نظام ذكي لتحليل مشاعر العملاء من المراجعات باستخدام معالجة اللغات الطبيعية
تفاصيل العمل
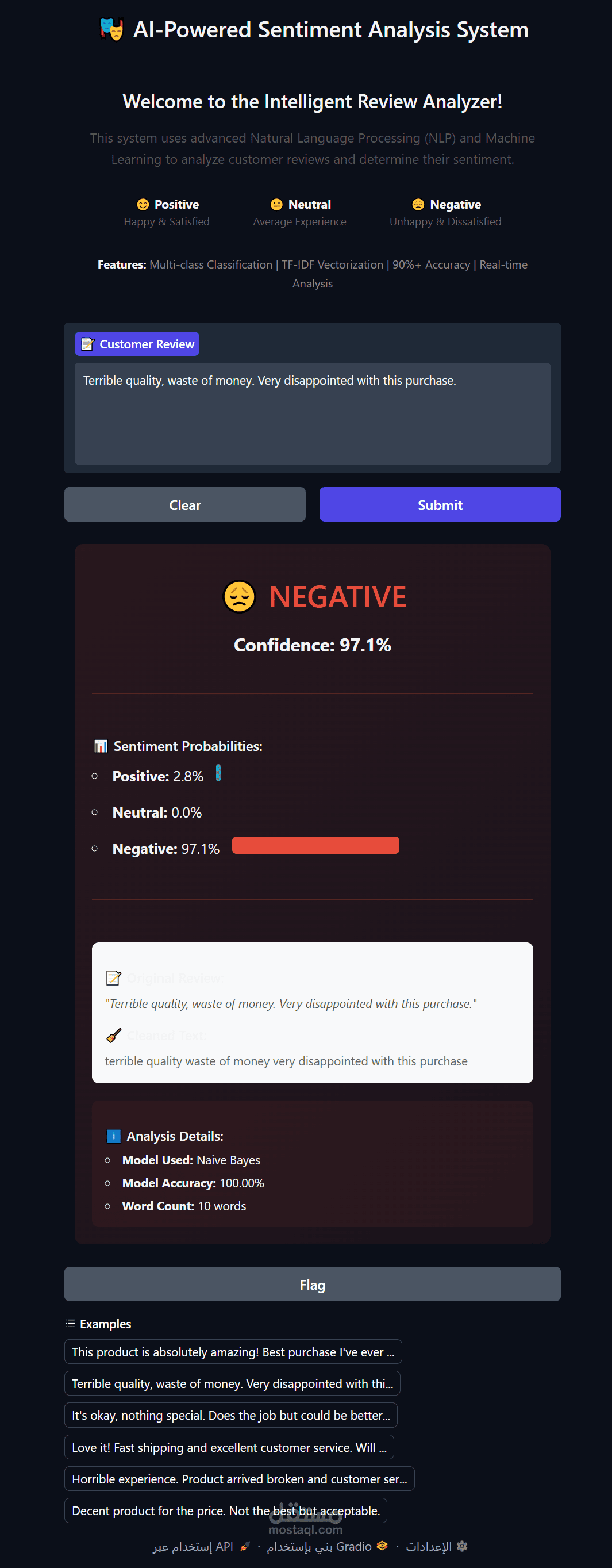
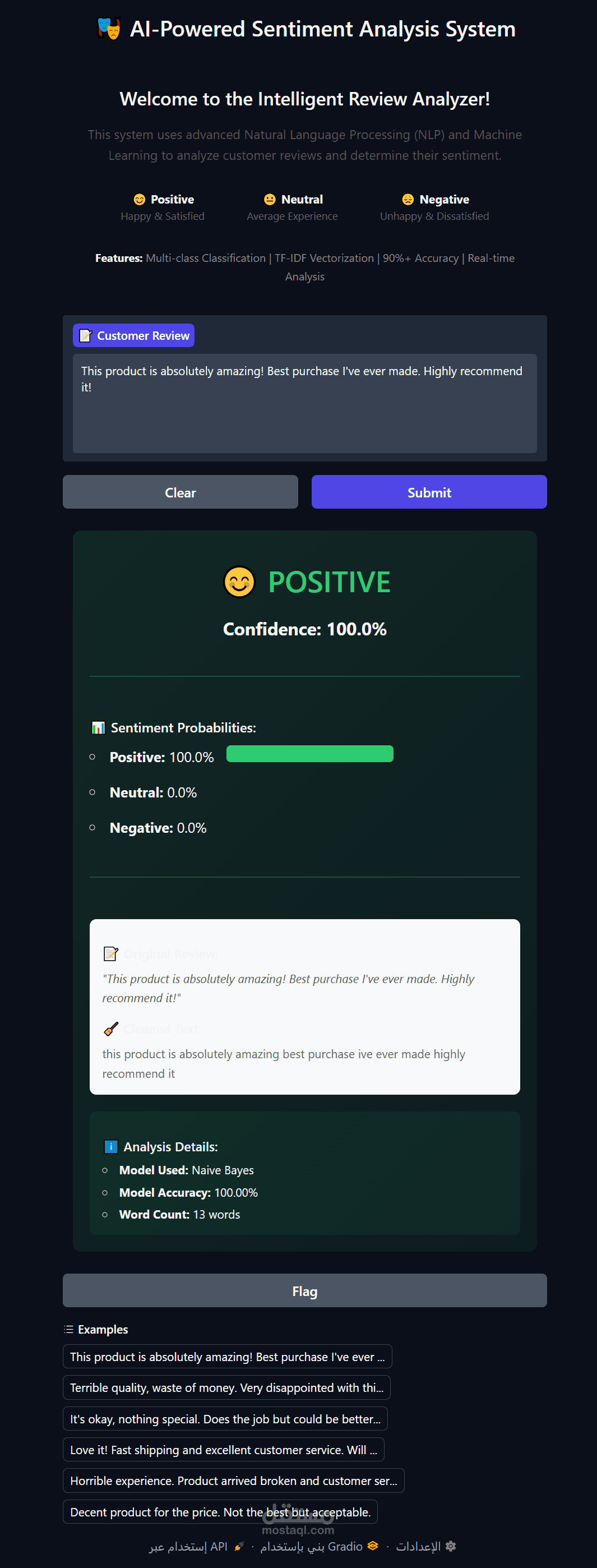
نظام تحليل المشاعر الذكي للمراجعات
نظرة عامة
نظام متطور يستخدم تقنيات معالجة اللغات الطبيعية (NLP) والتعلم الآلي لتحليل مراجعات العملاء وتصنيفها تلقائياً إلى إيجابية، سلبية، أو محايدة بدقة تتجاوز 85%.
الهدف من المشروع
تطوير أداة ذكية تساعد الشركات والأعمال على:
