تحليل ومقارنة خوارزميات الانحدار للتنبؤ بأسعار المنازل
تفاصيل العمل

هذا المشروع عبارة عن دفتر ملاحظات (Jupyter Notebook) لتحليل بيانات أسعار المنازل في الولايات المتحدة الأمريكية. الهدف الرئيسي هو استكشاف البيانات، وفهم العوامل التي تؤثر على أسعار المنازل، ومن ثم تجهيز هذه البيانات لبناء نماذج تعلم آلي (Machine Learning) قادرة على التنبؤ بالأسعار.
يمكن تلخيص خطوات المشروع كما يلي:
1. إعداد بيئة العمل واستيراد البيانات
استيراد المكتبات: بدأ المشروع باستيراد المكتبات الأساسية في علم البيانات بلغة بايثون، مثل:
pandas لمعالجة البيانات والجداول.
numpy للعمليات الحسابية.
matplotlib و seaborn لإنشاء الرسوم البيانية والتصورات.
scikit-learn لتجهيز البيانات وبناء نماذج التعلم الآلي.
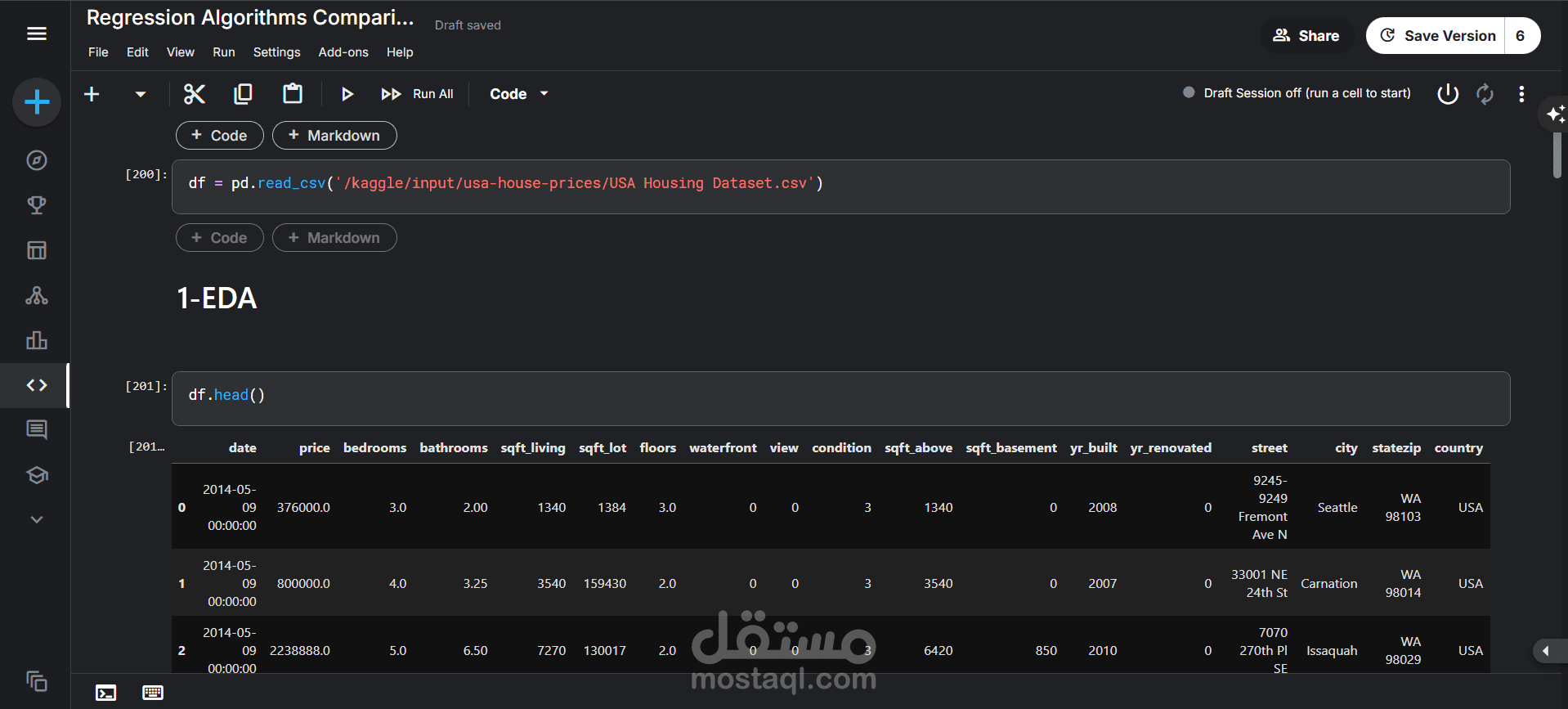
تحميل البيانات: تم تحميل مجموعة البيانات من ملف CSV باسم USA_Housing_Dataset.csv إلى DataFrame باستخدام مكتبة pandas.
