Data Scraping Projects – Amazon Electronics & Movies
تفاصيل العمل
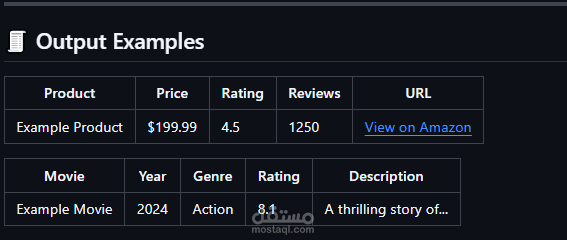
This project focuses on building two Python-based web scraping pipelines to collect and organize real-world data from online sources.
The first notebook scrapes Amazon Electronics data, extracting details such as product names, prices, ratings, and reviews.
The second notebook scrapes movie-related data (titles, genres, ratings, etc.) from a movie website.
Both scripts demonstrate strong practical skills in:
Automating data extraction using requests and BeautifulSoup.
Cleaning and structuring raw data with pandas.
Exporting results into CSV files ready for analysis or integration with other data systems.
This project highlights the ability to build reliable and efficient scraping workflows — a key step in any data engineering or data collection pipeline.