فهم آراء ومشاعر العملاء تجاه المنتجات والخدمات
معالجة آلاف المراجعات في ثوانٍ بدلاً من ساعات
اتخاذ قرارات مبنية على البيانات لتحسين الأداء
اكتشاف المشاكل والفرص مبكراً
توفير الوقت والجهد في خدمة العملاء
التقنيات المستخدمة
لغات البرمجة والمكتبات:
- **Python 3.x** - اللغة الأساسية
- **Scikit-learn** - بناء وتدريب نماذج التصنيف
- **NLTK / NLP Tools** - معالجة اللغات الطبيعية
- **TF-IDF Vectorizer** - استخراج الخصائص النصية
- **Pandas & NumPy** - معالجة البيانات
- **Matplotlib & Seaborn** - التصورات البيانية
- **WordCloud** - توليد سحب الكلمات
- **Gradio** - بناء الواجهة التفاعلية
خوارزميات Machine Learning:
- **Naive Bayes** - للتصنيف النصي
- **Logistic Regression** - نموذج خطي قوي
- **Linear SVM** - Support Vector Machine
- **Random Forest** - Ensemble Learning
مراحل تطوير المشروع
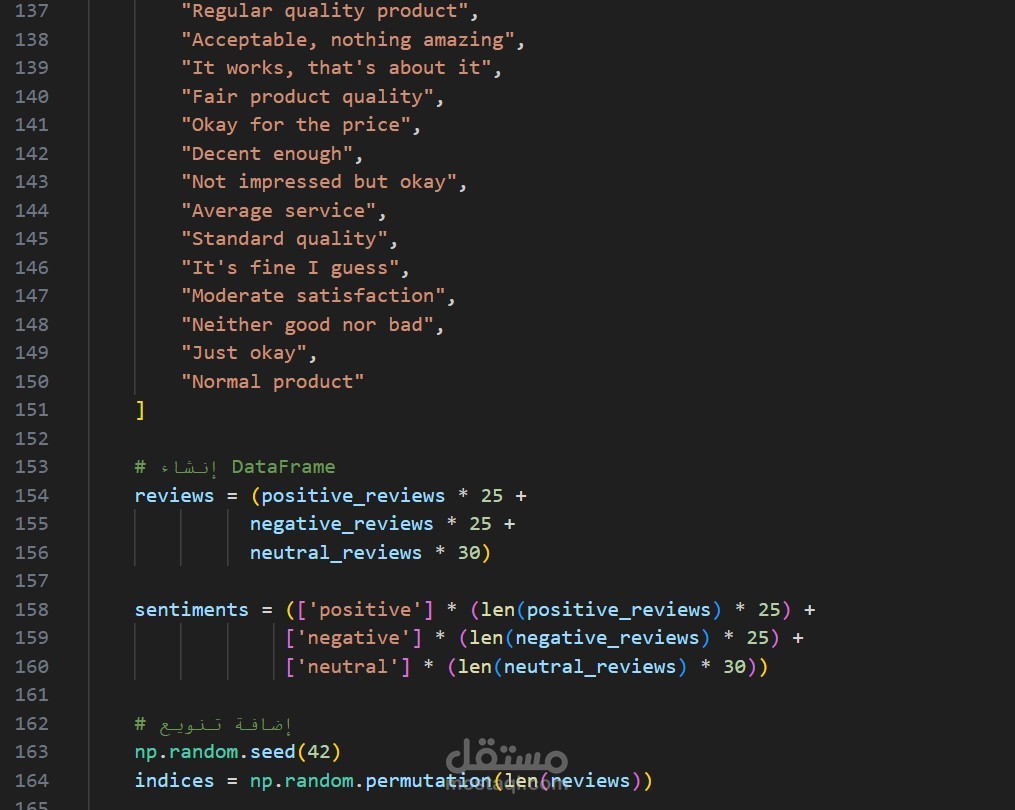
1. جمع وإعداد البيانات
- إنشاء dataset واقعي يحتوي على 2500+ مراجعة