2. استكشاف البيانات وتنظيفها (Data Exploration and Cleaning)
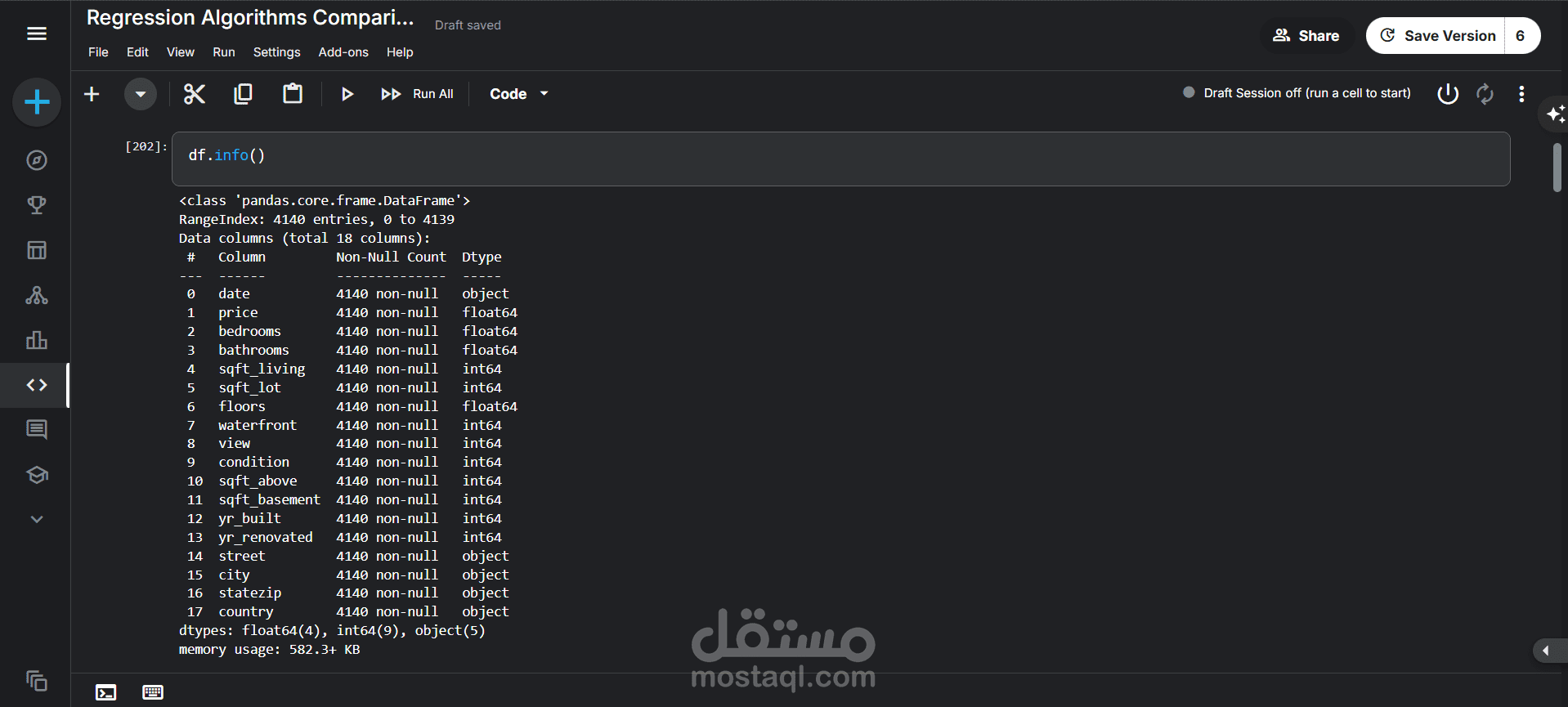
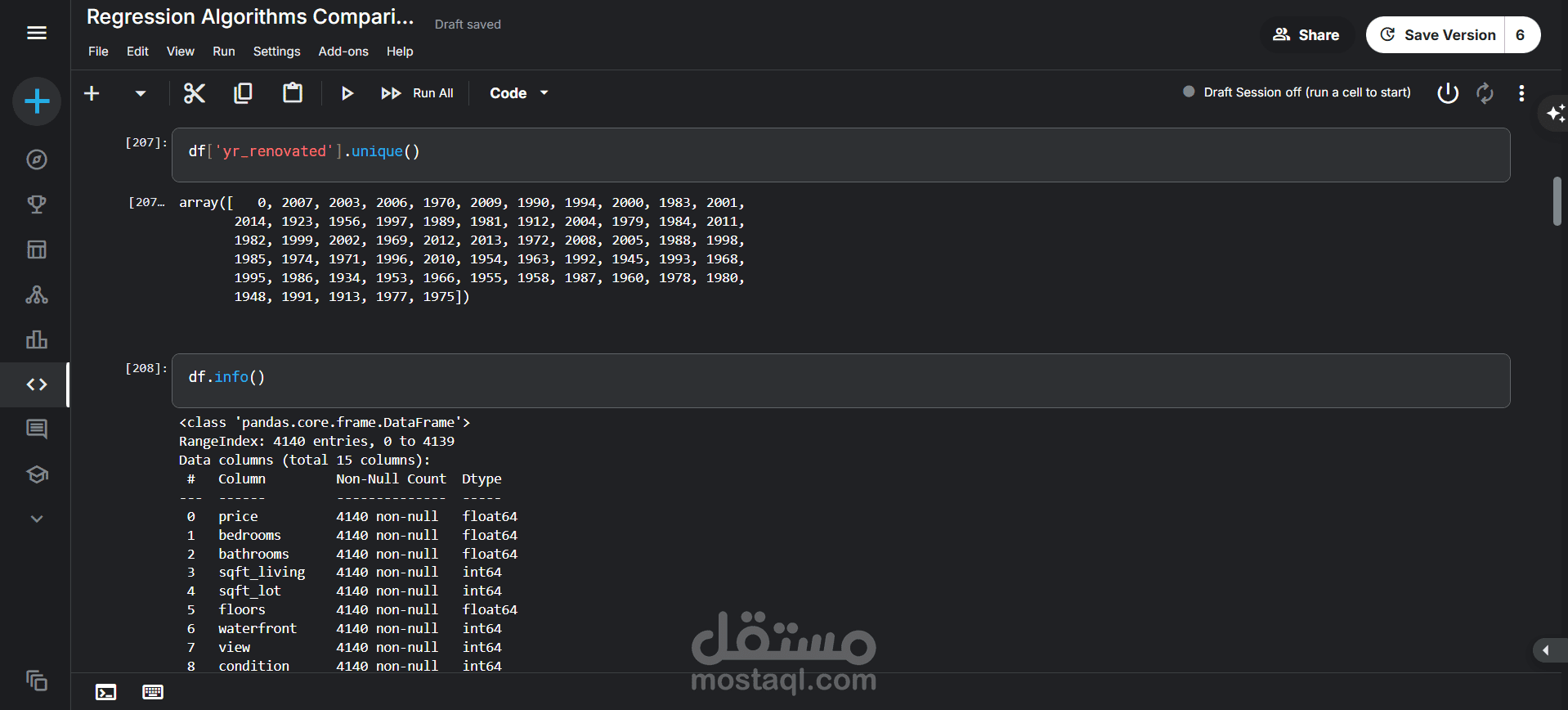
فحص البيانات: تم استخدام دالتي df.head() و df.info() لإلقاء نظرة أولية على البيانات. كشف هذا الفحص عن:
وجود 4140 سجلاً (صفاً) و 18 عموداً (ميزة).
عدم وجود أي قيم مفقودة (Non-Null) في البيانات، مما يسهل عملية التحليل.
