مشروع سحب وتنظيم البيانات من مواقع إلكترونية (Web Scraping Project)
تفاصيل العمل
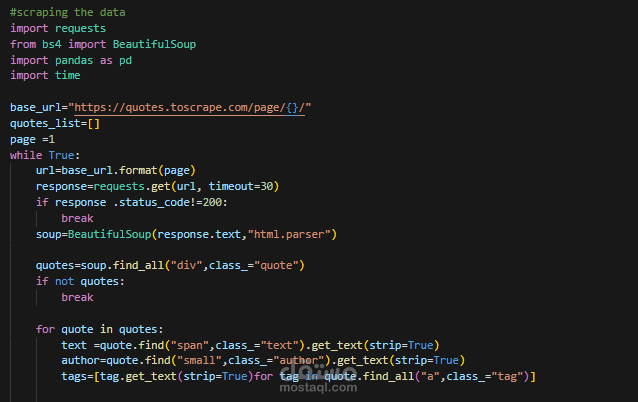
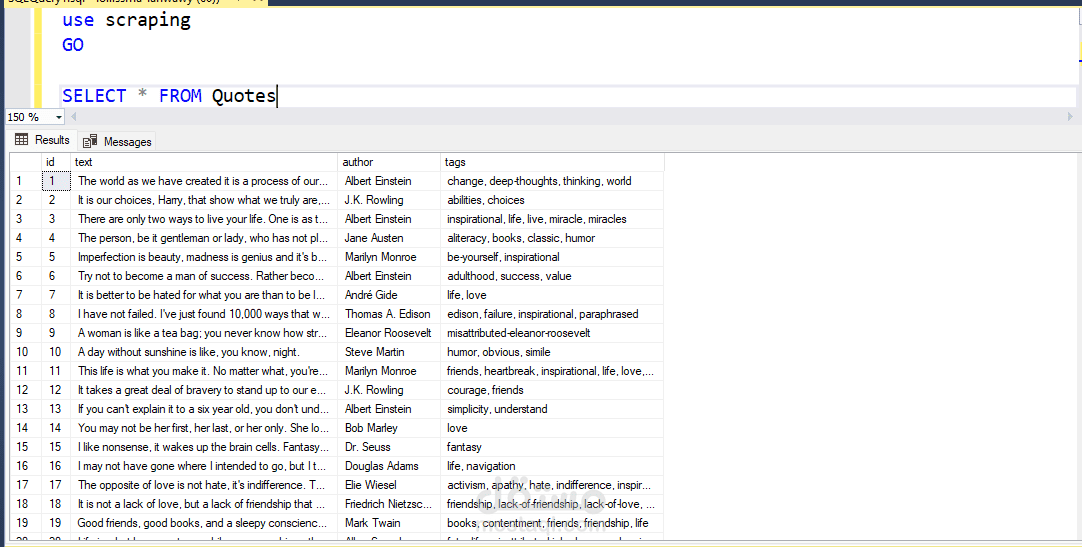
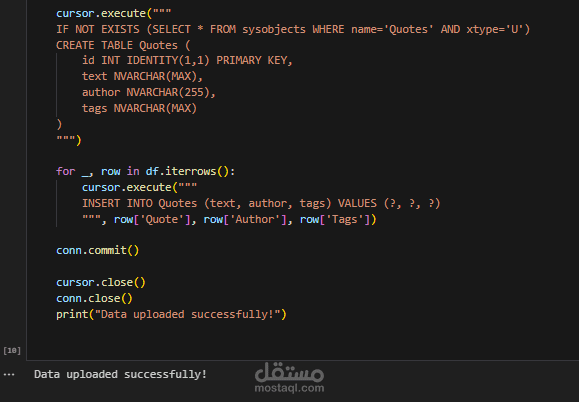
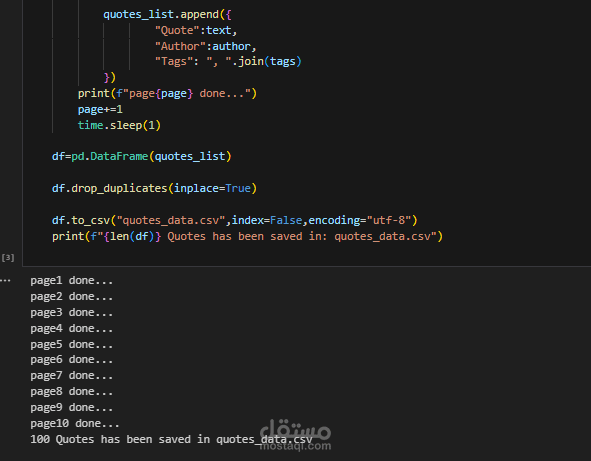
تم تطوير سكريبت بلغة Python لاستخراج بيانات من مواقع إلكترونية متعددة بطريقة آلية.
اعتمد المشروع على مكتبة BeautifulSoup لجمع عناصر محددة مثل النصوص، الأسماء، والعلامات (Tags) من صفحات متعددة، ثم تم تنظيف البيانات وتنظيمها باستخدام تقنيات معالجة البيانات.
بعد ذلك، تم تخزين النتائج في قاعدة بيانات SQL Server لتسهيل عمليات الاستعلام والتحليل، بالإضافة إلى حفظ نسخة من البيانات في ملف CSV منسق لاستخدامها لاحقًا في التحليل أو النماذج.
يُظهر المشروع قدرة على التعامل مع هياكل HTML مختلفة، وربطها بأنظمة قواعد بيانات احترافية بكفاءة عالية.