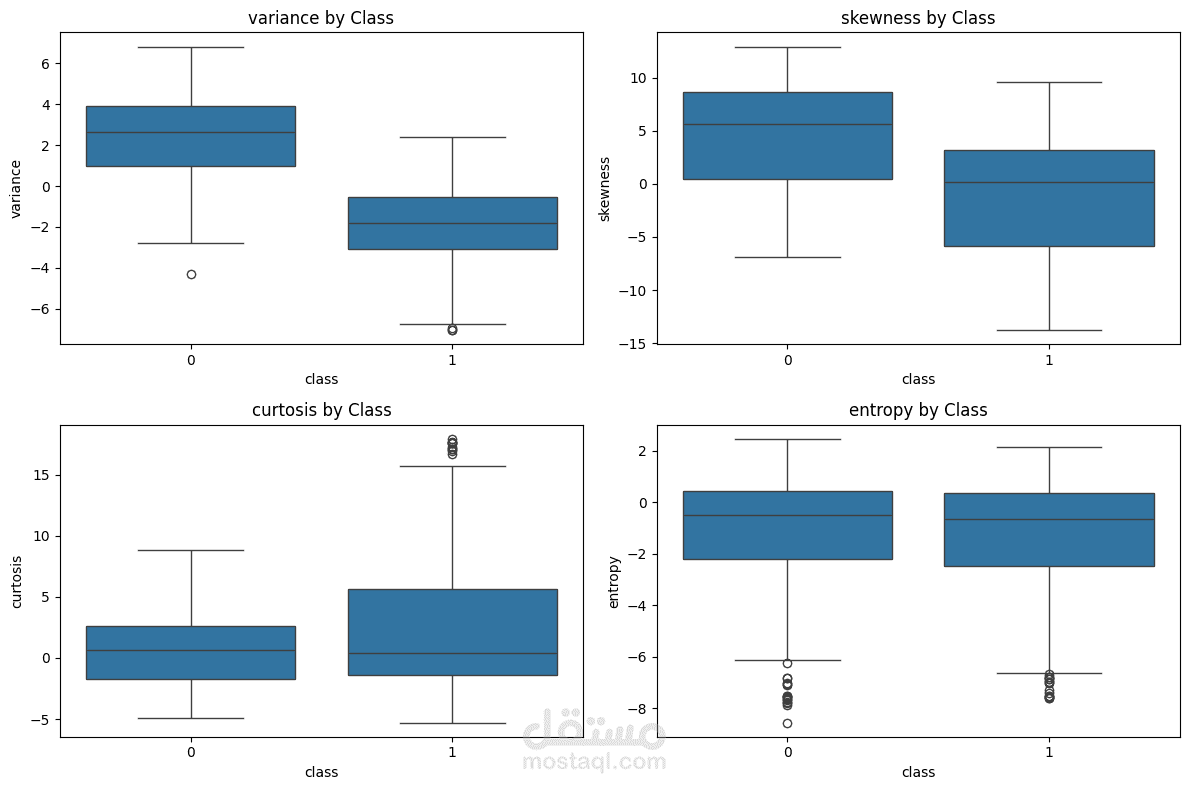
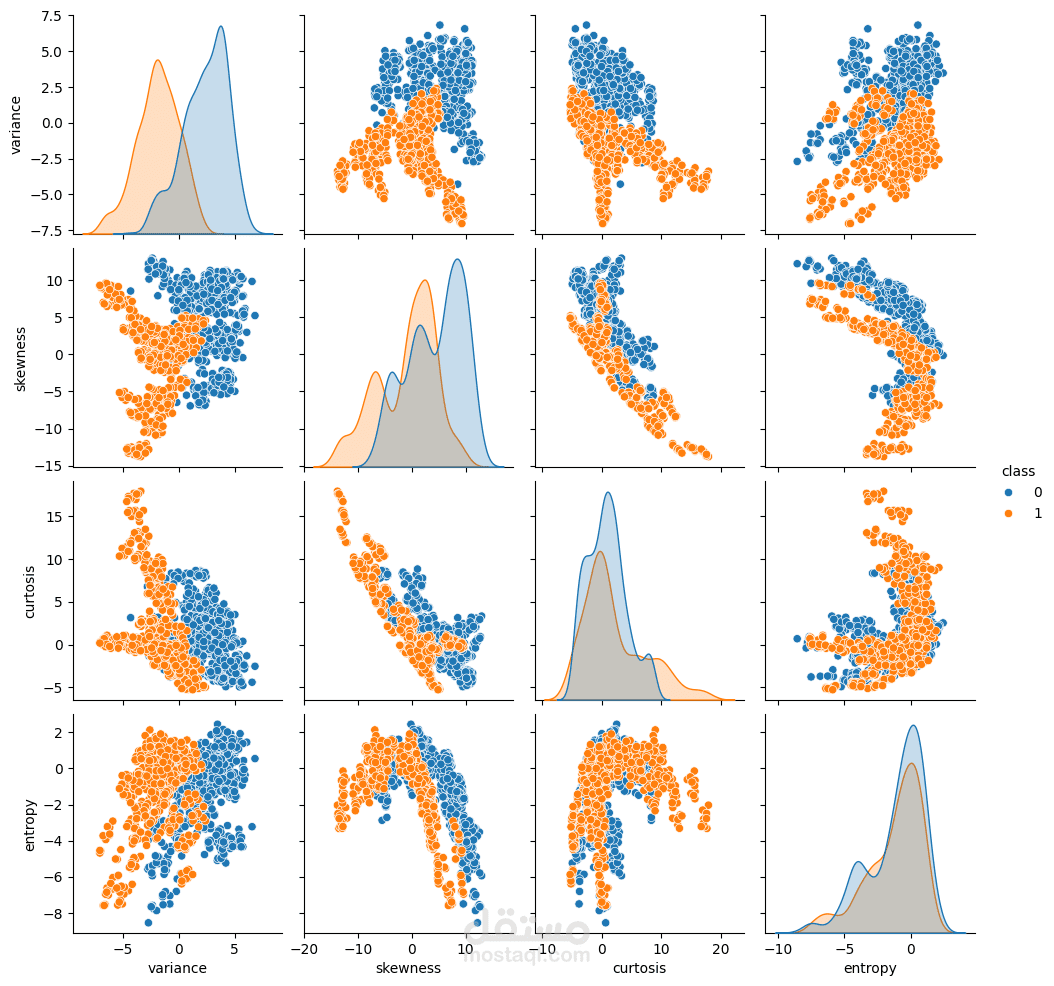

مشروع يهدف إلى بناء نموذج تعلم آلي للتفريق بين العملات الحقيقية والمزيفة باستخدام خصائص