أنواع البيانات المختلفة لكل عمود (أرقام صحيحة int64، أرقام عشرية float64، ونصوص object).
تنظيف البيانات (Data Cleaning): تم اتخاذ عدة قرارات لتبسيط مجموعة البيانات:
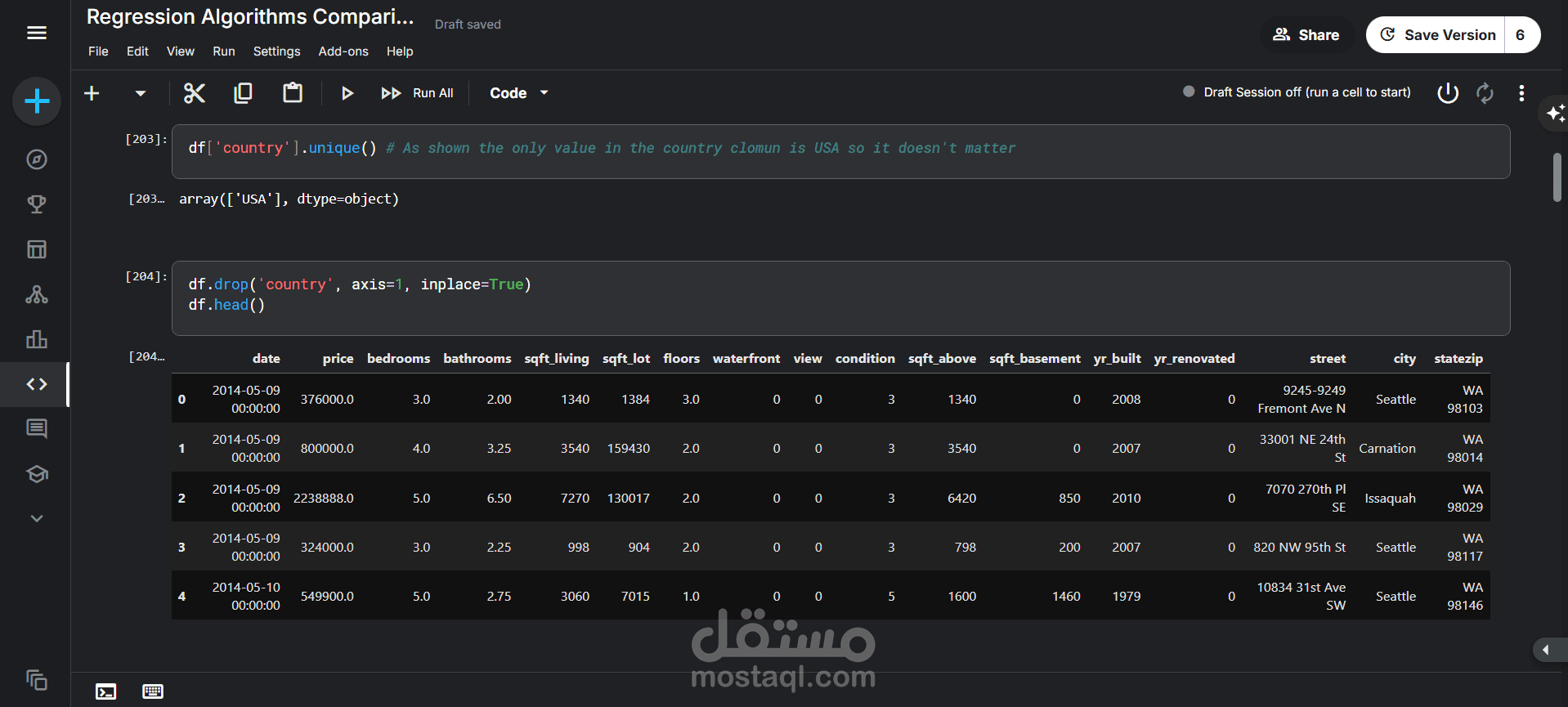
حذف عمود country: بما أن جميع المنازل تقع في "USA"، فهذا العمود لا يقدم أي قيمة تنبؤية وتم حذفه.
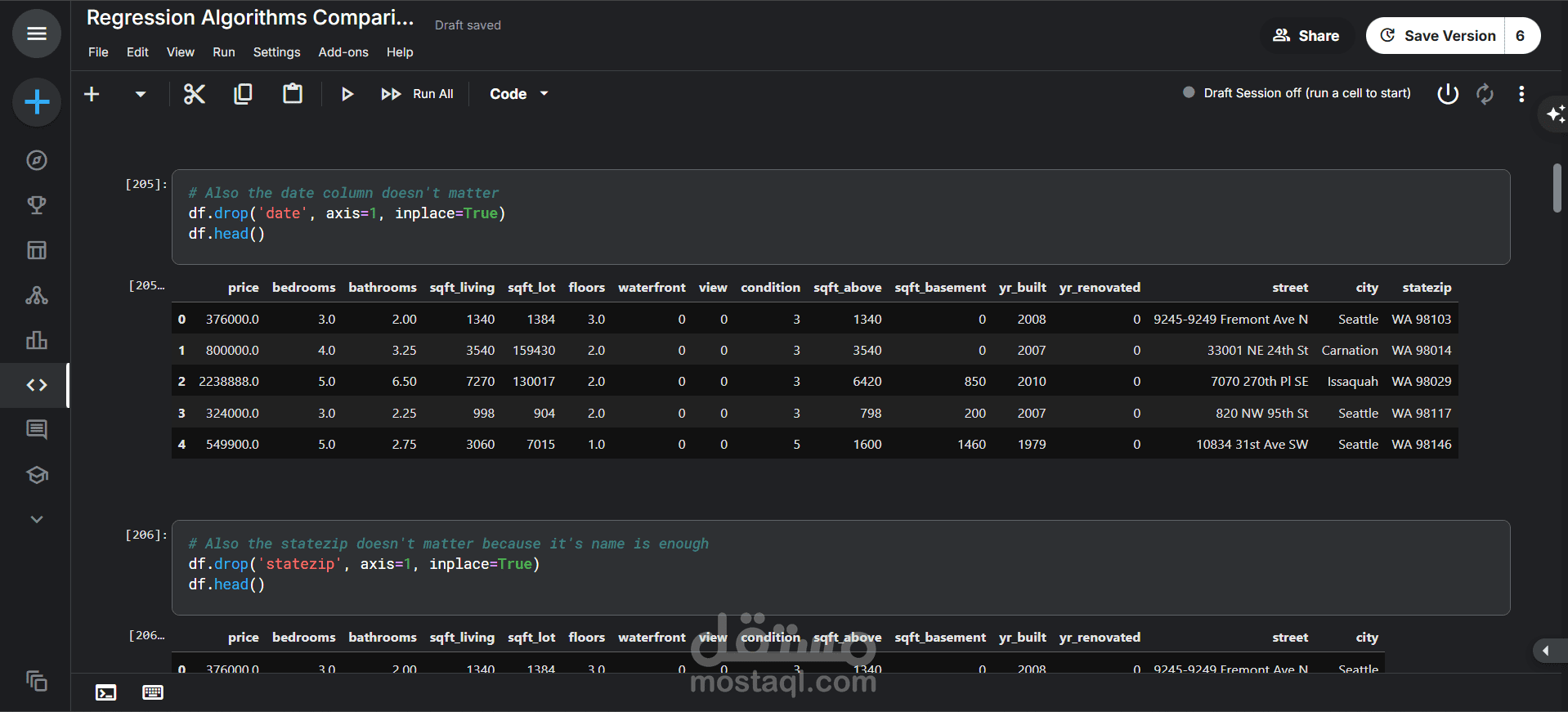
حذف عمود date: تم حذف عمود التاريخ، ربما لاعتباره غير مؤثر بشكل مباشر في التحليل الحالي.
