تحليل متكامل لبيانات الكتب واستخلاص الأنماط (Web Scraping & Data Analysis)
تفاصيل العمل
نوع العمل: مشروع استخراج بيانات الويب (Web Scraping) وتحليل بيانات استكشافي (Exploratory Data Analysis - EDA) باستخدام Python.
ميزات العمل وطريقة التنفيذ:
الهدف: بناء نظام متكامل لاستخلاص وتنظيف وتحليل البيانات من موقع متخصص بالكتب، للكشف عن الاتجاهات والأنماط في التسعير، التقييم، والتوافر.
استخلاص البيانات (Web Scraping):
تم استخدام مكتبتي requests و BeautifulSoup لاستخلاص البيانات من 50 صفحة (حوالي 1000 كتاب) من الموقع.
استخلاص حقول أساسية: العنوان (Title)، السعر، التقييم (Rating)، والتوافر (Availability).
تنظيف البيانات وهندسة الميزات (Preprocessing & Feature Engineering):
تم تطبيق دالة clean_text لتنظيف العناوين باستخدام regex.
تم استخدام دالة extract_metadata لاستخلاص البيانات الوصفية المخفية (مثل الإصدار - Edition و التصنيف - Category) من العناوين باستخدام regex.
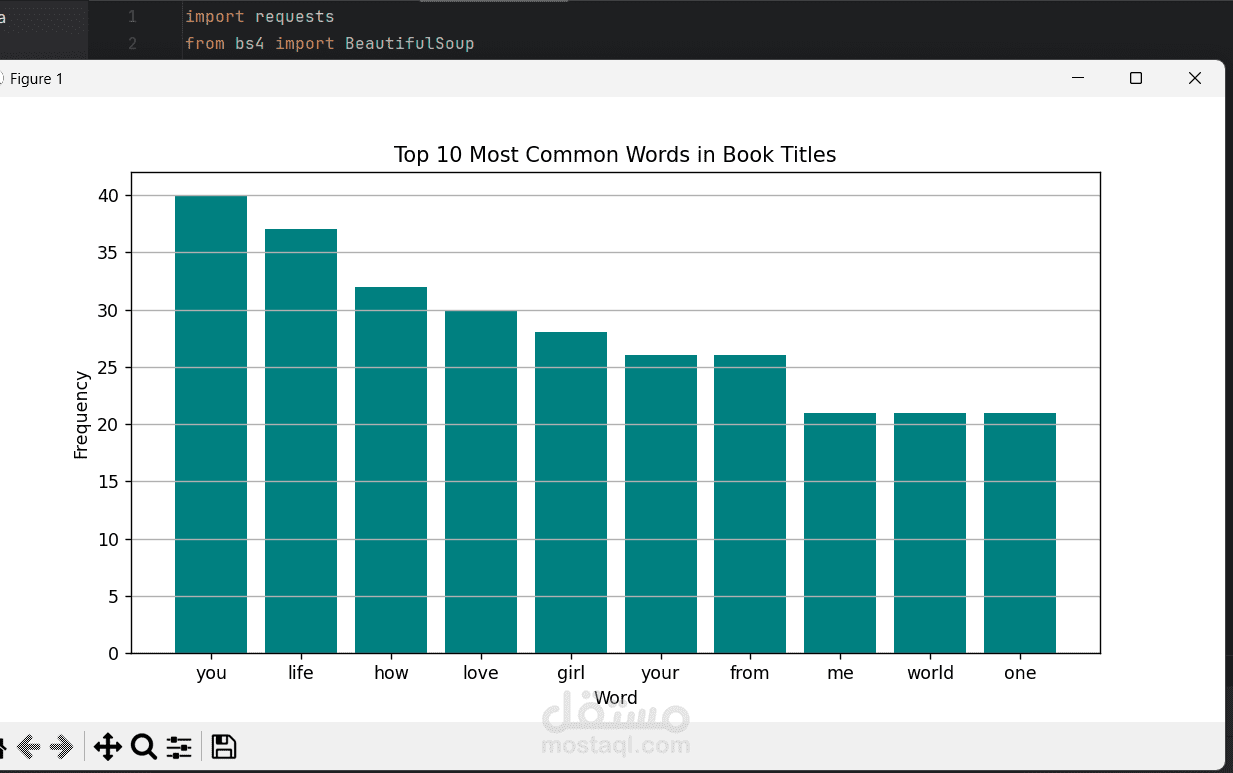
تم إنشاء ميزة Price_Category لتقسيم الأسعار إلى فئات ('Budget', 'Mid-range', 'Premium')، وتحليل توزيع الكلمات الشائع في العناوين.
التحليل وتصور البيانات (Analysis & Visualization):
تم إجراء تحليل إحصائي شامل لتوزيع التقييمات والأسعار.
تم إنشاء رسوم بيانية متنوعة باستخدام matplotlib و pandas لتوضيح العلاقة بين: التقييمات والتوافر، متوسط السعر لكل تقييم، وتوزيع الكلمات الأكثر شيوعًا في العناوين.