Stroke Prediction using ML
تفاصيل العمل
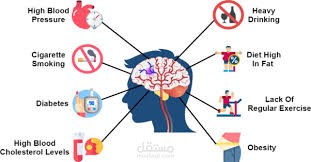
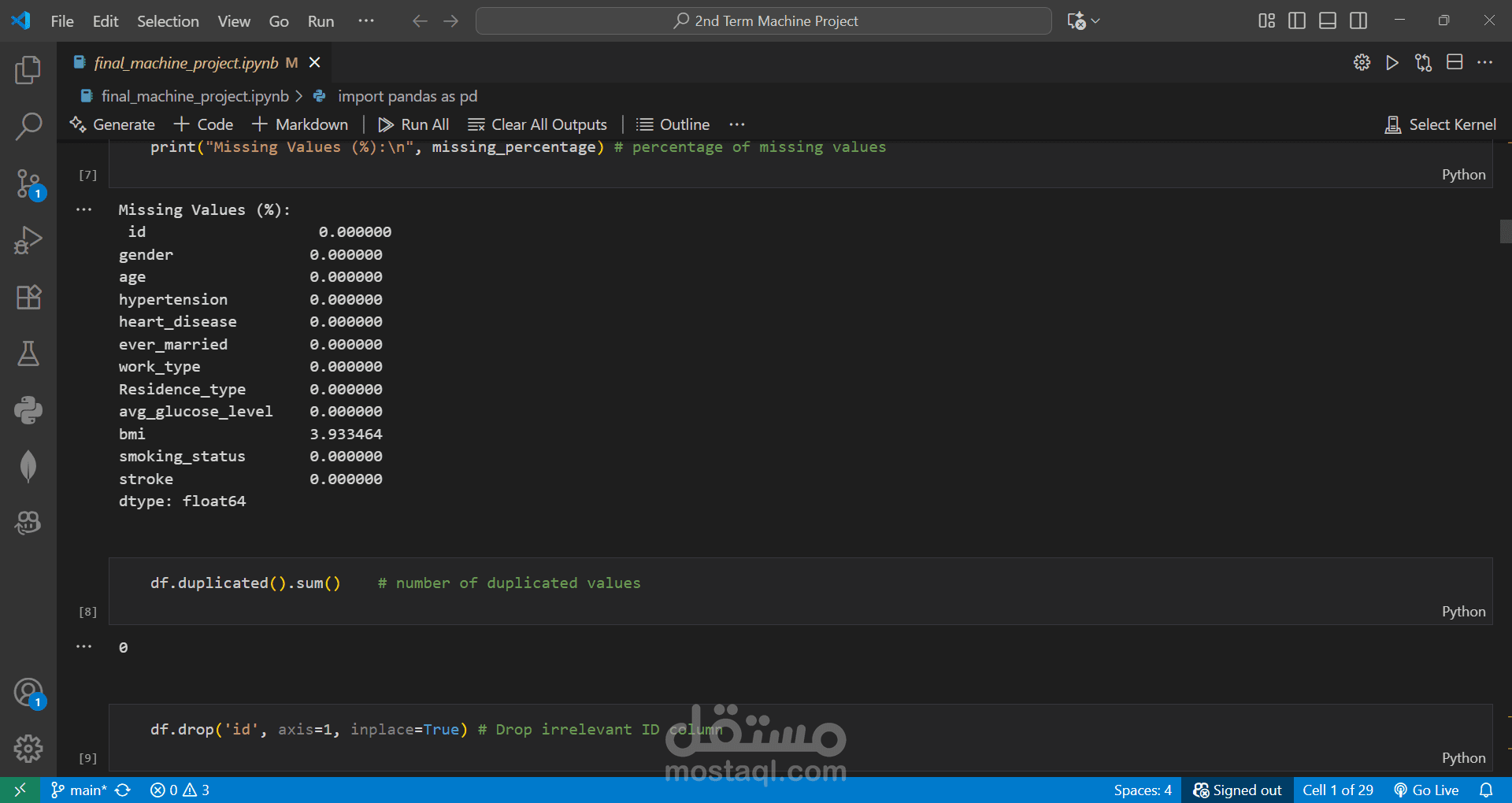