حذف عمود statezip: تم حذفه أيضاً، ربما لوجود معلومات كافية في عمود المدينة (city).
3. التحليل الاستكشافي للبيانات (Exploratory Data Analysis - EDA)
هذه هي المرحلة التي تم فيها تحليل العلاقات بين المتغيرات المختلفة والسعر (price) باستخدام الرسوم البيانية:
اكتشاف القيم الشاذة (Outliers): تم استخدام مخططات الصندوق (Box Plots) لتحديد القيم المتطرفة في الأعمدة الرقمية مثل price, sqft_living, sqft_lot. أظهرت المخططات وجود العديد من القيم الشاذة، وهو أمر شائع في بيانات العقارات.
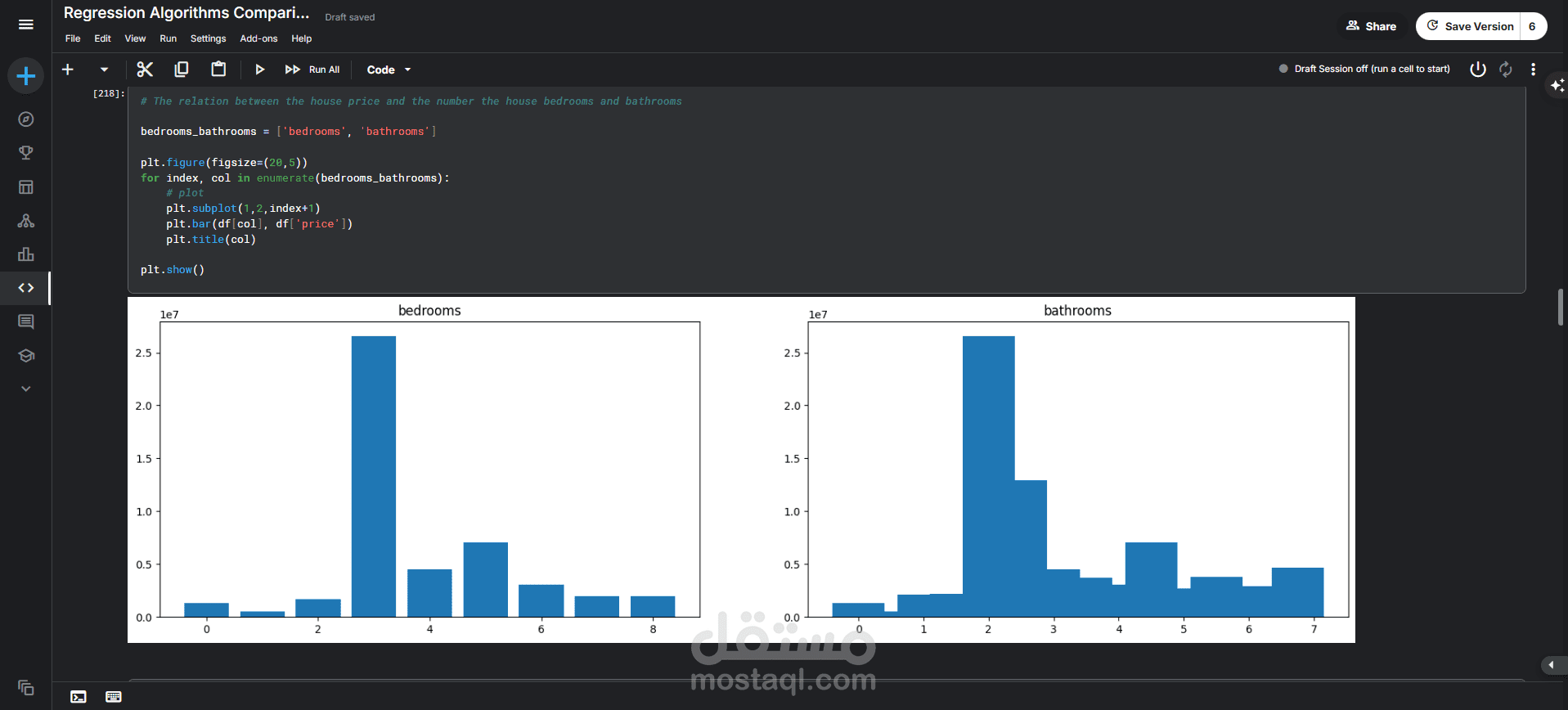
العلاقة بين السعر وعدد غرف النوم والحمامات: تم استخدام المخططات الشريطية (Bar Plots) لفحص هذه العلاقة. أظهرت النتائج أن السعر يميل إلى الزيادة مع زيادة عدد الحمامات، بينما العلاقة مع عدد غرف النوم ليست خطية تماماً.
