Kindle Reviews Sentiment Analysis
تفاصيل العمل
في المشروع ده تم استخدام مجموعة بيانات كبيرة من تقييمات مستخدمي Amazon Kindle (مراجعات نصية مع تقييم النجوم) بهدف تصنيف المشاعر إلى إيجابية أو سلبية.
الخطوات شملت:
معالجة البيانات النصية (NLP preprocessing): تنظيف النصوص من الرموز، التوقف عن الكلمات (stopwords)، والتحويل إلى صيغة مناسبة للتحليل.
تمثيل النصوص: باستخدام تقنيات مثل Tokenization, Embedding لتهيئة البيانات للنماذج.
تجربة نماذج متعددة: بدايةً من خوارزميات التعلم التقليدي (Logistic Regression, SVM) إلى الشبكات العصبية (LSTM, GRU, CNN، ونسخ محسّنة مثل CuDNNGRU).
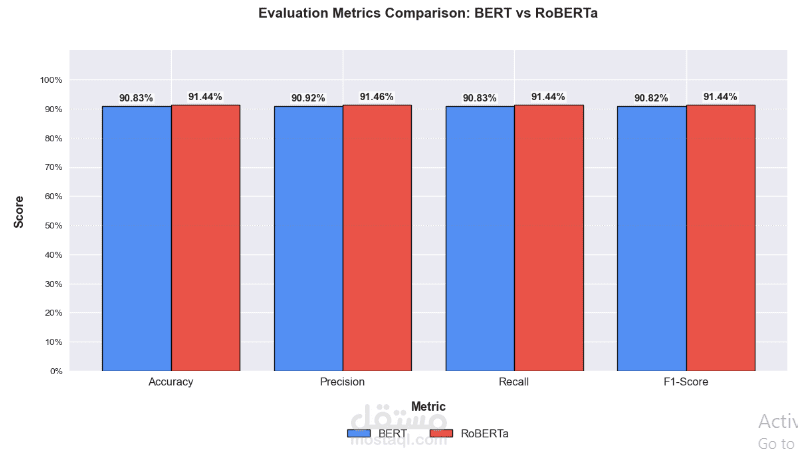
تجربة نماذج حديثة: مثل BERT وRoBERTa لتحسين الدقة.
التقييم: مقارنة أداء النماذج باستخدام مقاييس مثل الدقة (Accuracy)، منحنى ROC، وفقدان التدريب/التحقق.
المشروع أبرز إزاي ممكن استخدام تقنيات معالجة اللغة الطبيعية (NLP) لتصنيف المشاعر بشكل فعال وتحويل تقييمات العملاء إلى رؤى قابلة للاستخدام تساعد في فهم انطباعات المستخدمين عن المنتج.