Obesity Classification Using Machine Learning Algorithms
تفاصيل العمل
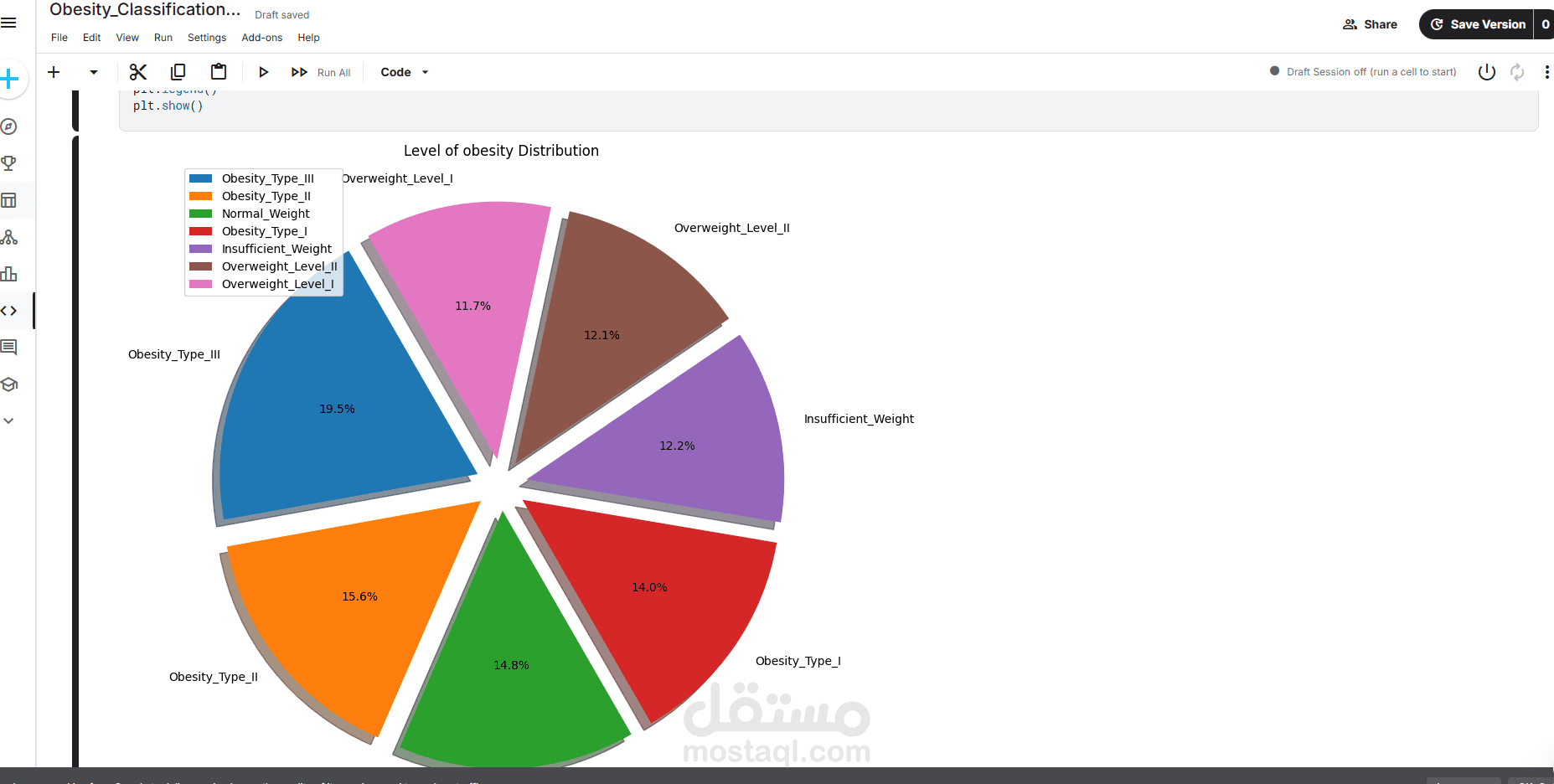
يهدف هذا المشروع إلى تحليل مجموعة بيانات تحتوي على معلومات ديموغرافية وسلوكية (مثل العمر، الجنس، النظام الغذائي، والنشاط البدني) لتصنيف مستوى السمنة لدى الأفراد.
تم استخدام مكتبات Pandas، NumPy، Seaborn، وMatplotlib لتحليل البيانات واستكشاف الأنماط، بالإضافة إلى تطبيق خوارزميات تعلم الآلة لتوقع فئة السمنة بدقة عالية.
يبدأ المشروع بمرحلة الاستكشاف (EDA) حيث يتم تحليل توزيع الخصائص مثل:
توزيع الجنس (Gender Distribution): رسم دائري يوضح نسبة الذكور والإناث في العينة.
توزيع العمر (Age Distribution): رسم بياني يوضح أن معظم الأعمار تقع في نطاق الشباب، مع توضيح الاختلاف بين الجنسين باستخدام Box Plot.
بعد التحليل الإحصائي، ينتقل المشروع إلى مرحلة بناء النماذج التي تهدف إلى توقع مستوى السمنة (مثل: Underweight, Normal, Overweight, Obese) باستخدام تقنيات تصنيف مثل:
Logistic Regression
Random Forest
Support Vector Machine (SVM)
كما يتم تقييم أداء النماذج باستخدام مقاييس مثل الدقة (Accuracy) ومصفوفة الالتباس (Confusion Matrix) لقياس جودة التصنيف.