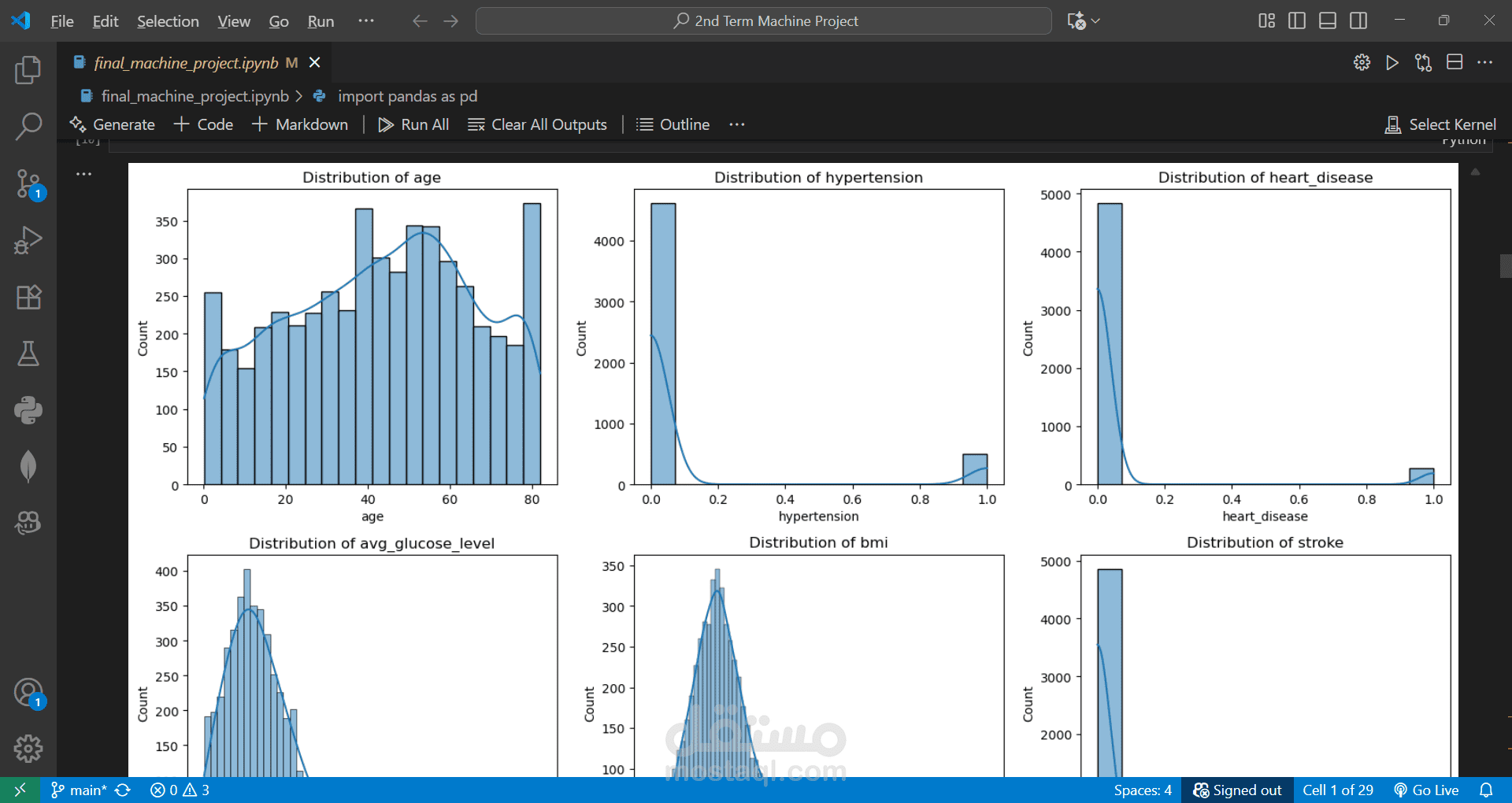
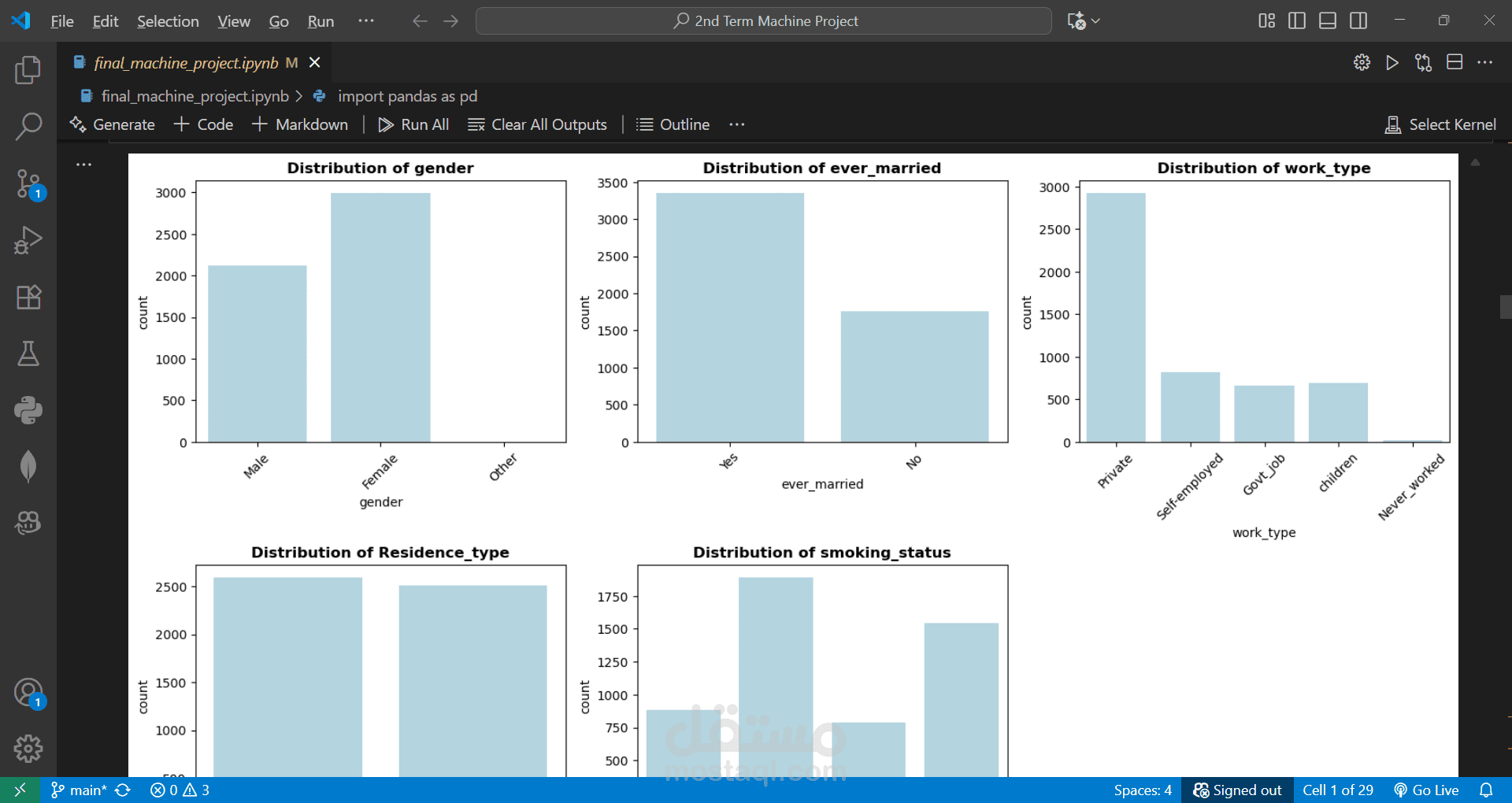