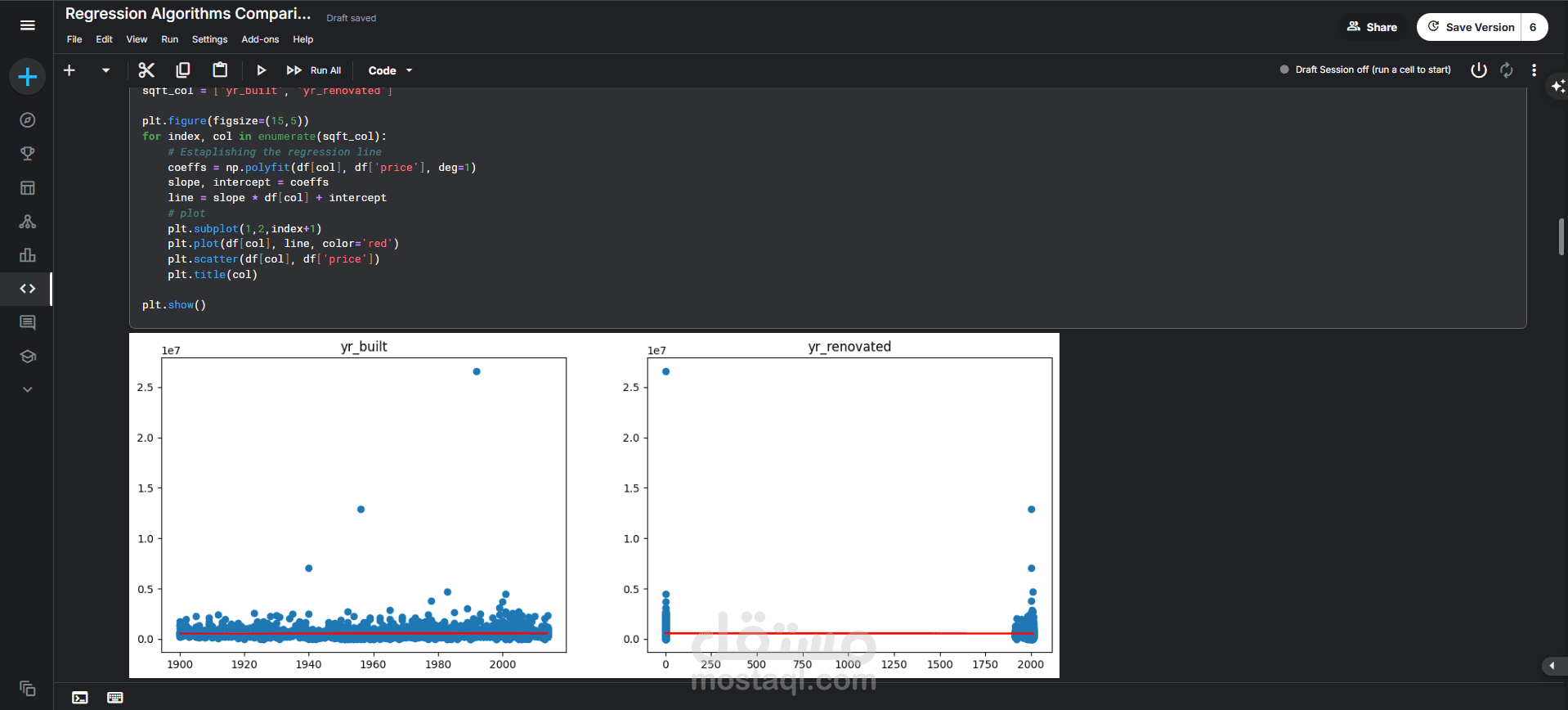
العلاقة بين السعر وسنة البناء والتجديد: أظهرت مخططات التشتت (Scatter Plots) عدم وجود علاقة خطية واضحة وقوية بين سعر المنزل وسنة بنائه أو سنة تجديده. معظم المنازل لم يتم تجديدها (القيمة yr_renovated تساوي صفر).