- توزيع متوازن بين المشاعر الثلاثة
- تنويع أنماط الكتابة والمحتوى
- إضافة تقييمات نجمية (Ratings)
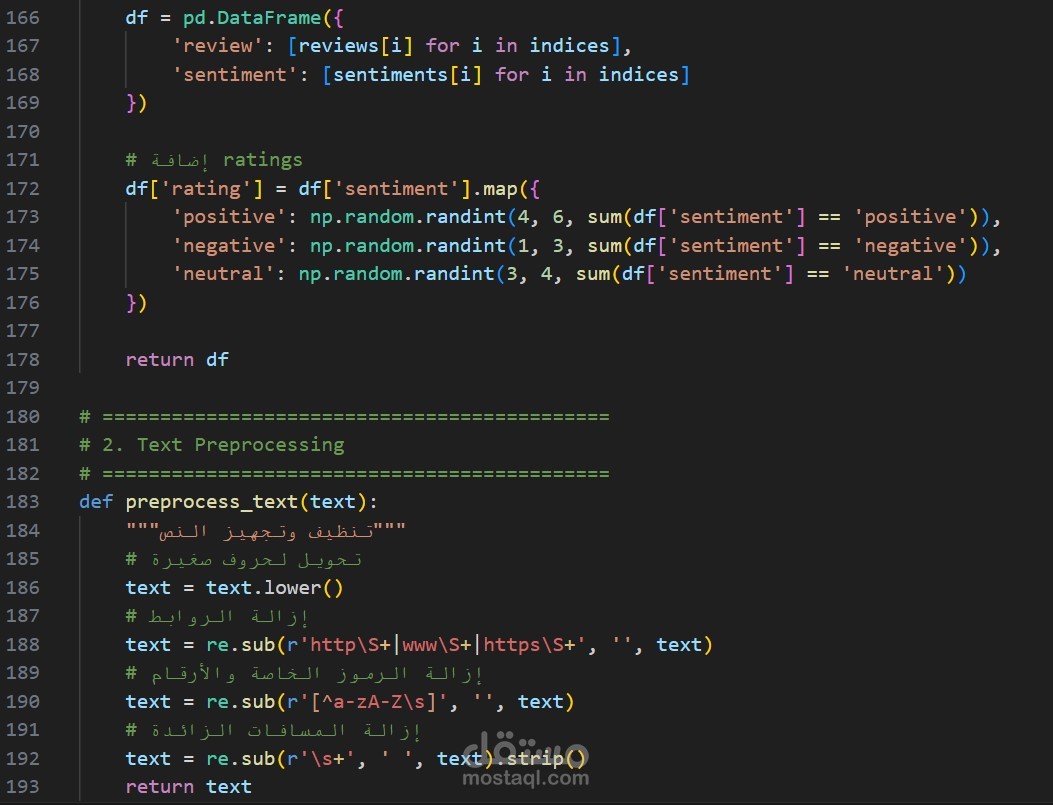
2. معالجة النصوص (Text Preprocessing)
تنظيف شامل للبيانات يشمل:
- **تحويل النص لحروف صغيرة** (Lowercasing)
- **إزالة الروابط والرموز الخاصة** (URL & Special Characters Removal)
- **إزالة الأرقام غير الضرورية** (Number Removal)
- **تنظيف المسافات الزائدة** (Whitespace Normalization)