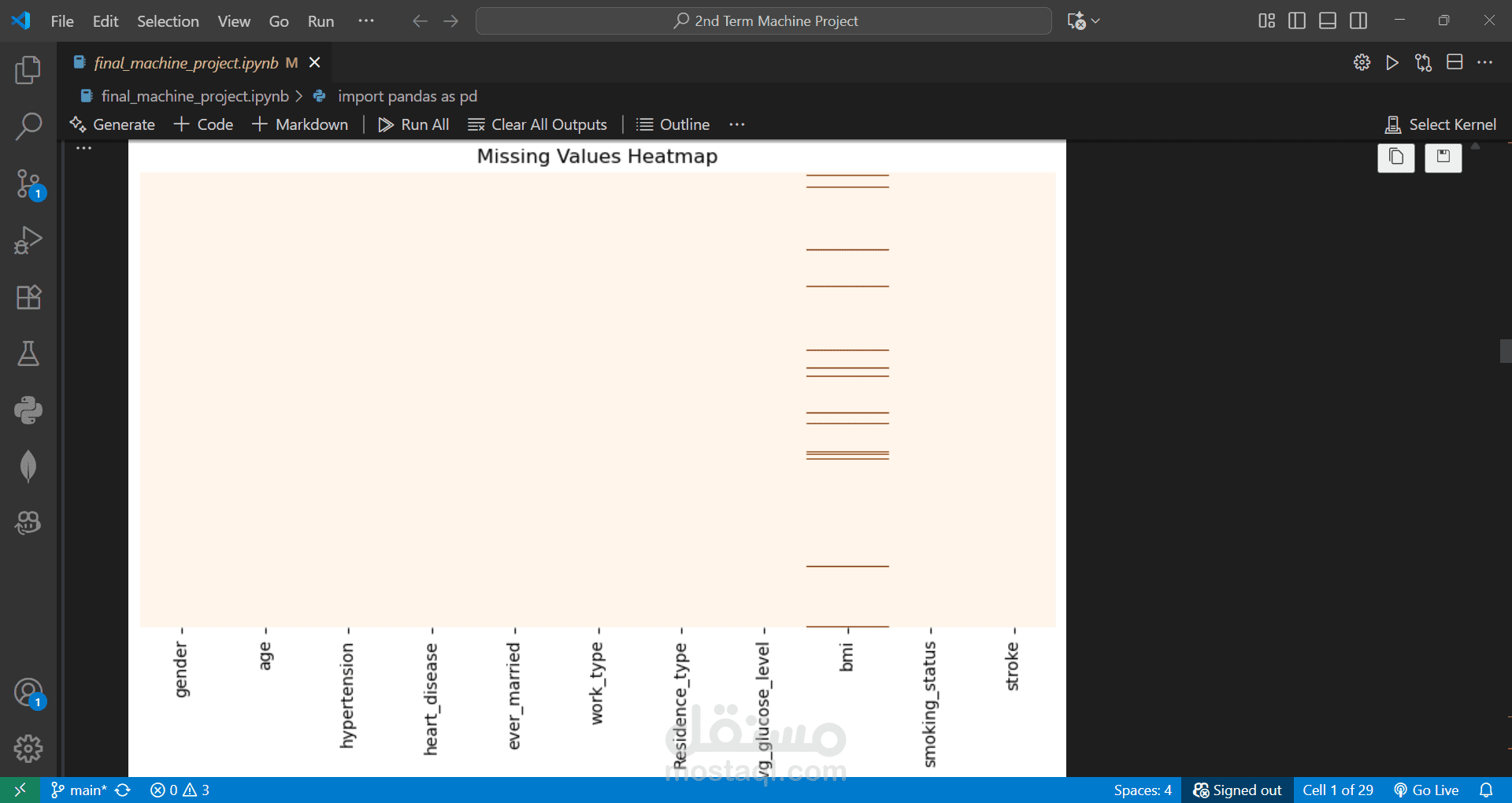
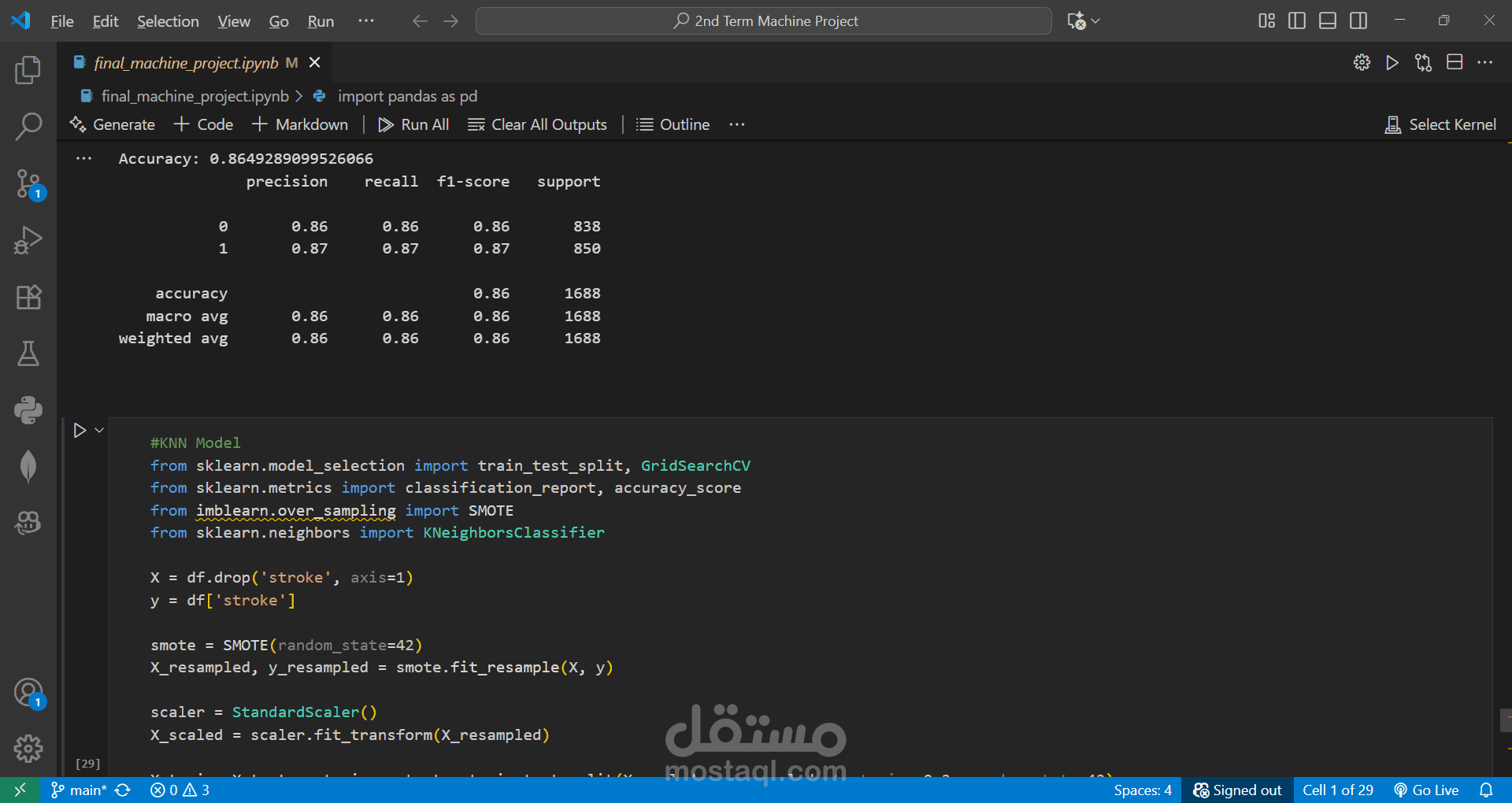
