KNN in ML
تفاصيل العمل
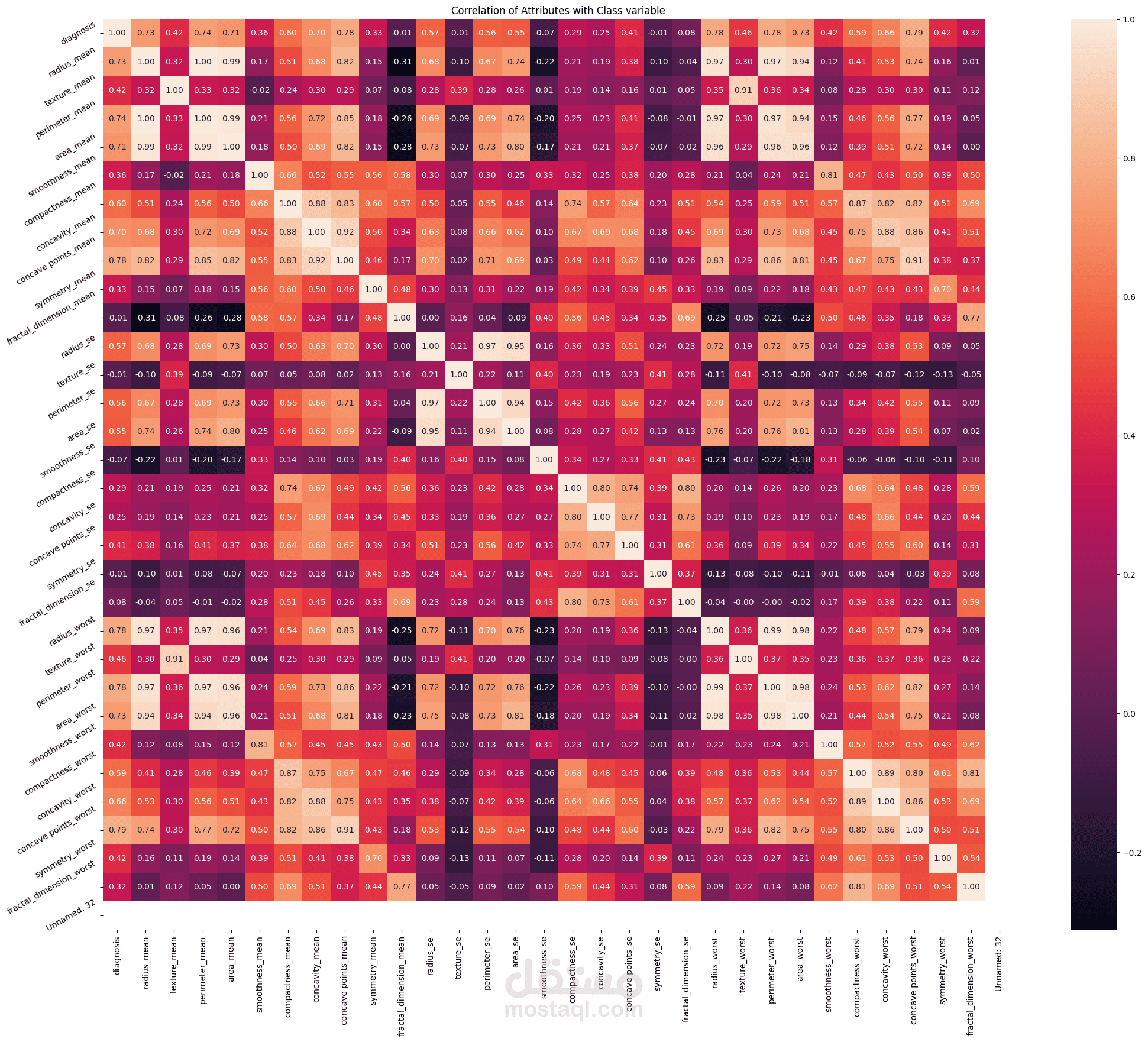
هذه الدراسة حالة عملية متكاملة في مجال التعلم الآلي (Machine Learning)، حيث قمت بتصميم وبناء نموذج تصنيفي قوي باستخدام خوارزمية k-Nearest Neighbors (kNN). الهدف كان تطوير نظام قادر على التنبؤ بدقة عالية (تصنيف) ما إذا كانت عينة من ورم الثدي حميدة (Benign) أو خبيثة (Malignant)، اعتمادًا على مجموعة من الخصائص الخلوية والمخبرية.
يعرض هذا المشروع مهاراتي في التعامل مع البيانات الحساسة، تطبيق الخوارزميات الحسابية بكفاءة، وتقديم حلول تقنية موثوقة في المجال الطبي الحيوي.
المنهجية والخطوات الفنية المتبعة
تحليل البيانات الاستكشافي (EDA): إجراء تحليل معمق للبيانات لفهم توزيع الخصائص، وتحديد أهميتها (Feature Importance)، وتصور العلاقة بين المتغيرات.
المعالجة المسبقة للبيانات (Pre-processing):
تنظيف البيانات والتعامل مع القيم المفقودة.
القياس (Standardization/Scaling): تطبيق معيارية للخصائص الرقمية، وهي خطوة حاسمة لضمان عمل خوارزمية kNN بفعالية.
تطوير النموذج وتدريبه:
تقسيم البيانات (تدريب واختبار).
بناء وتدريب نموذج kNN باستخدام مكتبة Scikit-learn في لغة Python.
تحسين الأداء (Hyperparameter Tuning): استخدام تقنيات البحث الشبكي (Grid Search) لتحديد القيمة المثلى لـ k (عدد الجيران) التي تحقق أعلى دقة وأقل خطأ للنموذج.
النتائج ومقاييس الأداء
تم تحقيق أداء ممتاز للنموذج بعد اختيار قيمة k المثالية، وتم تقييم النتائج باستخدام المقاييس التالية:
الدقة (Accuracy): [أدخل نسبة الدقة التي حققتها في الملف، مثال: 97.5%]
مصفوفة الالتباس (Confusion Matrix): لتقييم أداء النموذج في تحديد الحالات الإيجابية والسلبية الحقيقية (True Positives, True Negatives).
الاستدعاء (Recall) والدقة (Precision): مقاييس مهمة لضمان أن النموذج يتجنب الأخطاء في التشخيص (False Negatives تحديداً).
التقنيات والأدوات المستخدمة
لغة البرمجة: Python
مكتبات التعلم الآلي: Scikit-learn
مكتبات معالجة وتحليل البيانات: Pandas, NumPy
مكتبات التصور (Visualization): Matplotlib, Seaborn
بيئة العمل: Jupyter Notebook