مستخرجة من صور الأوراق النقدية.
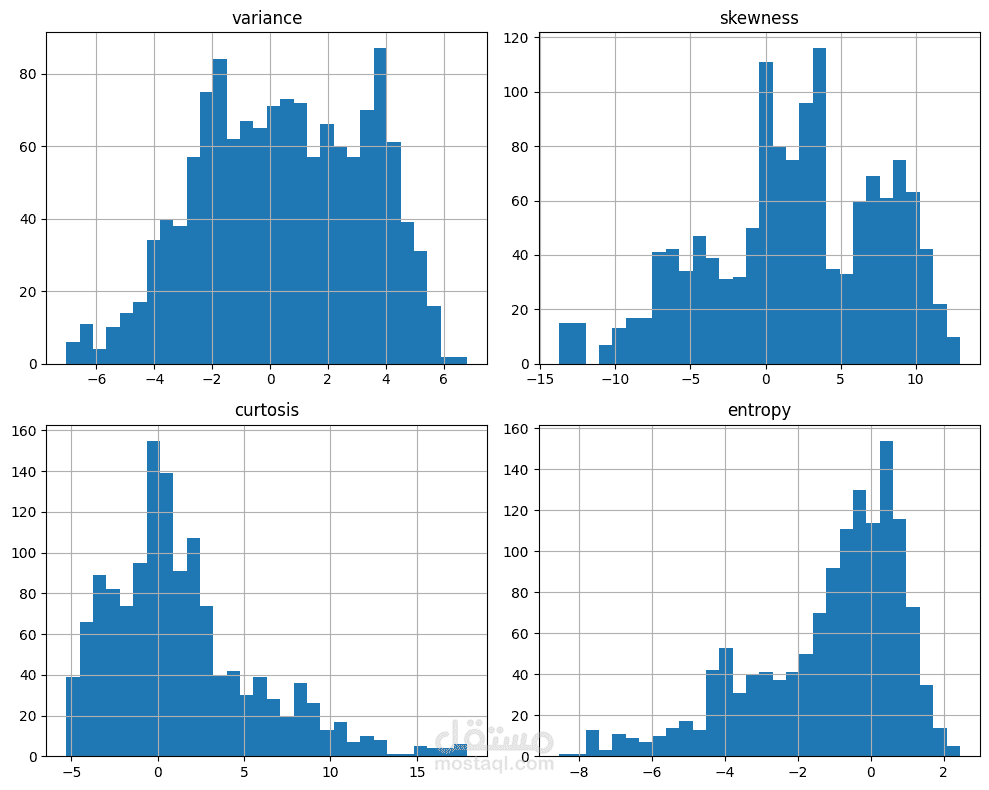
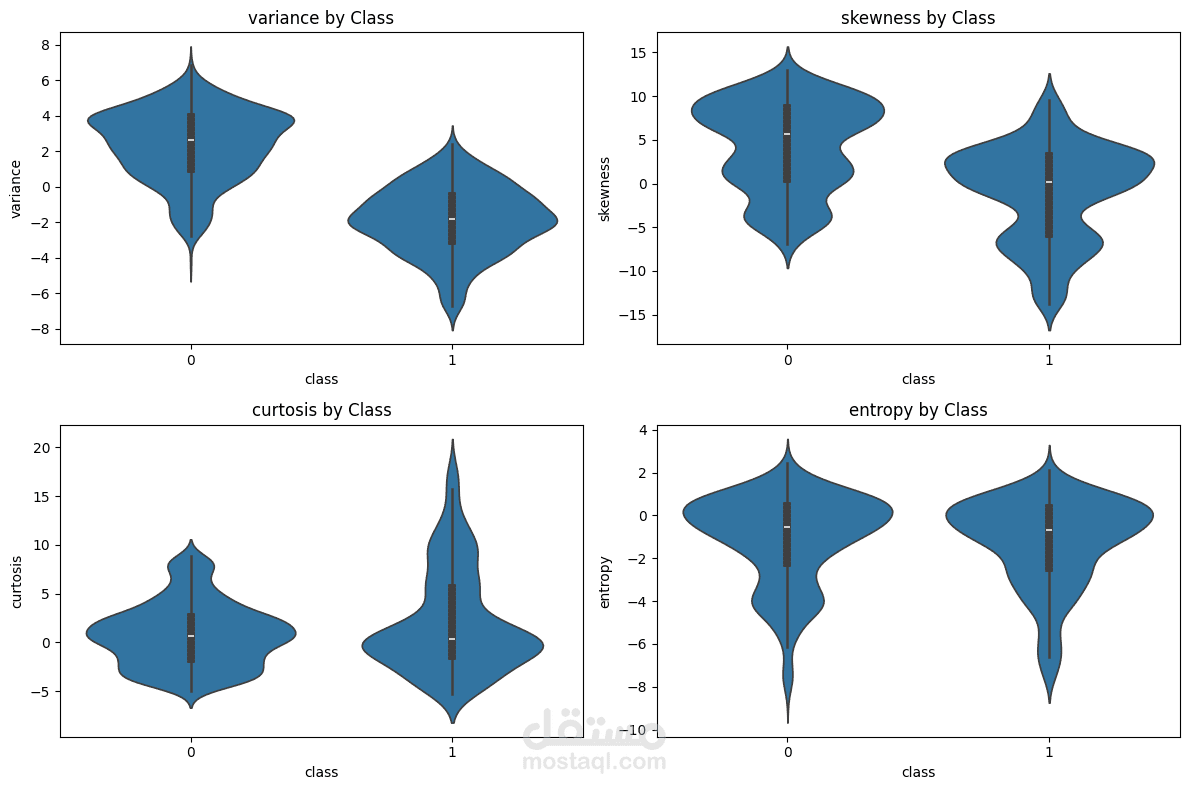
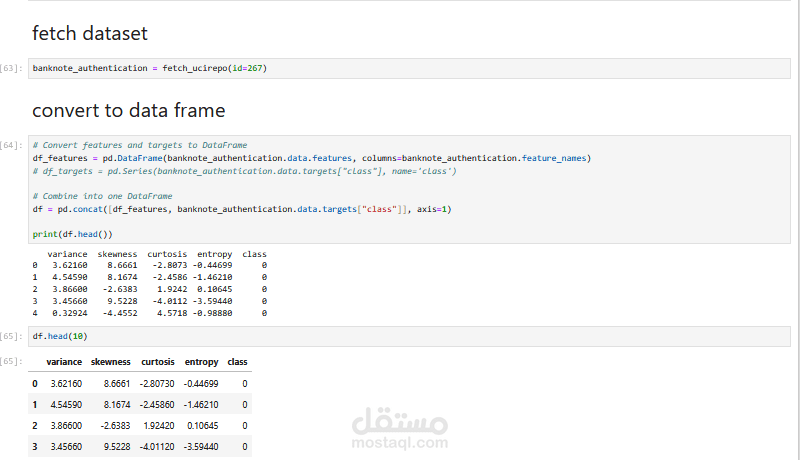
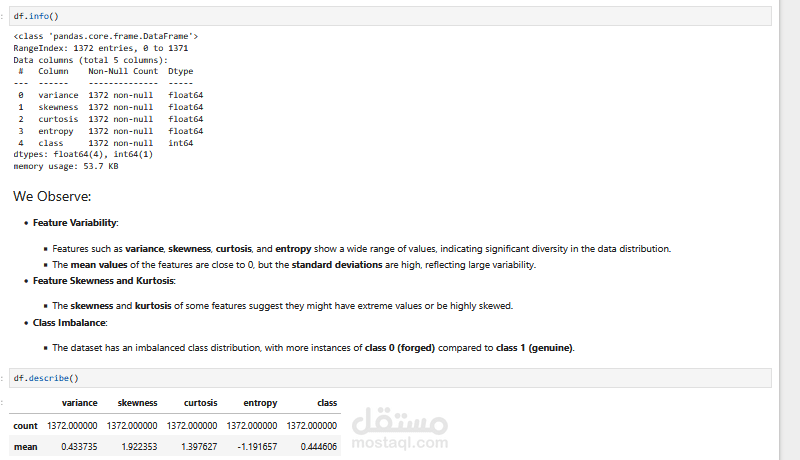