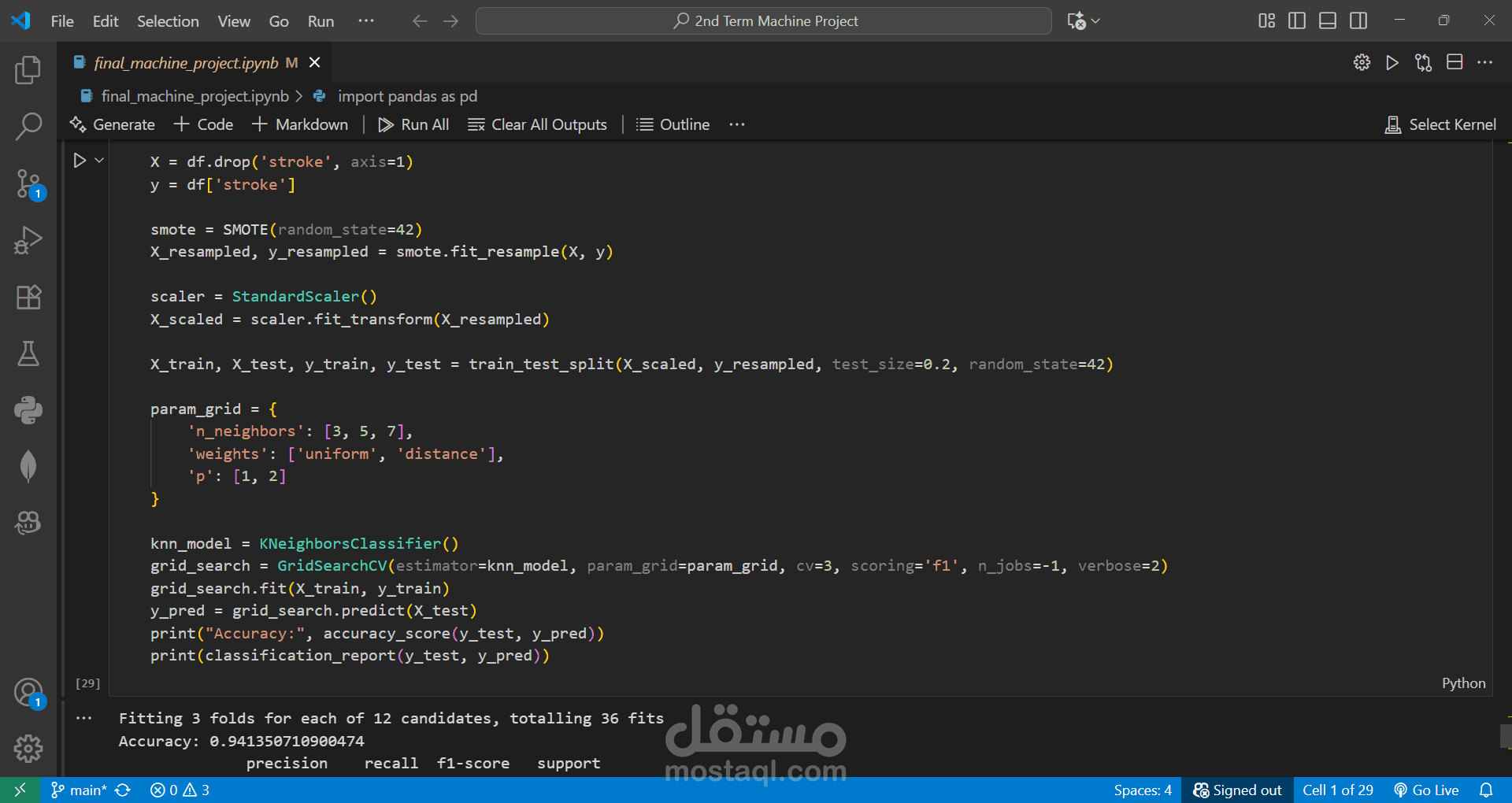
Predicted the likelihood of a person having a stroke based on health and demographic factors.
