التنبؤ بأسعار المساكن في كاليفورنيا (California Housing Price Prediction)
تفاصيل العمل
نوع العمل: مشروع تحليل بيانات وتعلم آلي (Data Analysis and Machine Learning Project).
ميزات العمل وطريقة التنفيذ:
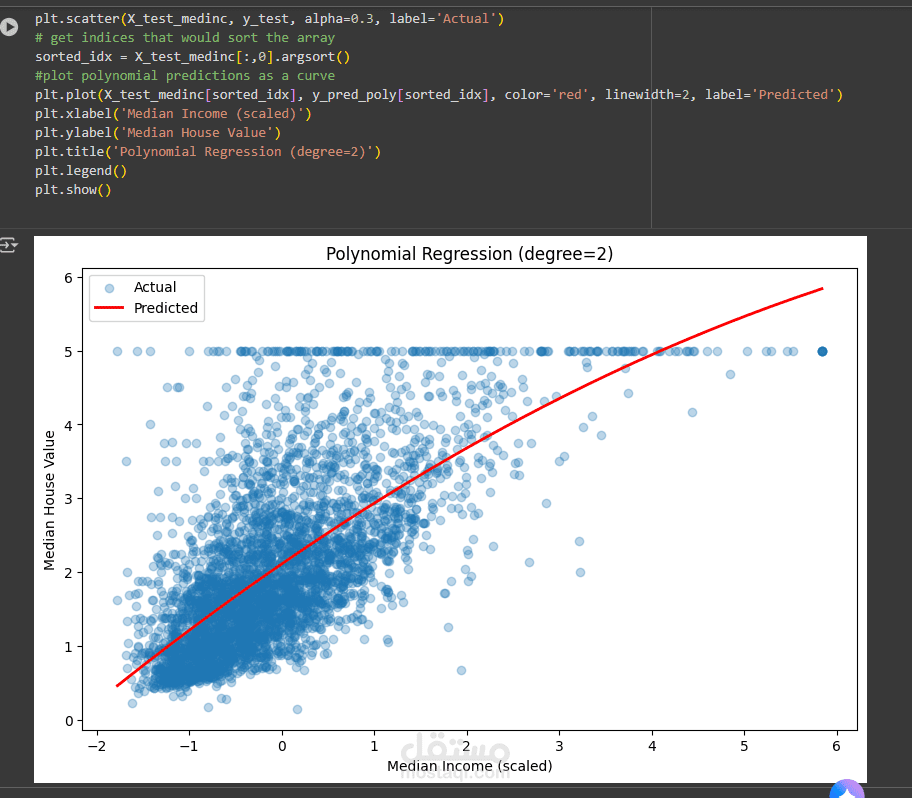
الهدف: بناء وتقييم نماذج انحدار (Regression Models) للتنبؤ بدقة بمتوسط أسعار المساكن في مناطق مختلفة من كاليفورنيا.
المنهجية:
المعالجة المسبقة للبيانات (Data Preprocessing): تنظيف البيانات، التعامل مع القيم المفقودة (missing values)، وتحويل البيانات المتغيرة إلى صيغة مناسبة للنماذج.
تحليل البيانات الاستكشافي (Exploratory Data Analysis - EDA): تحليل مرئي لتوزيع المتغير المستهدف (أسعار المنازل) والمتغيرات الأخرى، ورسم خرائط للتوزيع الجغرافي للبيانات.
تطوير النماذج: تم بناء وتنفيذ نماذج الانحدار الخطي (Linear Regression) ونماذج الانحدار اللوجستي (Logistic Regression) باستخدام مكتبة scikit-learn في بايثون.
التقييم: تم تقييم أداء النماذج باستخدام مقاييس مناسبة مثل خطأ المتوسط التربيعي (MSE) و
R
2
Score لتحديد النموذج الأفضل أداءً.