نظام ذكاء اصطناعي لكشف التسلل في الشبكات (Anomaly or Normal)
تفاصيل العمل

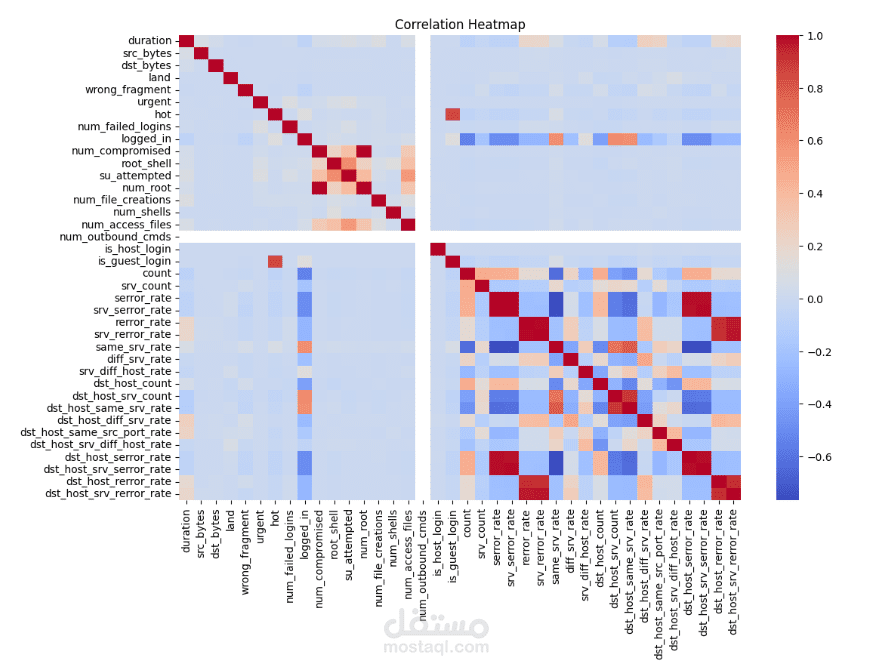
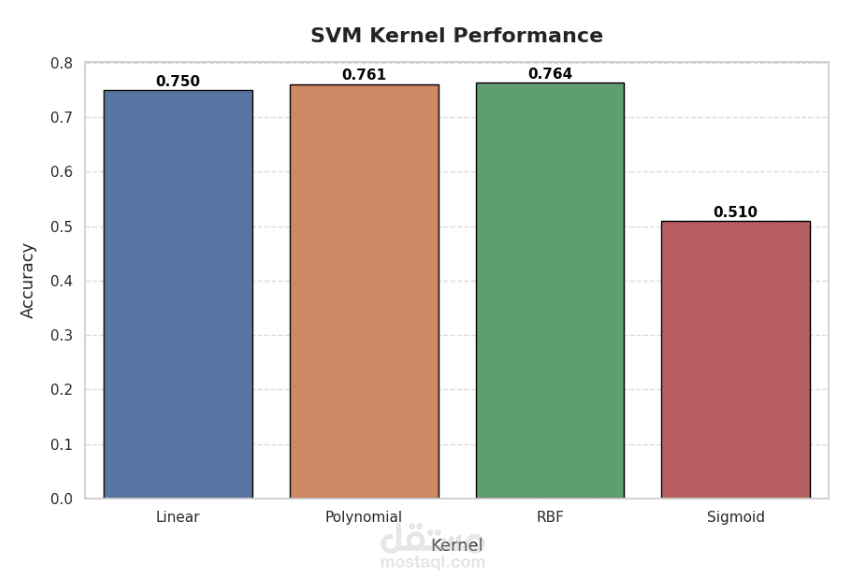
يهدف هذا المشروع إلى بناء نموذج تصنيف دقيق يعتمد على خوارزميات تعلم الآلة الكلاسيكية (SVM و Naive Bayes) لتحليل بيانات معينة وتصنيفها إلى فئات متعددة أو ثنائية. يتم في المشروع استكشاف وفهم أداء كل خوارزمية على بيانات مجموعة محددة، مع مقارنة النتائج بين النهجين.
أهداف المشروع
- تجربة خوارزمية Naive Bayes لتقدير الاحتمالات وفصل الفئات بناءً على التوزيع الشرطي للميزات.
- تجربة خوارزمية Support Vector Machine لبناء حد قرار (decision boundary) قوي يفصل الفئات بدقة عالية، خاصة في الحالات التي يكون فيها التمييز غير خطي أو حدود الفئات معقدة.
- مقارنة أداء الخوارزميتين من حيث الدقة، الحساسية، الدقة الإيجابية، معدل الخطأ، وغيرها من مقاييس التقييم.
- تحليل مدى تأثر الأداء بخصائص الميزات (feature engineering) مثل اختيار الميزات الملائمة، تطبيع البيانات، واستخدام تحويلات مناسبة (scale / normalization).
تدريب النماذج:
- تطبيق خوارزمية Naive Bayes للحصول على نموذج بسيط يعتمد على الفرضيات الشرطية البسيطة.
- تدريب نموذج SVM مع اختيار kernel مناسبة (خطي أو غير خطي مثل RBF أو polynomial).
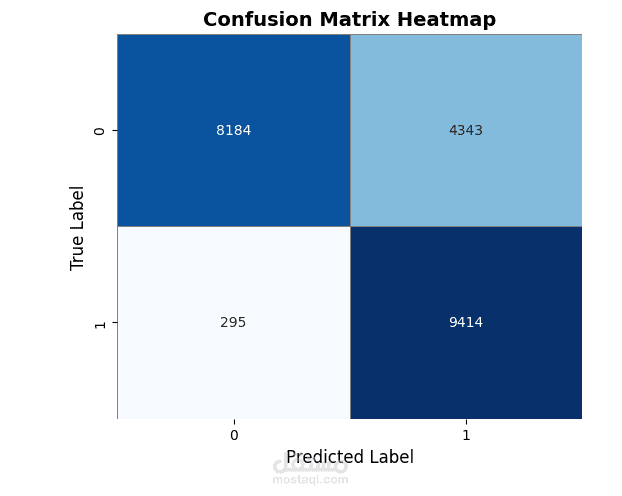
- تقييم النماذج: استخدام تقنيات التحقق المتقاطع (cross-validation) أو مجموعة اختبار مستقلة لقياس أداء النماذج عبر مقاييس مثل الدقة (accuracy)، الـ F1-score، الحساسية (recall)، الدقة الإيجابية (precision).
- المقارنة والتحليل: تحليل النتائج بين الخوارزميتين، استكشاف الحالات التي تتفوق فيها كل خوارزمية، ومعرفة نطاق الخطأ أو الحالات التي يصعب فيها التصنيف.
النتائج المتوقعة
- نموذج Naive Bayes بسيط وسريع التنفيذ يقدم نتائج جيدة في البيانات ذات الفرضيات الشرطية القريبة.
- نموذج SVM قادر على التعامل مع الفواصل المعقدة بين الفئات وتحسين أداء التصنيف في الحالات غير الخطية.
- تقرير تحليل شامل يوضح المقاييس المختلفة، حالات الخطأ (misclassifications)، وتحليل الفروقات بين الخوارزميات.
- رؤية واضحة لكيفية تحسين الأداء من خلال تخصيص الميزات أو تعديل المعاملات (hyperparameters).