Approach:
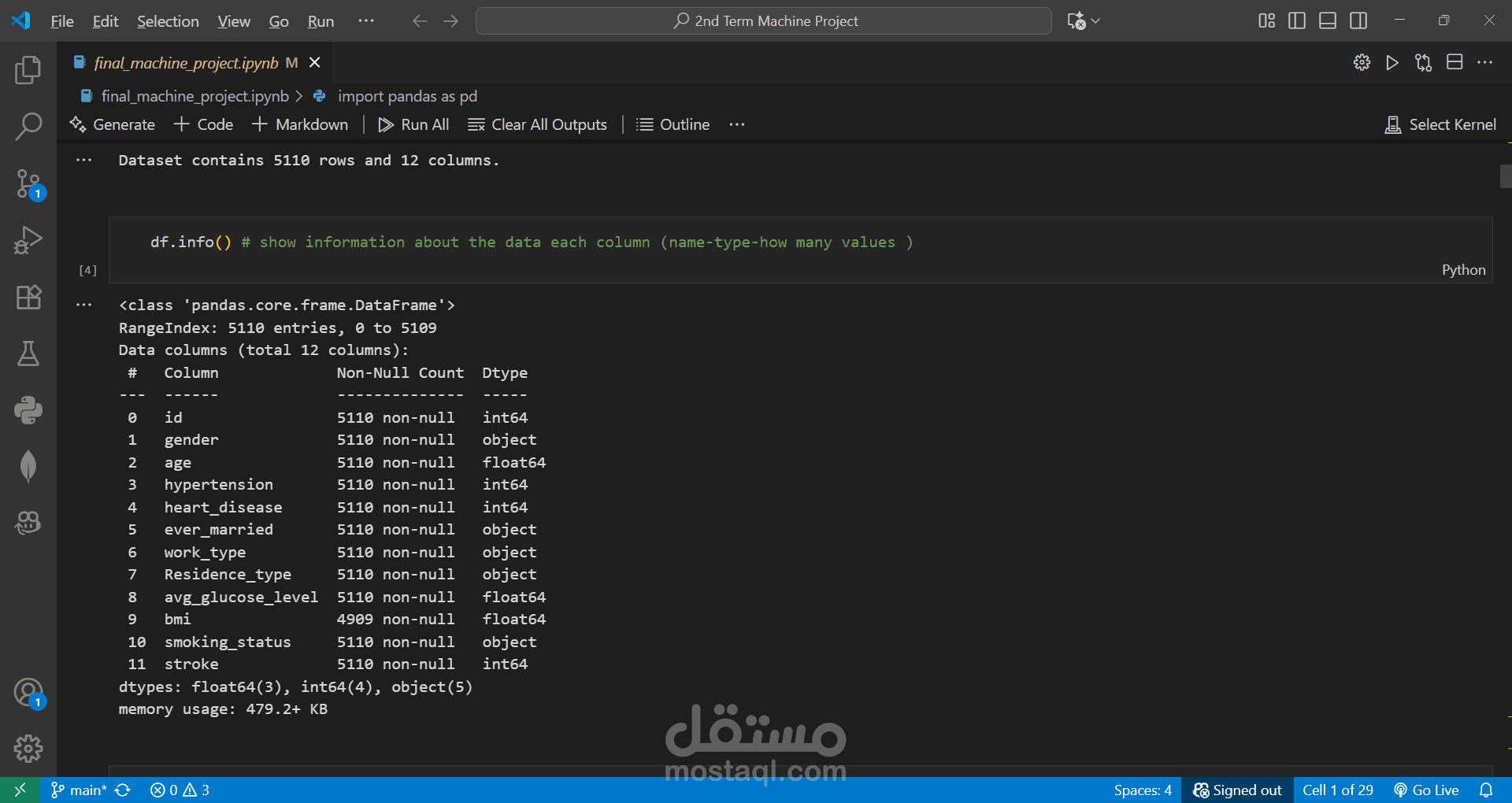
