Wine Varietal Classification Using Dimensionality Reduction and Ensemble Learning
تفاصيل العمل
This work is a comprehensive machine learning pipeline designed for a multi-class classification task. The core objective is to automatically segregate wines into three distinct customer segments based solely on their physicochemical properties. This type of analysis is crucial in the field of food science and marketing, allowing for data-driven product categorization and targeted customer outreach. The project exemplifies a standard yet powerful approach in data science, moving systematically from raw data to a deployable predictive model through stages of preprocessing, feature engineering, model training, and rigorous evaluation.
The project's main features revolve around its dataset and the techniques applied. The dataset itself consists of 178 wine samples, each described by 13 numerical features such as alcohol content, malic acid, ash, and phenolic compounds. The target variable is the customer segment, which acts as the label for the supervised learning algorithm. A defining feature of this work is its use of Principal Component Analysis (PCA) for dimensionality reduction. Before this step, the data is meticulously preprocessed; it is split into training and testing sets to ensure unbiased evaluation and then standardized. Standardization is critical as it rescales all features to have a mean of zero and a standard deviation of one, preventing variables with inherently larger scales from dominating the model's learning process. The PCA technique is then employed to transform the original 13 correlated features into a smaller set of uncorrelated principal components that still capture the essential patterns in the data, specifically retaining 95% of the original variance.
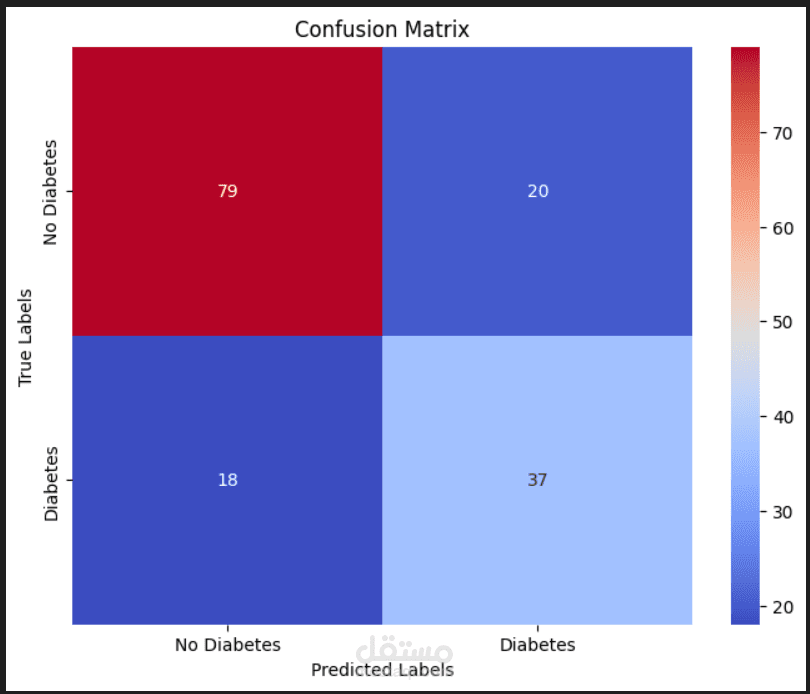
The implementation of this project follows a logical, step-by-step workflow. The process begins by loading the data and splitting it into training and test sets. The training data is then scaled, and PCA is fitted exclusively on this scaled training set to learn the transformation. The number of principal components is dynamically selected as the minimum required to explain 95% of the cumulative variance, a step that efficiently reduces dimensionality and mitigates the risk of overfitting. A Random Forest classifier, an ensemble learning method that operates by constructing a multitude of decision trees, is then trained on this reduced-dimensionality training data. The model's performance is finally assessed by making predictions on the transformed test set. The evaluation, which reports a 94.44% accuracy, is supported by a confusion matrix and a detailed classification report, providing a clear and multi-faceted view of the model's precision, recall, and F1-score for each customer segment, thereby validating the effectiveness of the entire pipeline.