تم الاعتماد على بيانات UCI Banknote Authentication Dataset التي تحتوي على 1372 عينة و4 خصائص إحصائية (variance, skewness, curtosis, entropy).
يتضمن المشروع مراحل التحليل التالية:
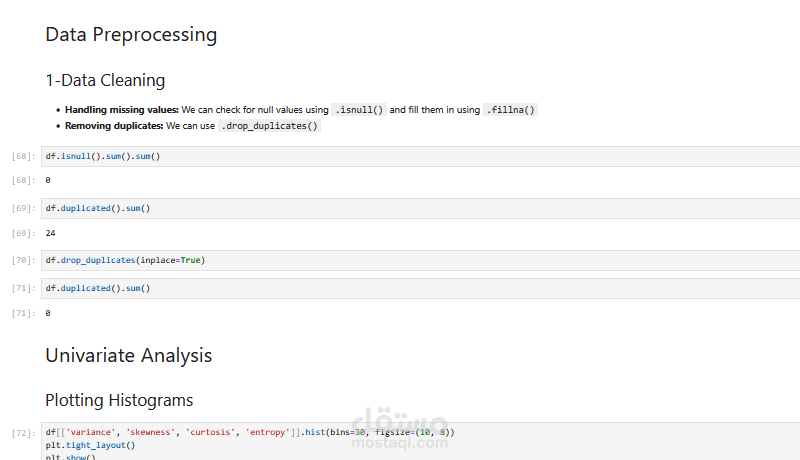
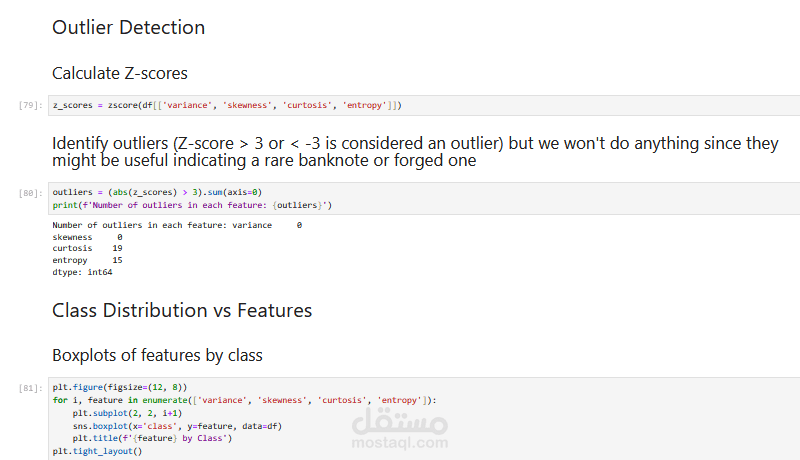
تحليل البيانات الاستكشافي (EDA) لفهم توزيع القيم والكشف عن الانحرافات.
