(Sentiment Analysis) نظام تحليل مشاعر لتغريدات مصرية (BERT)
تفاصيل العمل
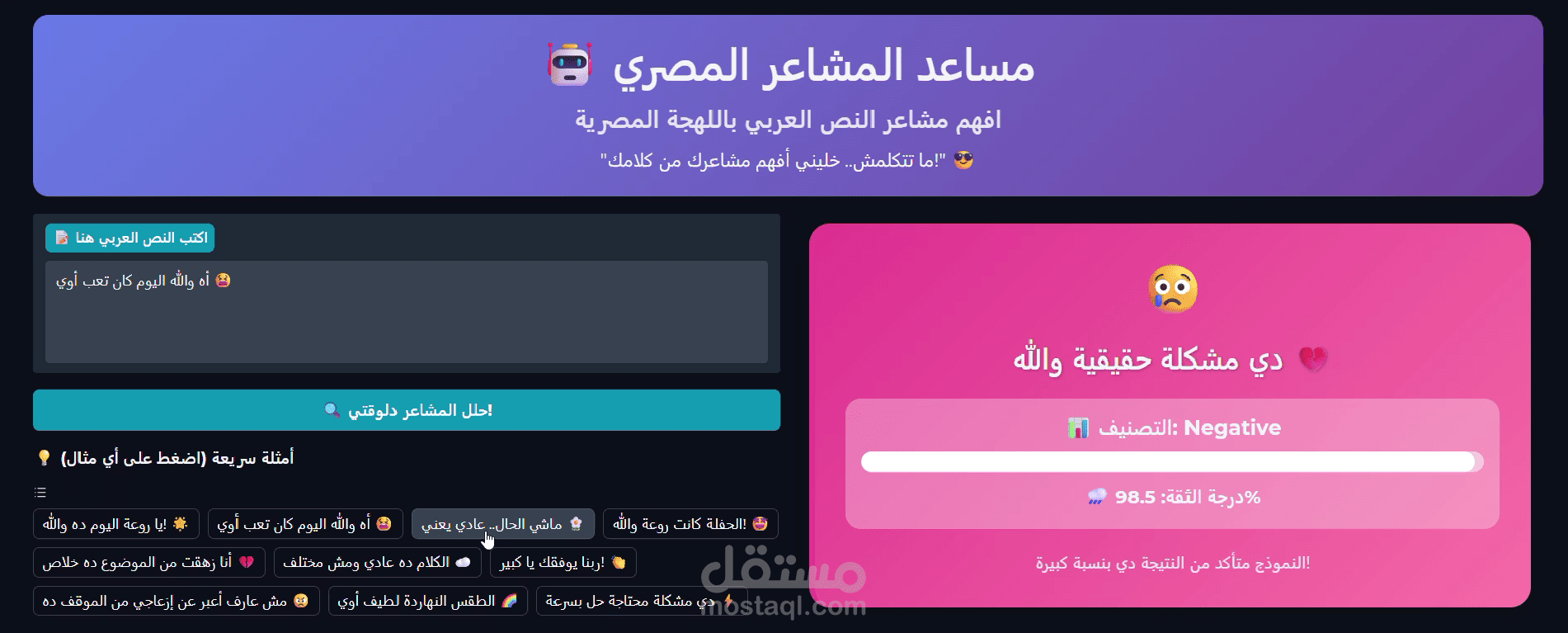
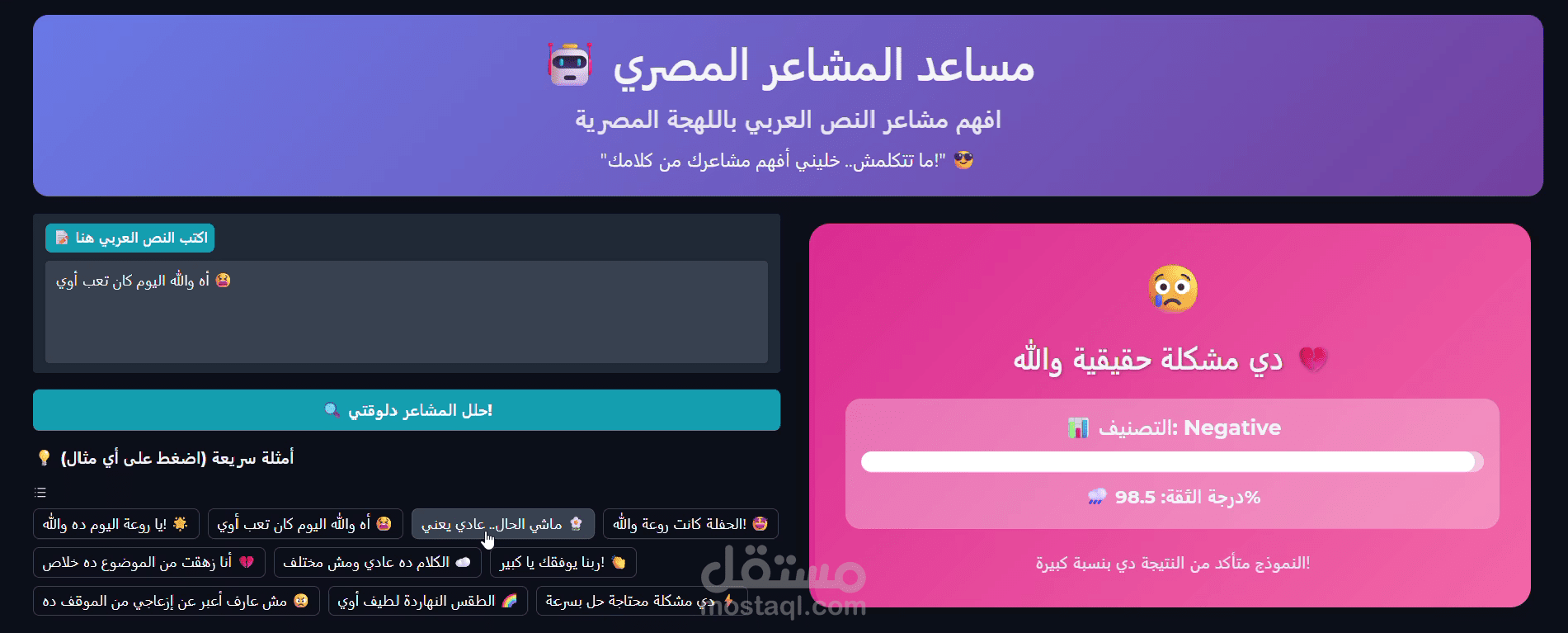
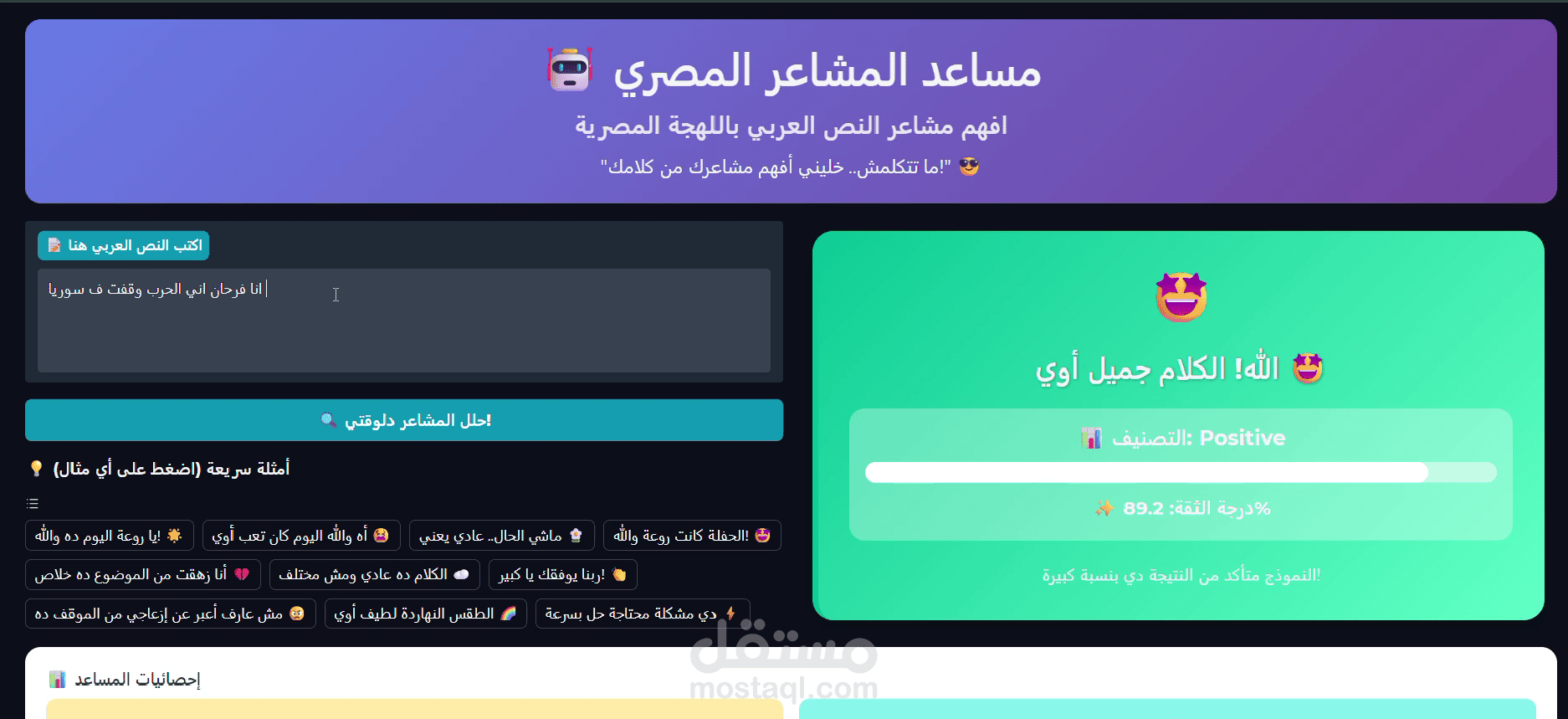
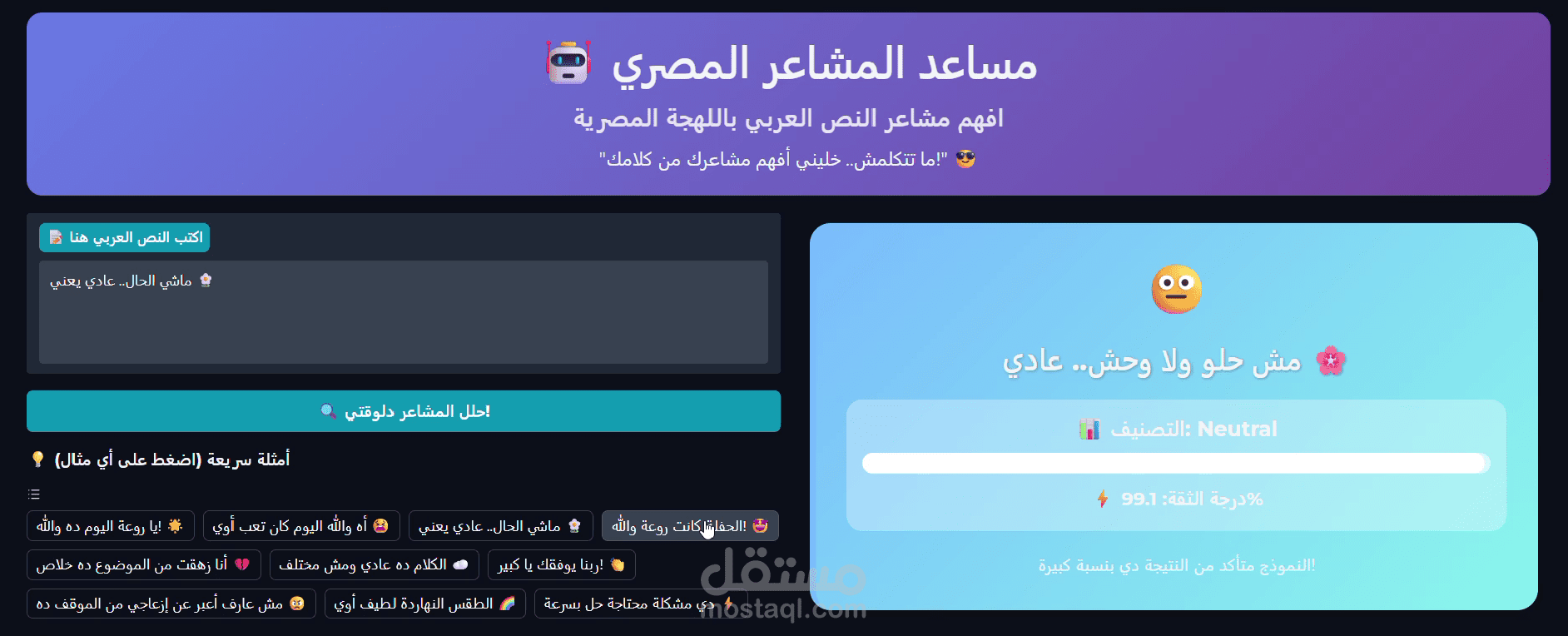
موديل BERT مخصّص للهجة المصرية لتحليل المشاعر — تسلّم: نوتبوك منظّم، موديل محفوظ + tokenizer، سكربت استدلال، تقرير تقييم، وخيار نشر كـ API/واجهة تفاعلية.
يتعامل مع العامية المصرية، الرموز التعبيرية والهاشتاجات بدقة عملية للحصول على نتائج مفهومة وقابلة للاعتماد.