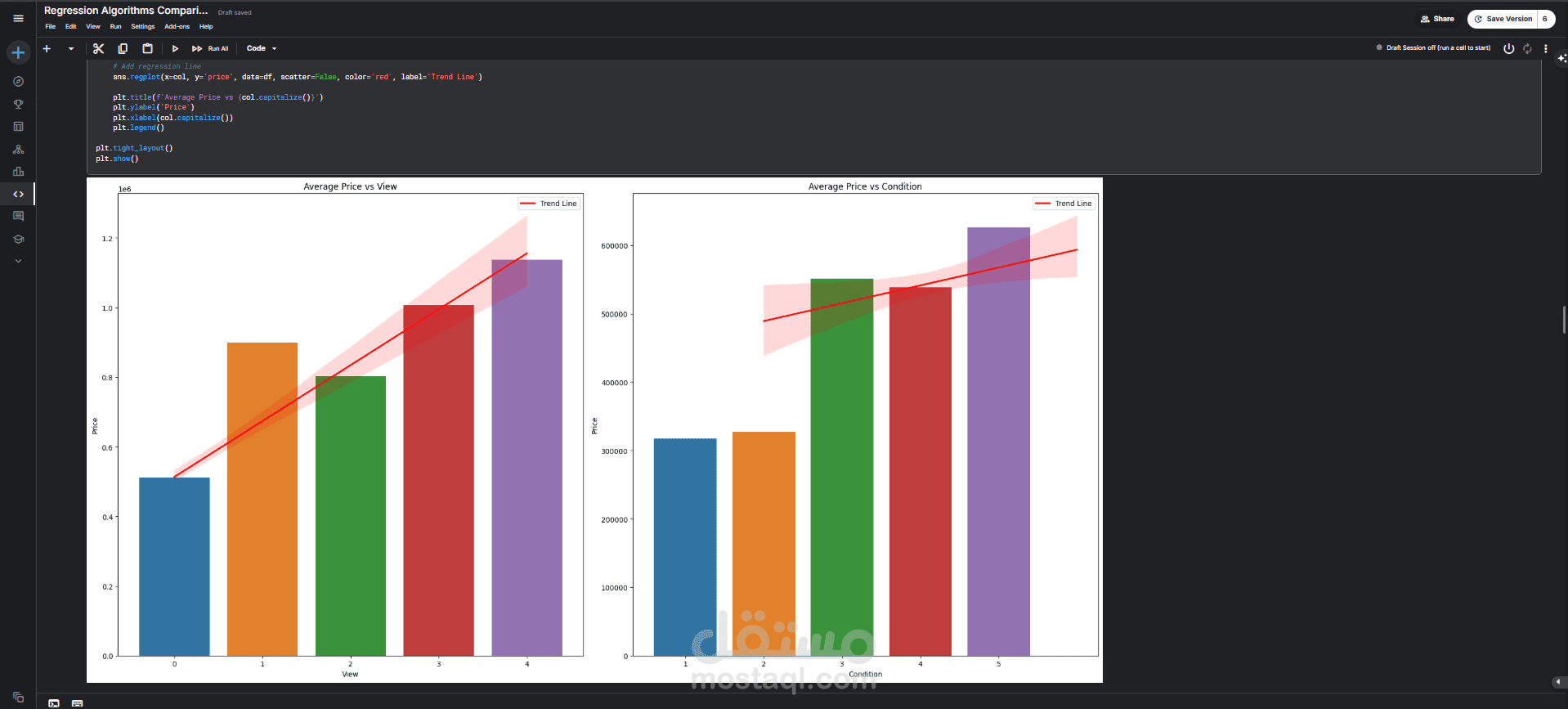
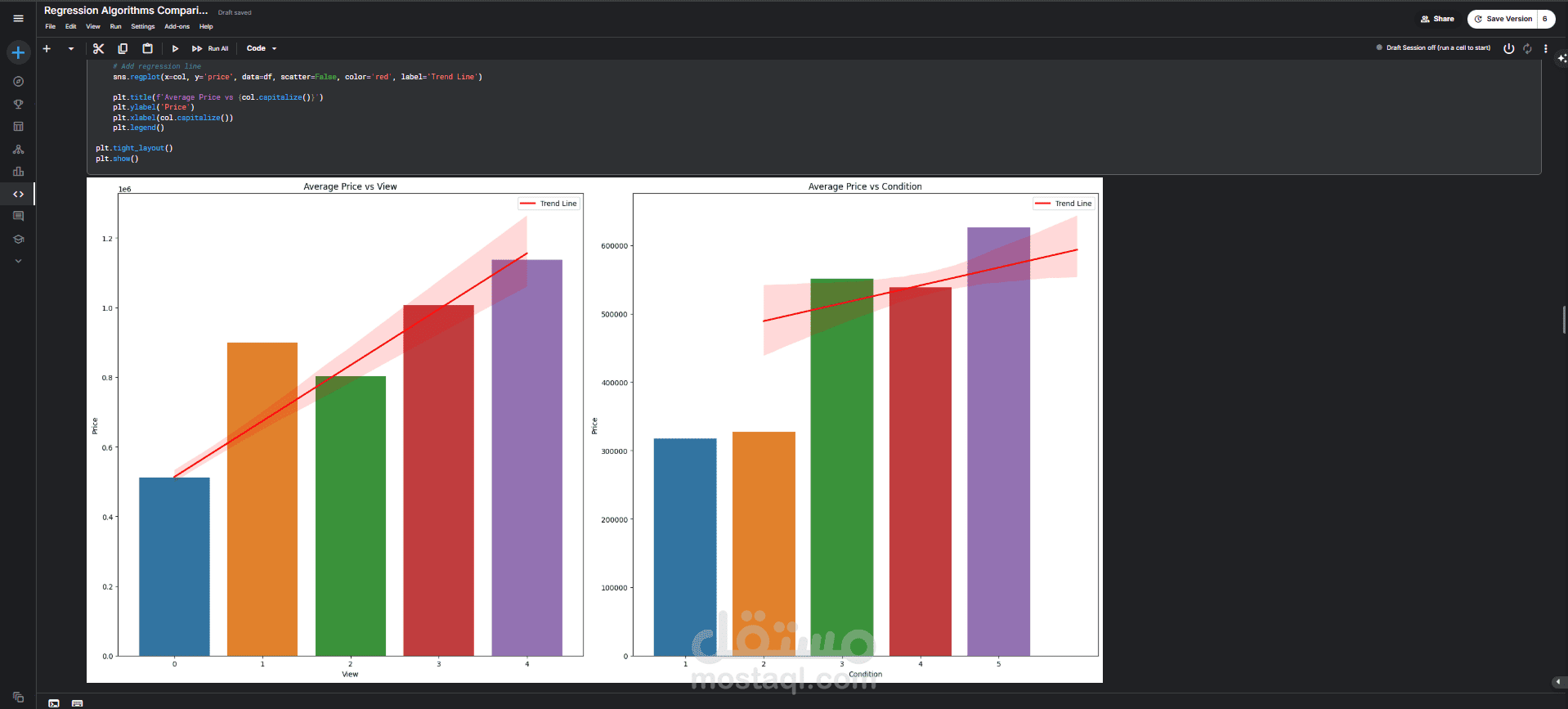
العلاقة بين السعر وجودة الإطلالة وحالة المنزل: تم استخدام مخططات شريطية مع خط اتجاه (Trend Line). أظهرت هذه المخططات وجود علاقة طردية قوية:
كلما زادت جودة الإطلالة (view)، زاد متوسط سعر المنزل.
كلما كانت حالة المنزل (condition) أفضل، زاد متوسط سعره.
الهدف النهائي للمشروع
الخطوات المعروضة في الصور هي خطوات تحضيرية أساسية. الهدف النهائي من هذا المشروع، كما يوحي اسمه "Regression Algorithms Comparison"، هو:
تجهيز البيانات النهائية: تحويل الأعمدة النصية (مثل city) إلى أرقام، وتوحيد مقياس المتغيرات الرقمية (Scaling).
تقسيم البيانات: فصل البيانات إلى مجموعة تدريب (Training set) ومجموعة اختبار (Test set).
بناء وتدريب نماذج الانحدار (Regression Models): تدريب عدة خوارزميات مثل الانحدار الخطي (Linear Regression)، أشجار القرار (Decision Trees)، وغيرها على بيانات التدريب.
تقييم ومقارنة النماذج: استخدام مجموعة الاختبار لتقييم أداء كل نموذج واختيار أفضلها للتنبؤ بأسعار المنازل.
باختصار، المشروع يمر بكامل دورة حياة مشروع علم البيانات، بدءًا من فهم البيانات وتنظيفها، مرورًا بتحليلها بصريًا، وانتهاءً بالتحضير لبناء نماذج تنبؤية دقيقة.