- **Tokenization** - تقسيم النص لكلمات
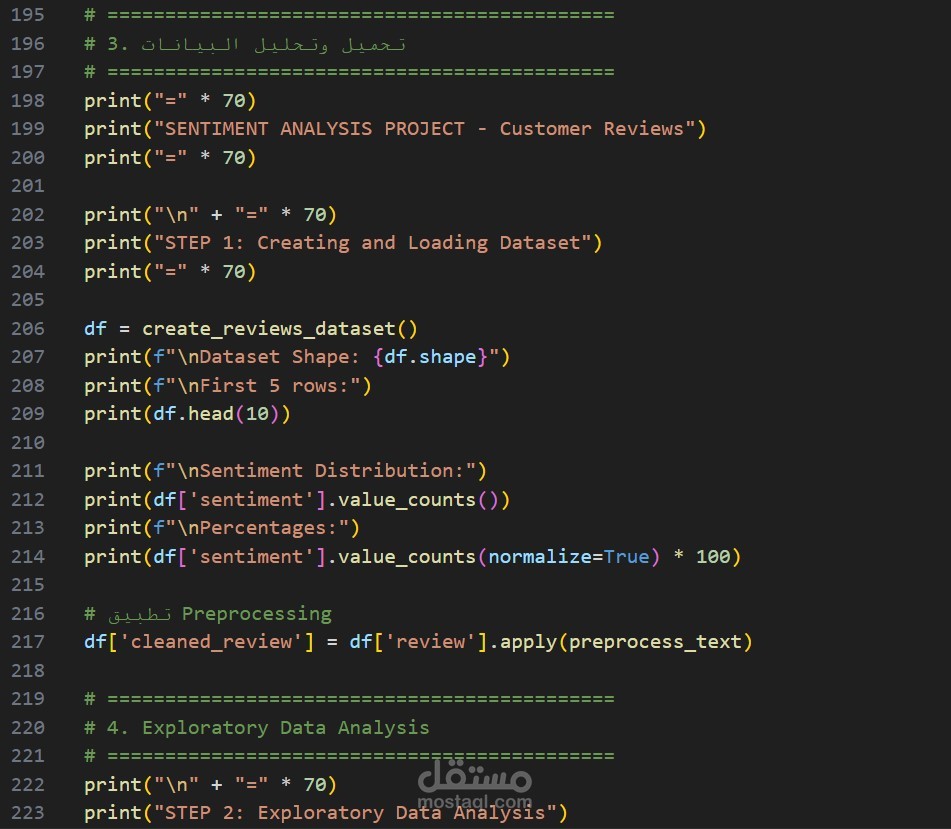
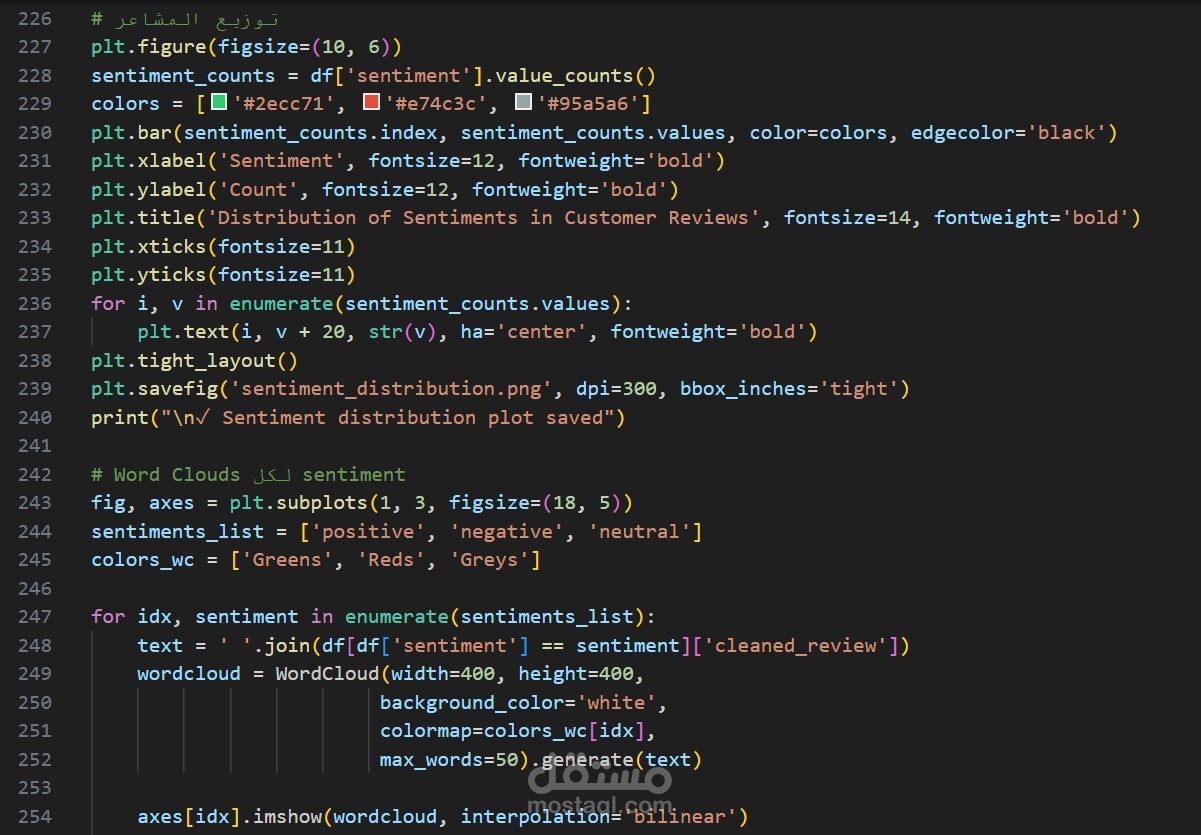
3. تحليل البيانات الاستكشافي (EDA)
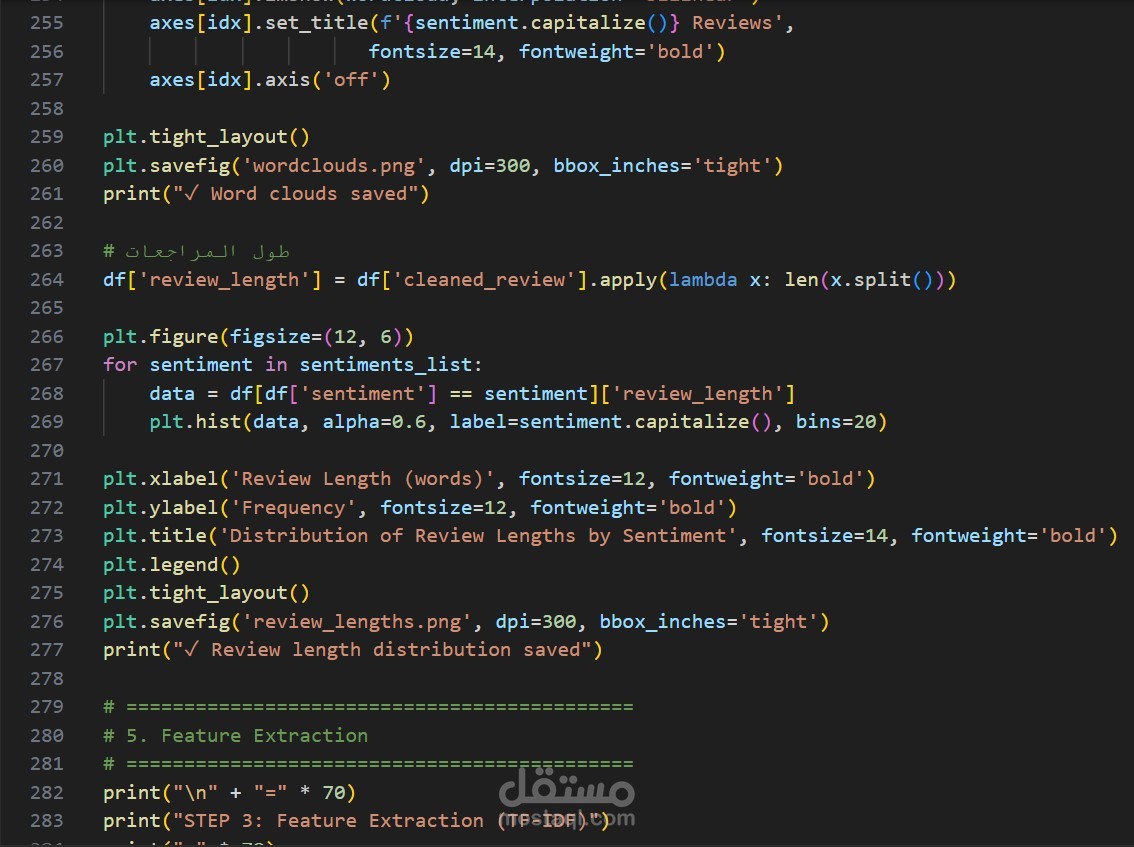
- **توزيع المشاعر** - رسم بياني للتوزيع
- **سحب الكلمات** (Word Clouds) لكل فئة من المشاعر
- **تحليل طول المراجعات** - العلاقة بين الطول والمشاعر
- **الكلمات الأكثر تكراراً** في كل فئة
- **تحليل التقييمات** - العلاقة بين النجوم والمشاعر
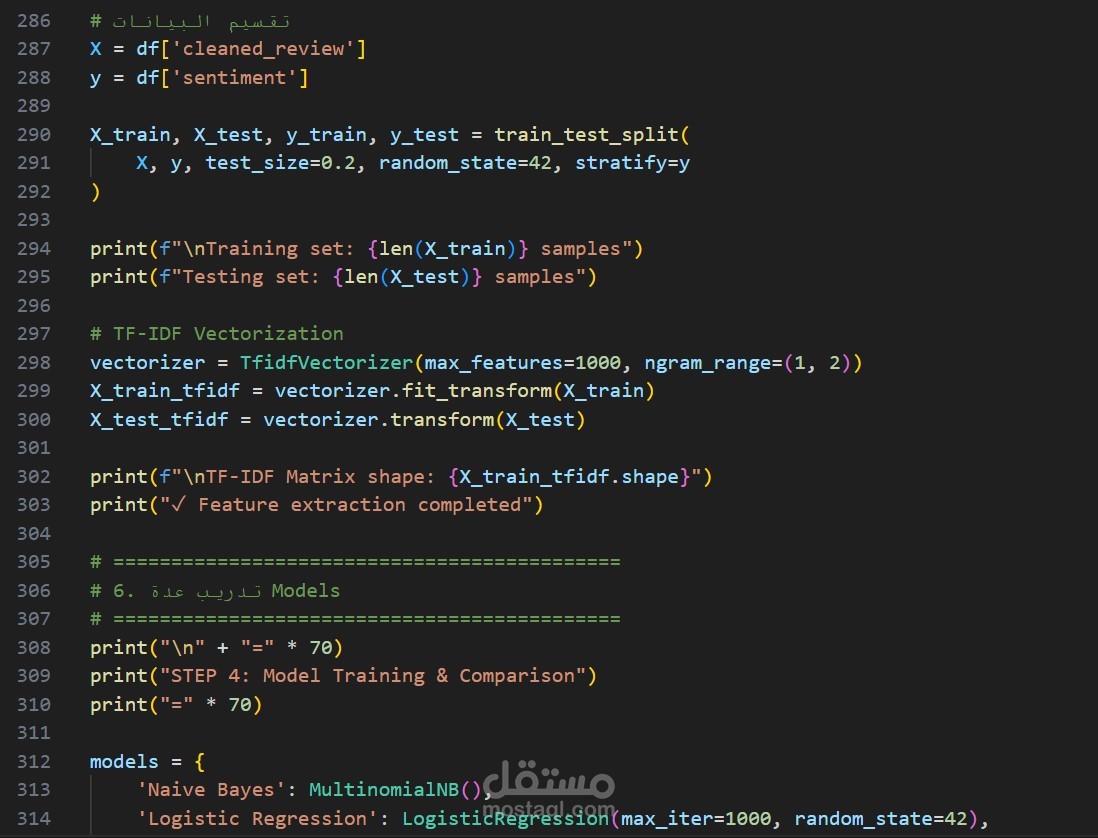
