Sentiment Analysis for Arabic Dataset using NLP
تفاصيل العمل

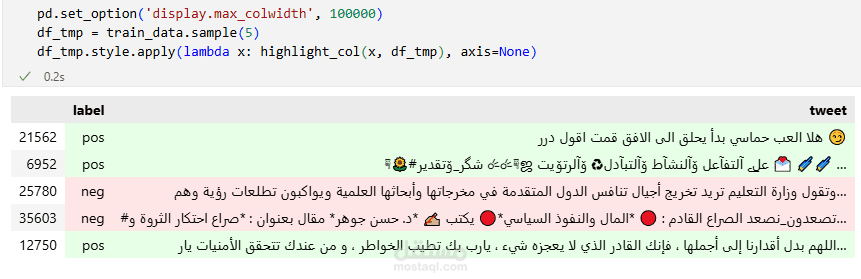


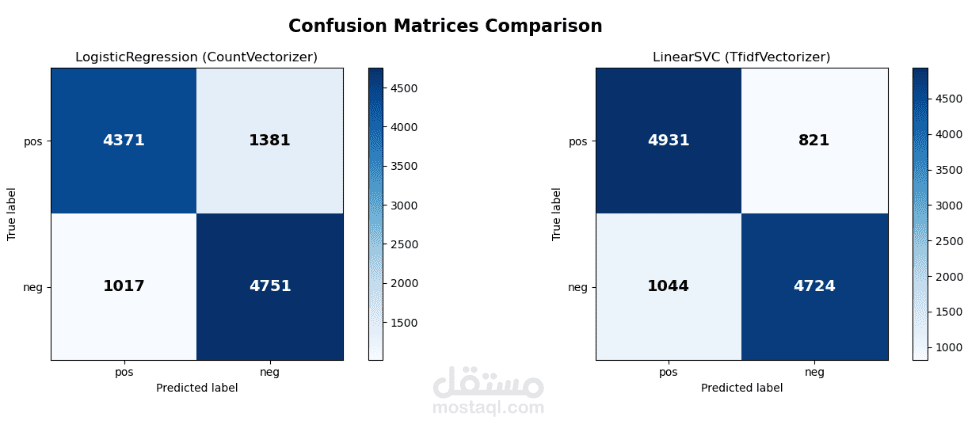

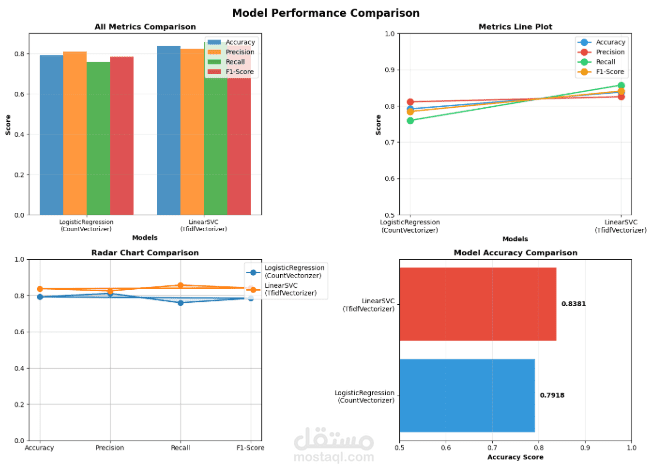
طوّرت نموذجًا لتصنيف النصوص العربية بهدف تحليل مشاعر التغريدات (إيجابية أو سلبية)، باستخدام تقنيات متقدمة في معالجة اللغة الطبيعية (NLP) وتعلم الآلة.
شمل المشروع مراحل متعددة هي:
معالجة البيانات وتحسينها قبل التدريب.
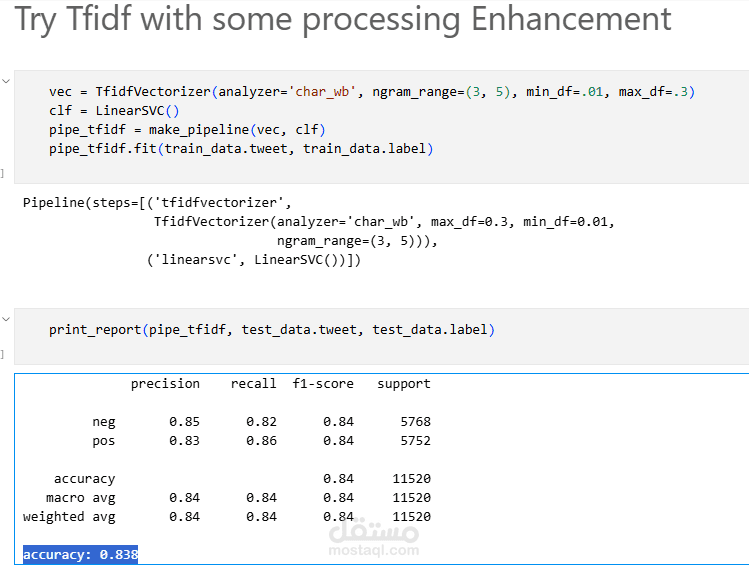
