web scraping application
تفاصيل العمل


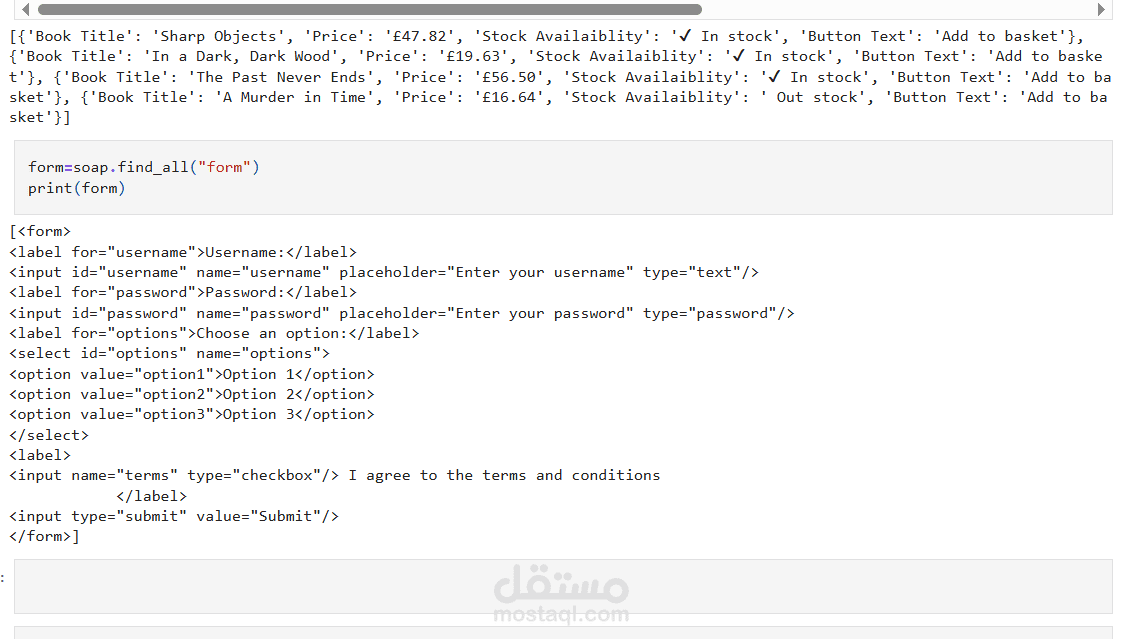
This project is a web scraping application built with Python that extracts and processes data from websites automatically. It uses the powerful library BeautifulSoup to parse and navigate HTML content, making it easy to collect specific pieces of information from web pages.
The main purpose of the project is to collect, organize, and analyze data from the web without manual effort. It’s especially useful for tasks like gathering product details, prices, news articles, job listings, or any other public information available online.