تنظيف البيانات من القيم المكررة والتحقق من القيم المفقودة.
تقييس البيانات باستخدام StandardScaler و RobustScaler لتحسين أداء النماذج.
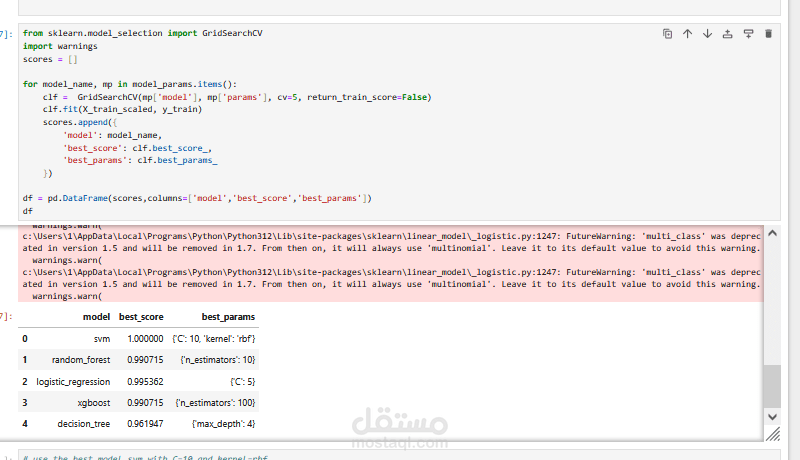
تطبيق عدة خوارزميات تصنيف مثل:
Logistic Regression
Decision Tree
Random Forest
Support Vector Machine (SVM)
XGBoost
Naive Bayes
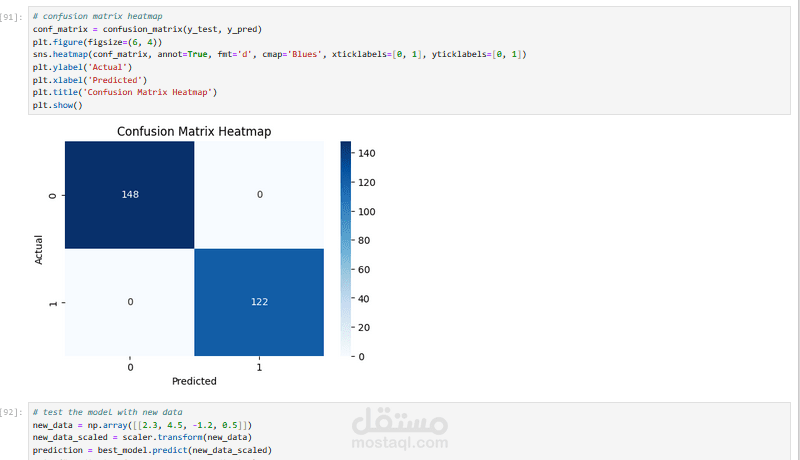
تقييم النماذج باستخدام المقاييس: الدقة (Accuracy)، مصفوفة الالتباس (Confusion Matrix)، وتقرير التصنيف (Classification Report).
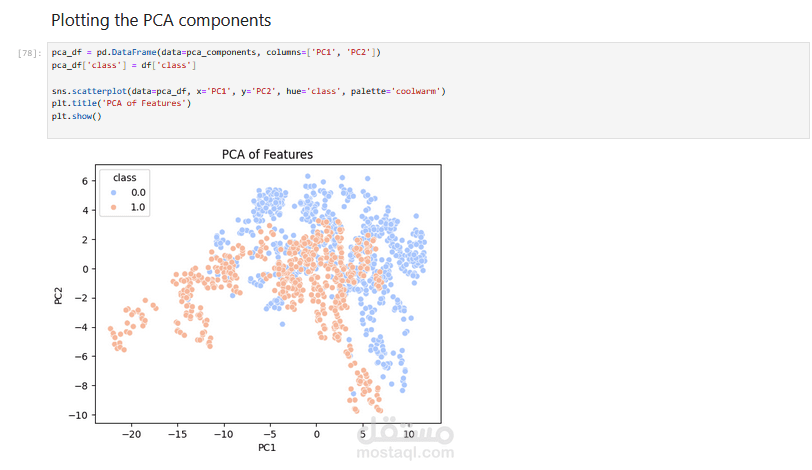
النتيجة: المشروع يوضح مقارنة شاملة بين خوارزميات التصنيف المختلفة لتحديد النموذج الأكثر كفاءة في الكشف عن العملات المزيفة بدقة عالية.