تنظيف البيانات
تفاصيل العمل
"مقدمة في تنظيف البيانات، وتحليل البيانات الاستكشافي، والتعلم الآلي"، تُقدم تدريبًا عمليًا على:
تنظيف البيانات
معالجة القيم المفقودة
اكتشاف ومعالجة القيم المتطرفة
إعداد مجموعة البيانات لتحليل البيانات الاستكشافي (EDA) والتعلم الآلي.
تحتوي مجموعة البيانات على معلومات ديموغرافية وأكاديمية عن الطلاب:
التناقضات (مثل: "Male" vs. "M", "Barrrchelors" vs. "Bachelor", "Rsa" vs. "RSA").
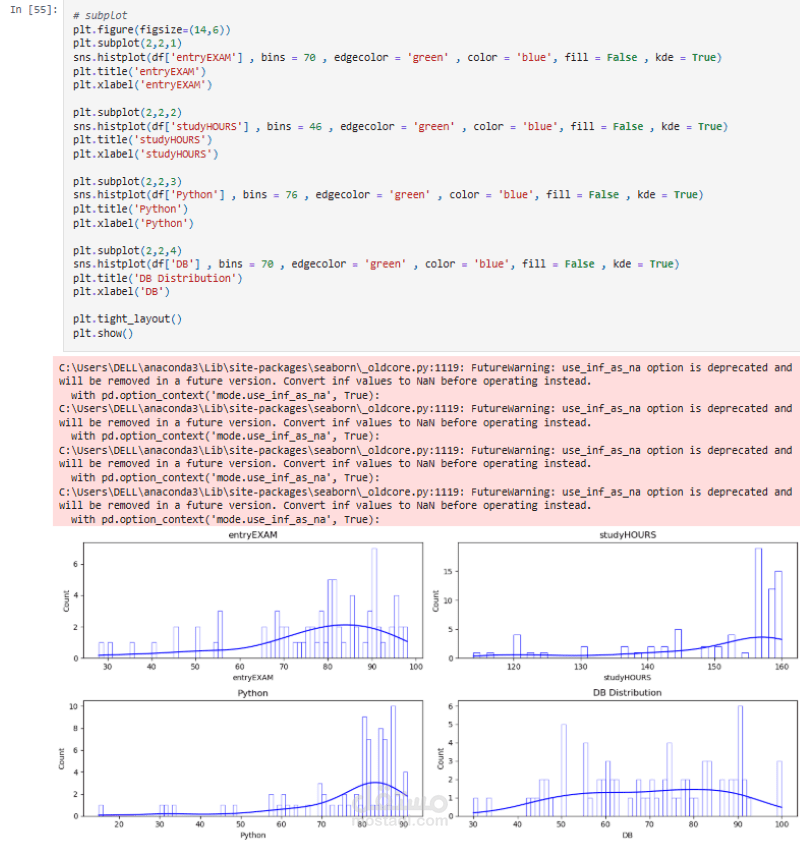
القيم المفقودة (خاصةً في درجات بايثون وقواعد البيانات).
القيم المتطرفة (قيم غير واقعية في ساعات الدراسة ودرجات الأداء).
تنظيف البيانات
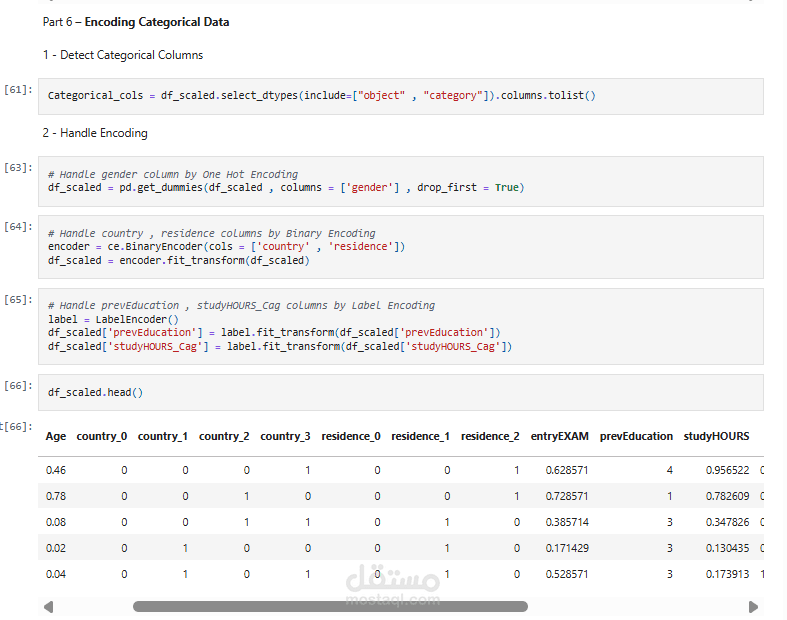
عمود الجنس ← القيم الموحدة لـ"M" and "F".