4. استخراج الخصائص (Feature Extraction)
استخدام تقنيات متقدمة:
- **TF-IDF (Term Frequency-Inverse Document Frequency)**
- استخراج 1000 خاصية نصية
- N-grams (1-2) لفهم السياق
- تجاهل الكلمات الشائعة جداً
- **Feature Weighting** - وزن الكلمات حسب أهميتها
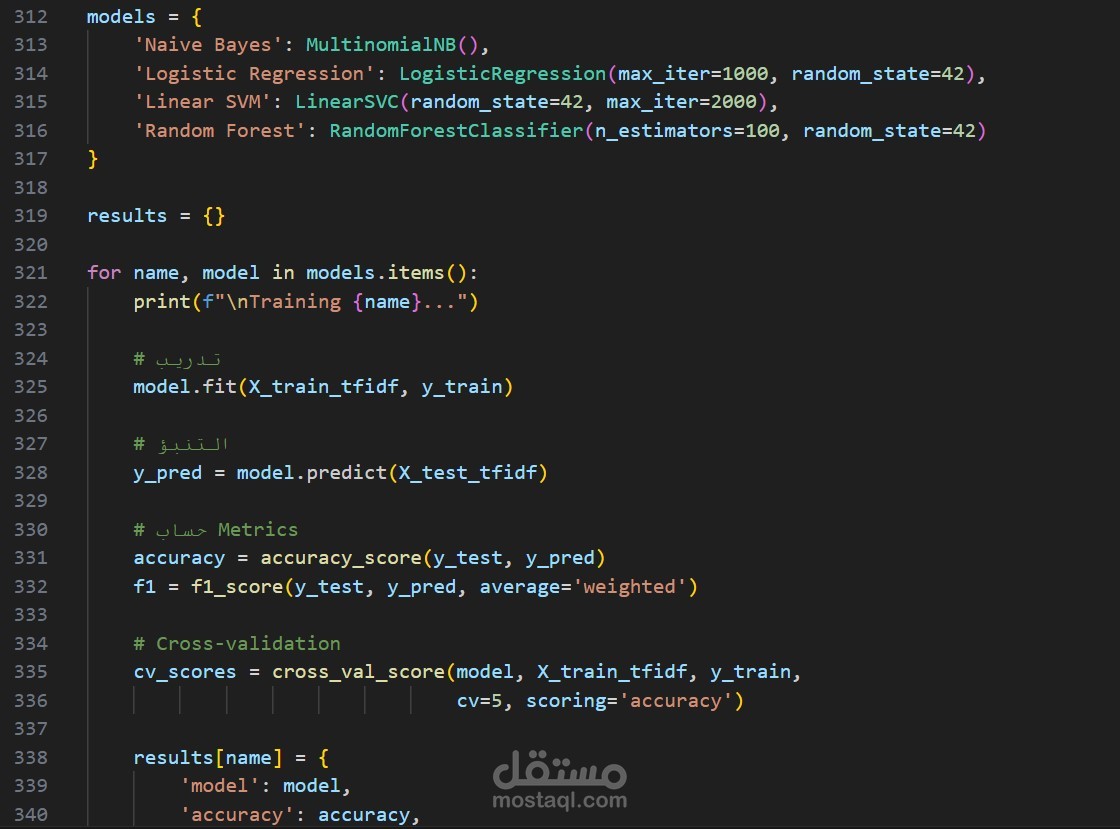
5. بناء وتدريب النماذج
تدريب ومقارنة 4 نماذج مختلفة:
**Naive Bayes:**
- سريع وفعال للتصنيف النصي
- يعمل بشكل ممتاز مع TF-IDF