مناسب للاستخدام في مراقبة السوشال ميديا، تحليل آراء العملاء، أو أتمتة تصنيف التغريدات.
جاهز للنشر: كود منظّم، نموذج محفوظ، وواجهة استدلال سريعة لدمجها في أنظمة حقيقية.
مميزات المشروع
Fine-tuned BERT (Hugging Face) على مجموعة تغريدات مصرية.
خطوات تنظيف ومعالجة مخصصة للعربية واللهجة المصرية (normalization, handling emojis/mentions/hashtags).
تقييم كامل: precision / recall / F1 لكل فئة + confusion matrix + تحليل أخطاء نمطي.
حفظ الموديل والـtokenizer (save_pretrained) وpredict.py للاستخدام الفوري.
تنظيم احترافي على GitHub: Notebook مرتب، train.py, predict.py, requirements.txt, README.
خيار نشر واجهة تفاعلية (Gradio) أو REST API (FastAPI) حسب الطلب.
التقنيات والأدوات
Hugging Face Transformers (BERT / AutoModelForSequenceClassification)
PyTorch أو Trainer من Hugging Face
scikit-learn (تقسيم، مقاييس التقييم)
أدوات preprocessing للغة العربية (tokenization, normalization)
(اختياري) Gradio أو FastAPI للنشر السريع