عمود الدولة ← تصحيح الأحرف الكبيرة غير المتناسقة (مثل: "norway" → "Norway")
عمود التعليم السابق ← تصحيح الأخطاء المطبعية ("Barrrchelors" → "Bachelor") واختلافات الدبلوم الموحدة.
التكرارات ← تم التحقق منها باستخدام df.duplicated().sum() وحذفها باستخدام df.drop_duplicates().
معالجة البيانات المفقودة
الأعمدة الرقمية (بايثون):
تم اختبار المتوسط الحسابي والوسيط الحسابي لملء القيم المفقودة.
لكنني استخدمت الوسيط.
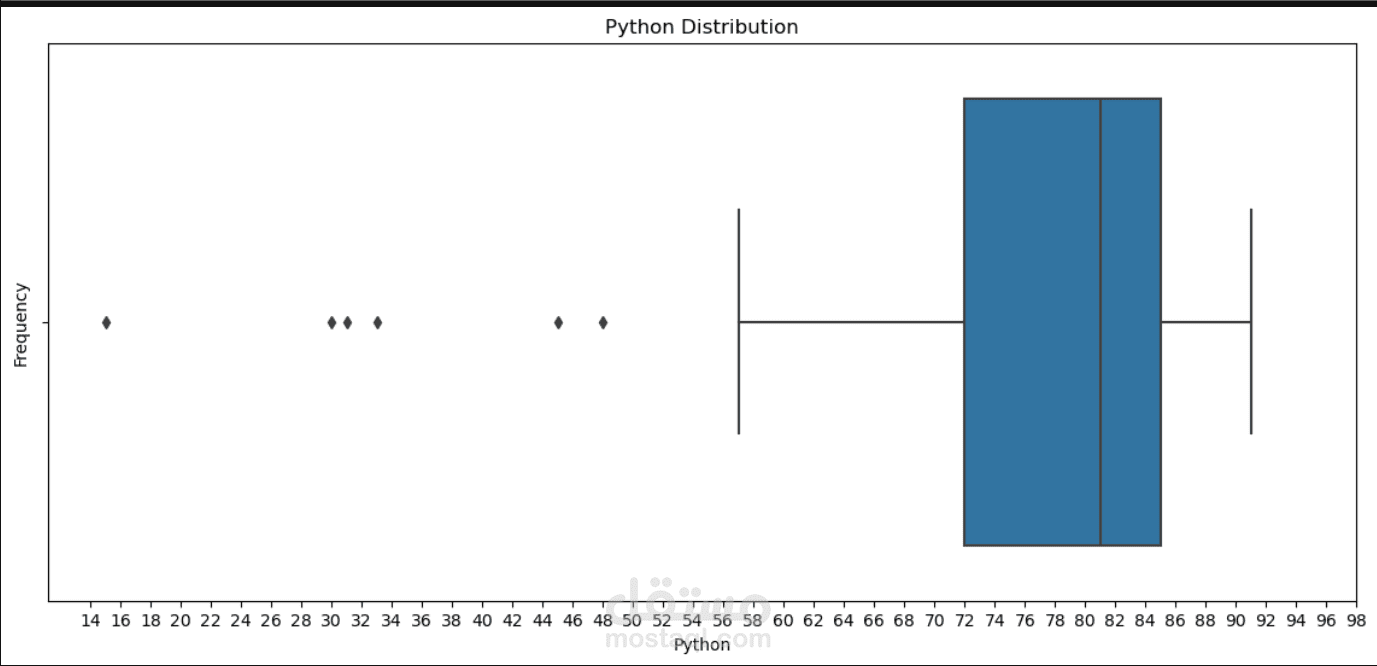
القيم المتطرفة
الكشف:
تم استخدام مخططات الصندوق (sns.boxplot) وطريقة IQR.
خيارات المعالجة:
التعامل معها كقيم واقعية.