Exploratory Data Analysis on Book Sales, Ratings, and Market Trends with Python
تفاصيل العمل
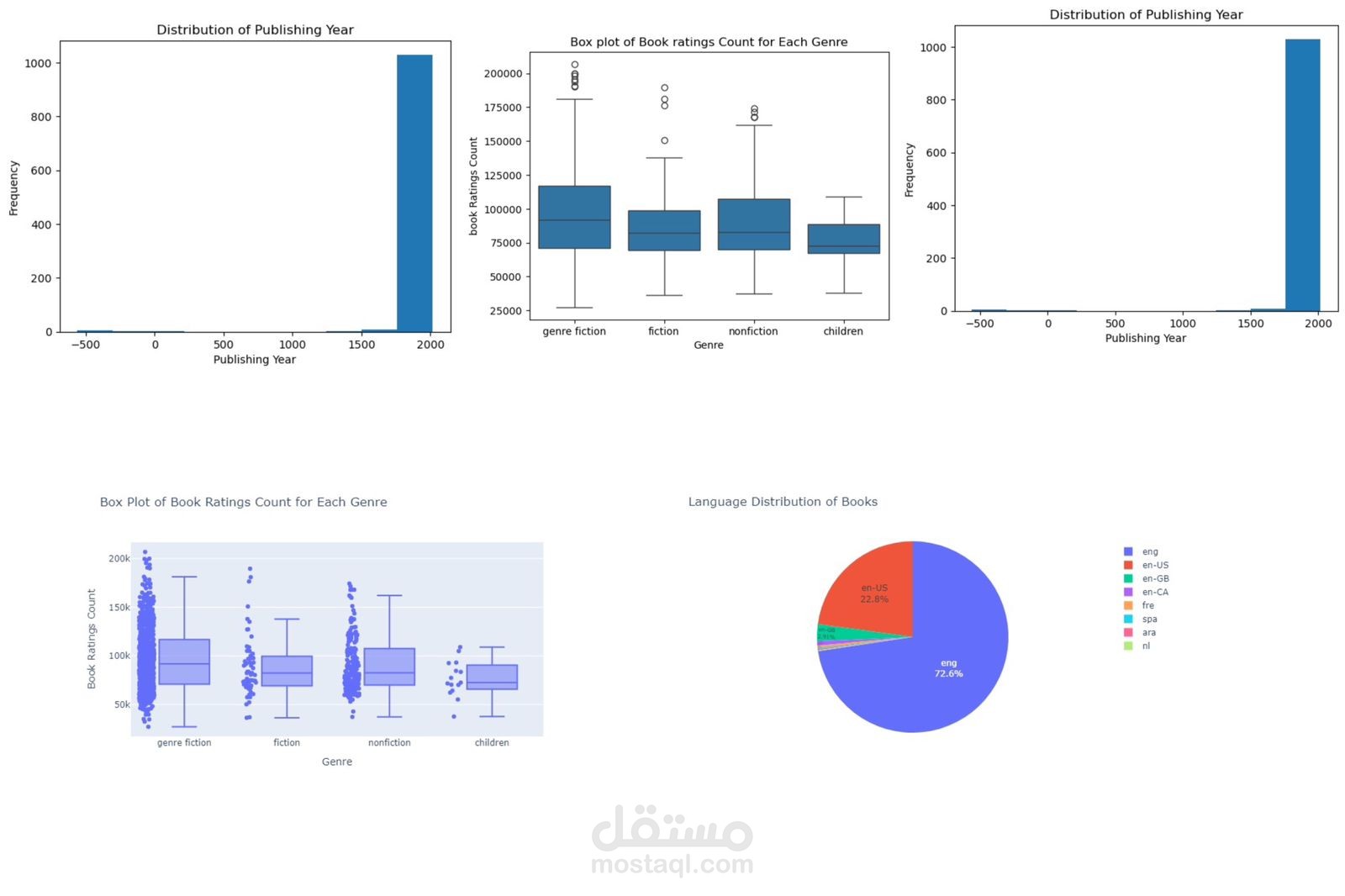
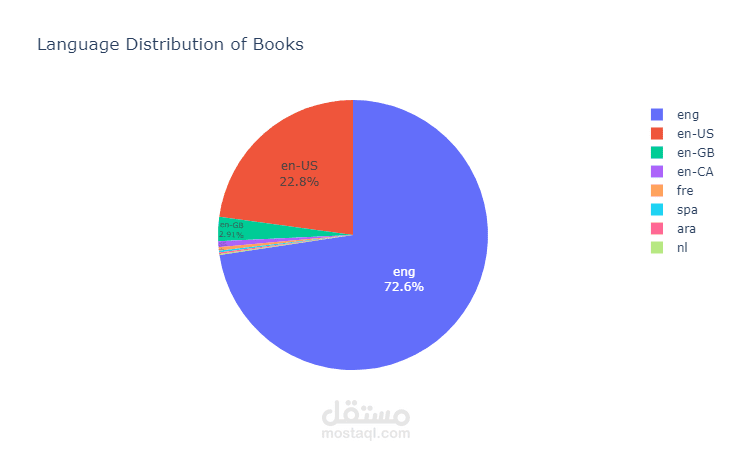
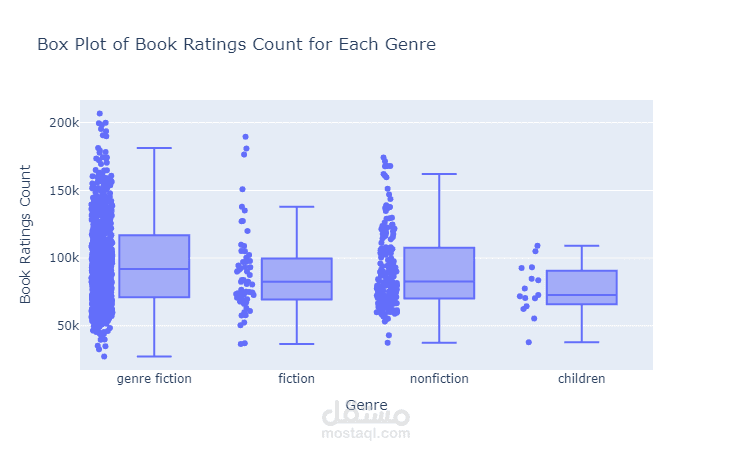
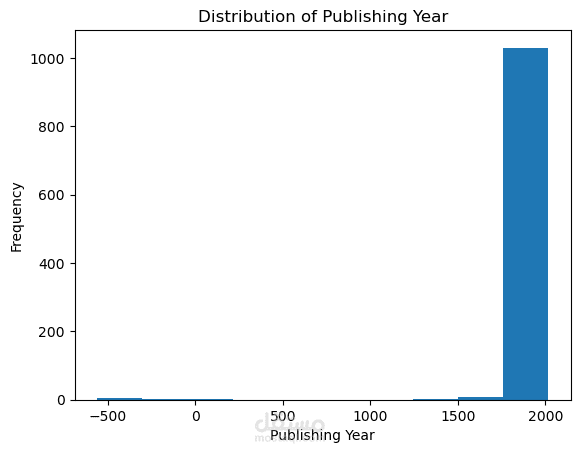
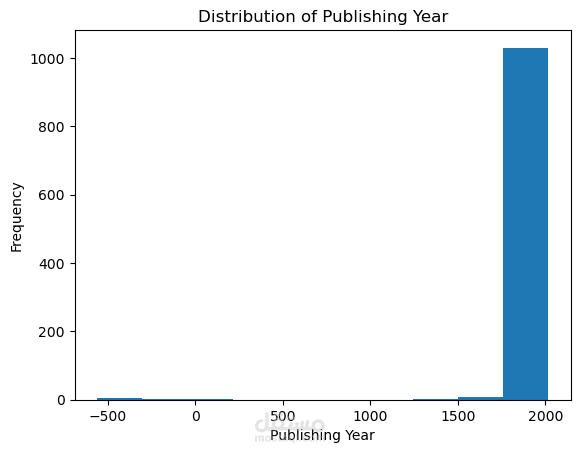
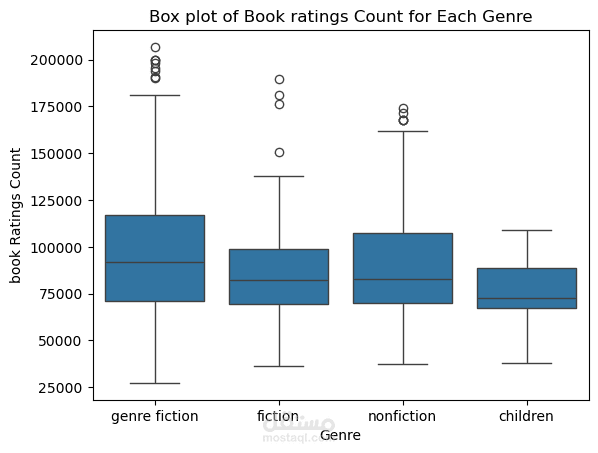
This project focuses on performing Exploratory Data Analysis (EDA) on a comprehensive book dataset that includes information such as book titles, authors, publishing years, genres, languages, ratings, and sales performance. The goal of this analysis is to uncover meaningful insights regarding reading trends, author popularity, and market behavior in the book industry.
The dataset was cleaned and prepared by handling missing values, removing duplicates, correcting inconsistent formatting, and converting numeric columns to appropriate data types. After preprocessing, various analytical and visualization techniques were applied using Python libraries such as Pandas, NumPy, Matplotlib, Seaborn, and Plotly.