استخراج الخصائص باستخدام كل من CountVectorizer وTF-IDF.
تدريب النماذج باستخدام Logistic Regression وLinear SVM.
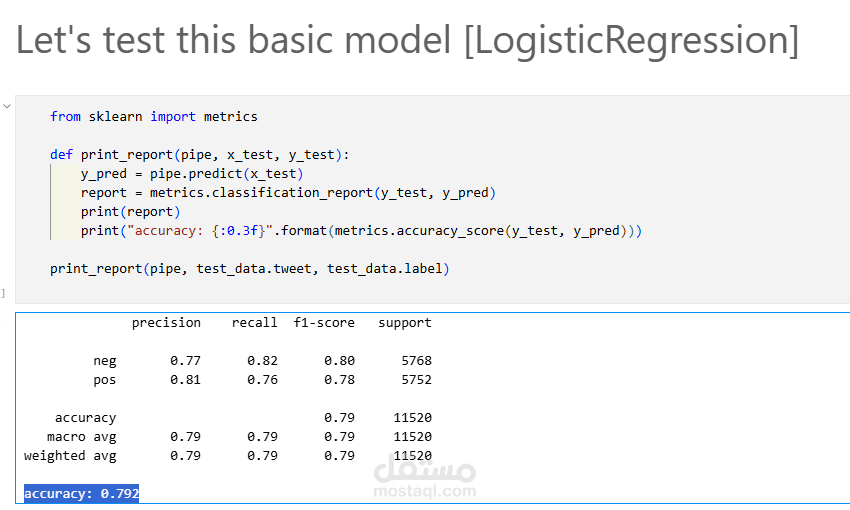
حقق النموذج دقة قوية وأداءً متوازنًا عبر مؤشرات مثل الدقة (Precision) ودرجة F1.
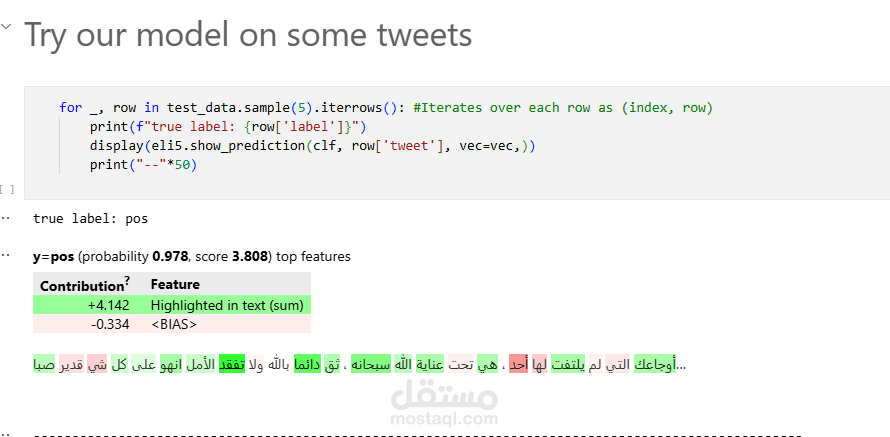
كما تم استخدام مكتبة ELI5 لشرح وتفسير النموذج بصريًا من أجل فهم الميزات الأكثر تأثيرًا وسلوك التنبؤات.
تم تنفيذ المشروع بالكامل بلغة Python باستخدام Pandas وScikit-learn.