customer-support-intent-dataset preprocessing
تفاصيل العمل
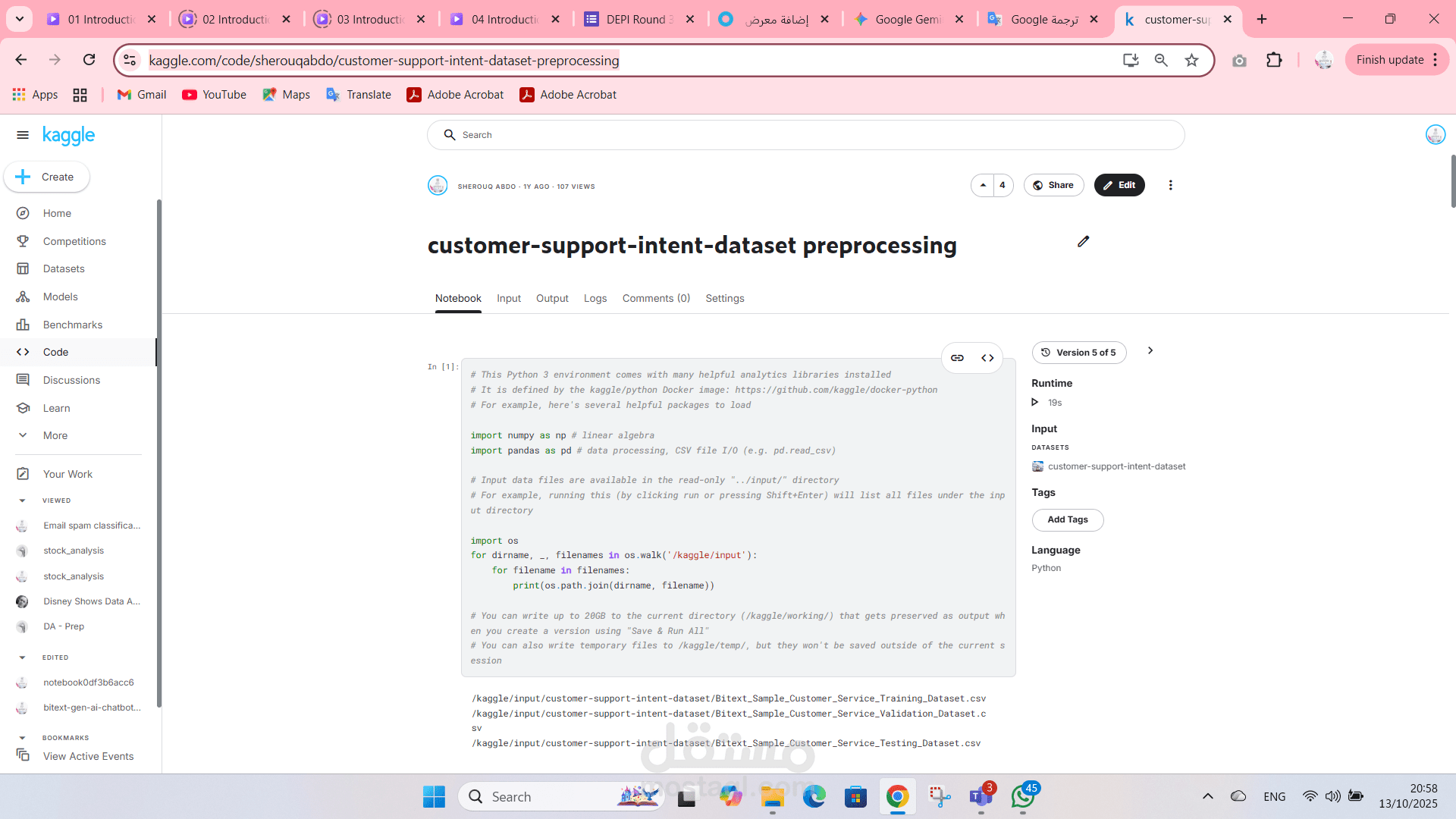
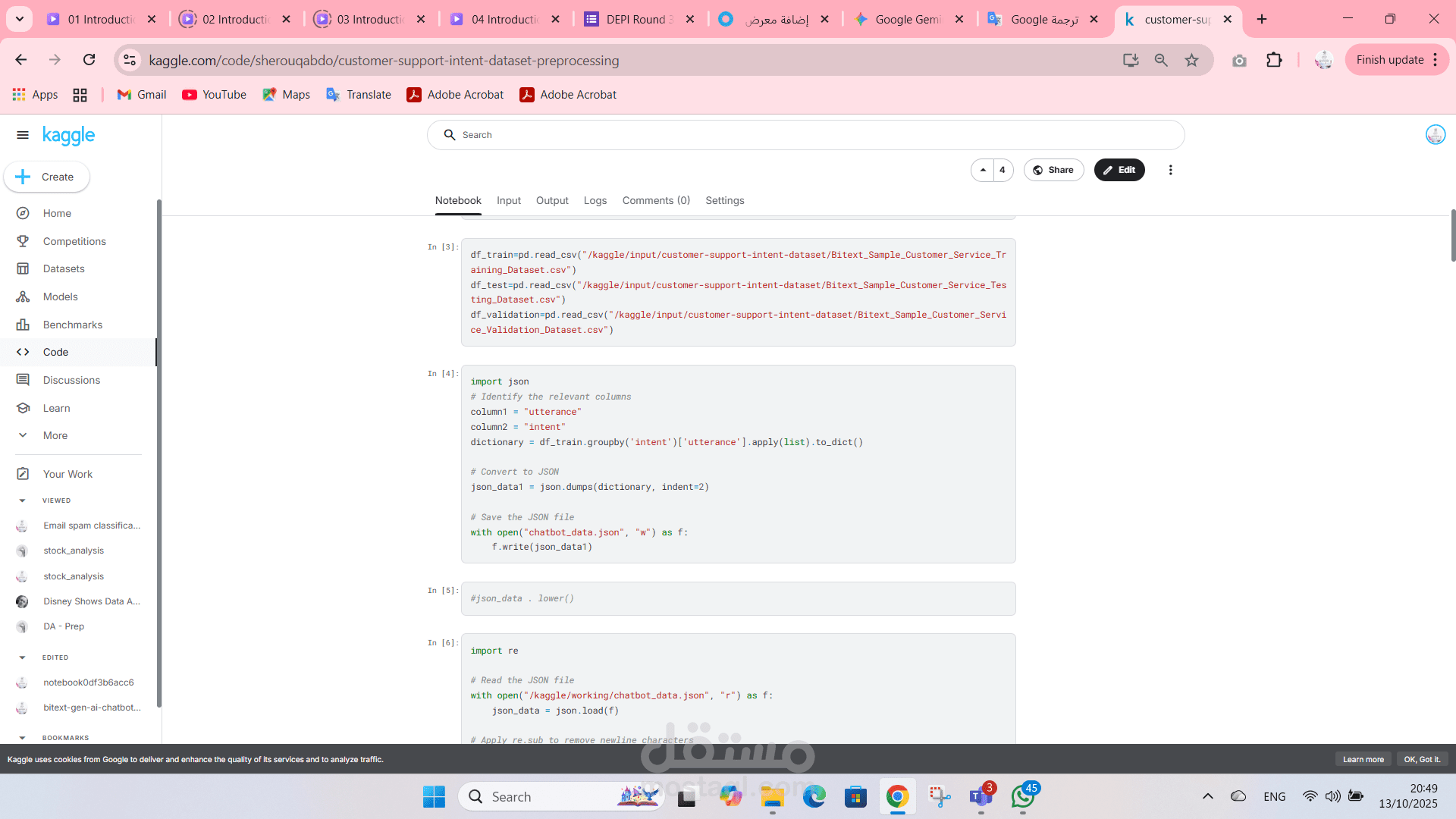
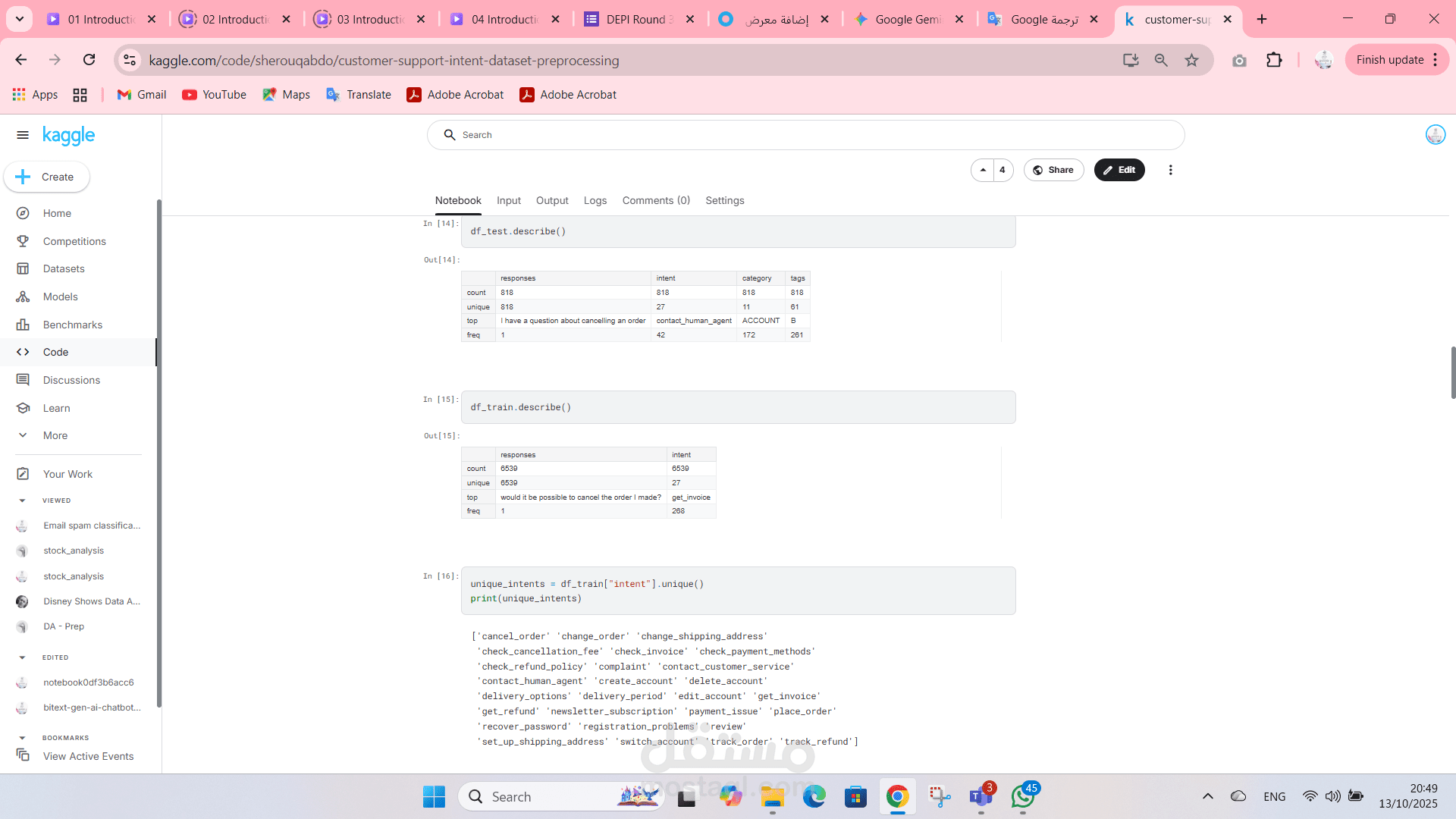
This project focuses on the essential preprocessing of a customer support intent dataset to prepare it for machine learning applications, specifically for intent classification models. The primary goal is to clean and normalize the raw text data to create a structured and effective feature set.
Key preprocessing steps implemented:
Data Cleaning: Removed irrelevant characters, such as URLs, HTML tags, punctuation, and extra whitespace, to standardize the text.
Text Normalization: Converted all text to lowercase to ensure consistency.
Tokenization: Broke down sentences into individual words (tokens) for analysis.
Stop Word Removal: Eliminated common, non-informative words (e.g., "the," "is," "a") to reduce noise in the data.
Lemmatization: Transformed words to their base or dictionary form (e.g., "running" to "run") to group related words and reduce feature dimensionality.
يركز هذا المشروع على المعالجة المسبقة الأساسية لمجموعة بيانات نية دعم العملاء لتجهيزها لتطبيقات التعلم الآلي، وتحديدًا لنماذج تصنيف النية. الهدف الرئيسي هو تنظيف بيانات النص الخام وتطبيعها لإنشاء مجموعة ميزات منظمة وفعالة.