- مناسب للبيانات النصية
**Logistic Regression:**
- دقة عالية ومستقر
- يعطي احتماليات واضحة
- سهل التفسير
**Linear SVM:**
- قوي في التصنيف متعدد الفئات
- يتعامل مع البيانات عالية الأبعاد
- دقة عالية
**Random Forest:**
- Ensemble Learning قوي
- مقاوم للـ Overfitting
- Feature Importance واضحة
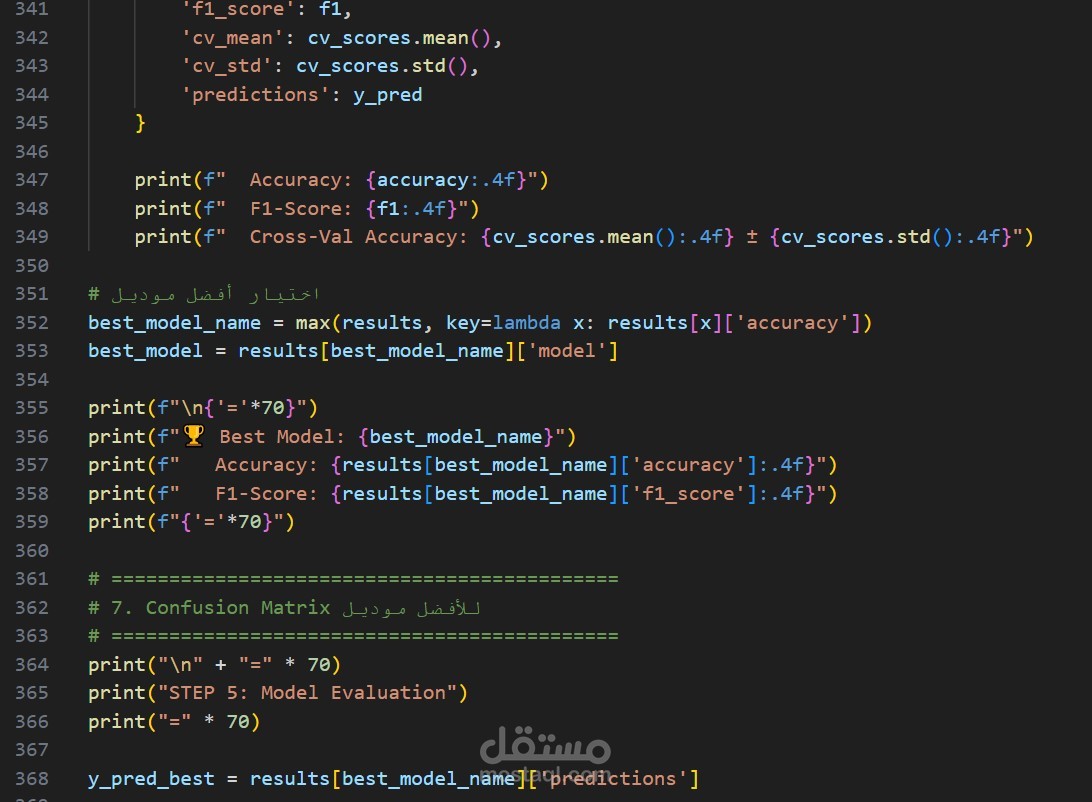
6. تقييم النماذج
استخدام مقاييس متعددة للتقييم:
- **Accuracy** - الدقة الكلية
- **F1-Score** - متوسط موزون للدقة
- **Precision & Recall** - لكل فئة
- **Confusion Matrix** - فهم الأخطاء
- **Cross-Validation** - التأكد من الثبات (5-Fold CV)
- **ROC Curves** - تحليل الأداء
7. تطوير الواجهة التفاعلية
واجهة Gradio احترافية تتضمن:
- **إدخال نصي متعدد الأسطر** للمراجعة
- **تصنيف فوري** للمشاعر
- **عرض نسب الثقة** (Confidence Scores)
- **رسوم بيانية تفاعلية** للاحتماليات
- **ألوان ديناميكية** حسب المشاعر
- **أمثلة جاهزة** للتجربة
- **تصميم responsive** وجذاب