Book Data Scraping & Analysis
تفاصيل العمل
الهدف:
تحديد موقع إلكتروني مستهدف واستخراج البيانات المتعلقة بالكتب مثل العناوين، الأسعار، التقييمات، مدى التوفر، وروابط المنتجات.
الخطوات المنفذة:
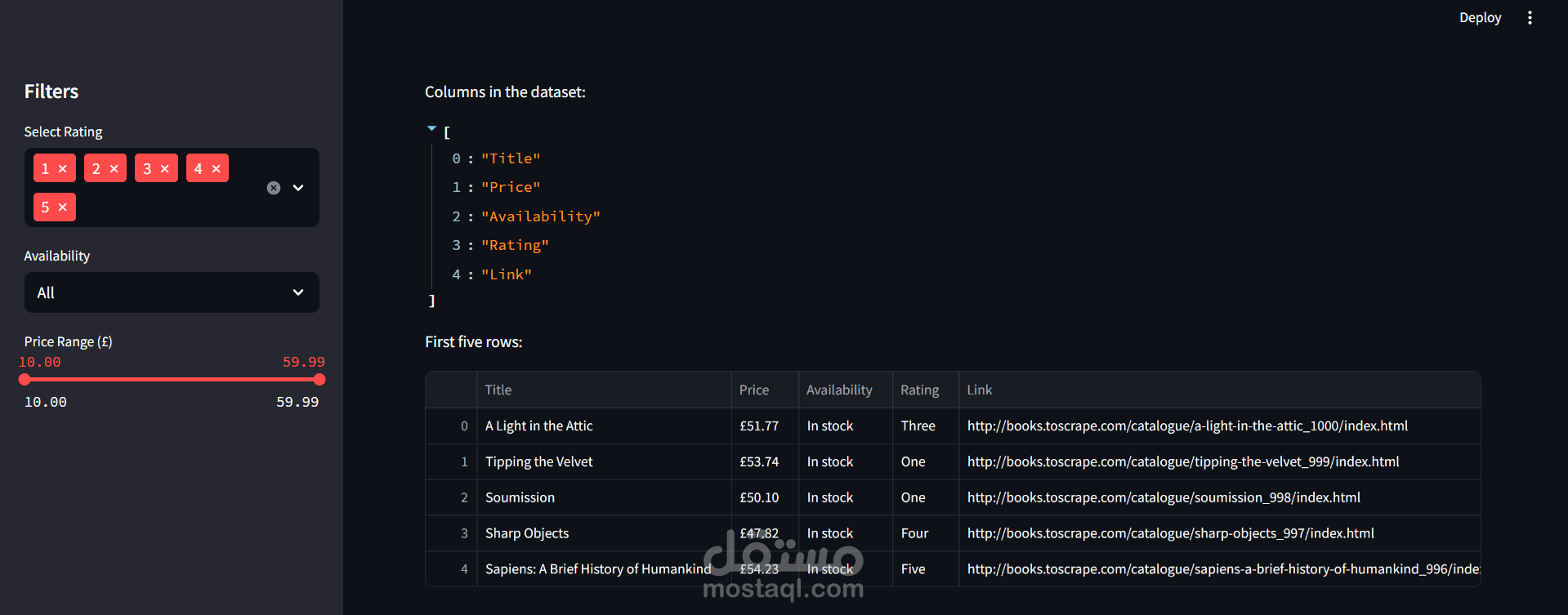
1. جمع البيانات (Web Scraping):
تم استخدام تقنيات BeautifulSoup و Selenium لاستخراج البيانات من الموقع المستهدف.
تم جمع بيانات الكتب مثل: العنوان، السعر، التقييم، مدى التوفر، والرابط الخاص بكل كتاب.
حفظ البيانات الأولية في ملف CSV منظم لمرحلة التحليل اللاحقة.
2. تنظيف البيانات ومعالجتها (Data Cleaning & Regex):
إزالة القيم الخاطئة أو غير الضرورية من مجموعة البيانات.
استخدام التعبيرات النمطية (Regular Expressions) لاستخراج وتنقية المعلومات النصية (مثل الأسعار أو التواريخ أو الأوصاف).
3. تحليل البيانات (Data Analysis):
حساب إحصاءات أساسية مثل متوسط الأسعار والتقييمات.
تحليل العلاقات بين المتغيرات (مثل العلاقة بين السعر والتقييم).
دراسة توزيع التقييمات والأنماط العامة في البيانات.
4. تصور البيانات (Data Visualization):
إنشاء رسوم بيانية متنوعة مثل المخططات الشريطية والخطية والخرائط الحرارية باستخدام Matplotlib و Seaborn.
تقديم النتائج بشكل تفاعلي وواضح.
5. تخزين البيانات (Data Storage):
تخزين البيانات بعد المعالجة في قاعدة بيانات SQLite لسهولة الوصول والاستخدام لاحقًا.
6. تطوير تطبيق ويب تفاعلي (Interactive Web App):
تم إنشاء تطبيق تفاعلي باستخدام Streamlit لعرض النتائج بشكل ديناميكي.
يسمح التطبيق للمستخدمين باستكشاف البيانات والتفاعل مع الرسوم البيانية بسهولة.
التقنيات المستخدمة:
Python (اللغة الأساسية للمشروع)
BeautifulSoup / Selenium – لجمع البيانات من الويب
Pandas – لمعالجة البيانات
Regular Expressions (Regex) – لمعالجة النصوص
Matplotlib / Seaborn – لتصور البيانات
SQLite – لتخزين البيانات
Streamlit – لبناء واجهة الويب التفاعلية