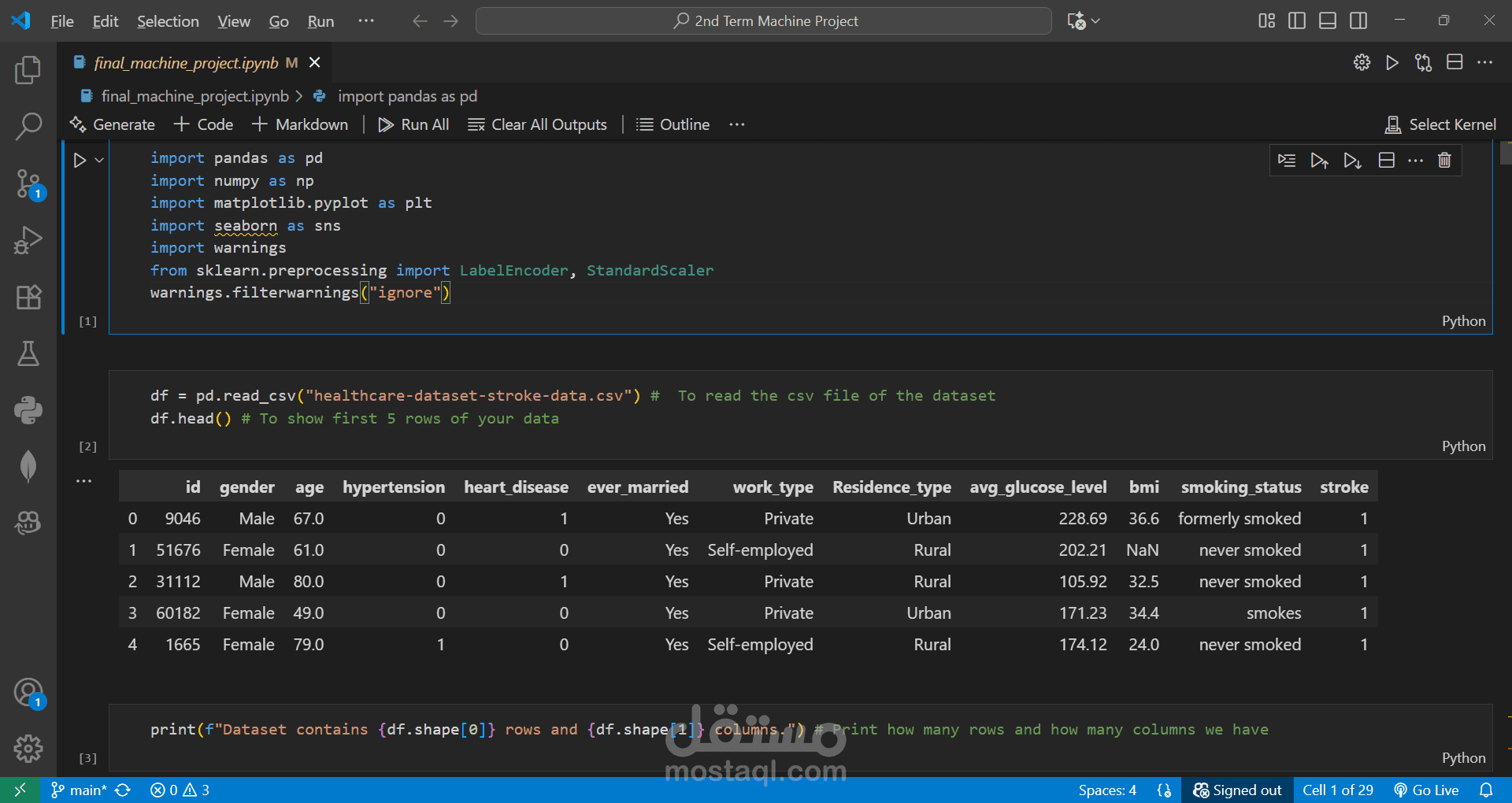
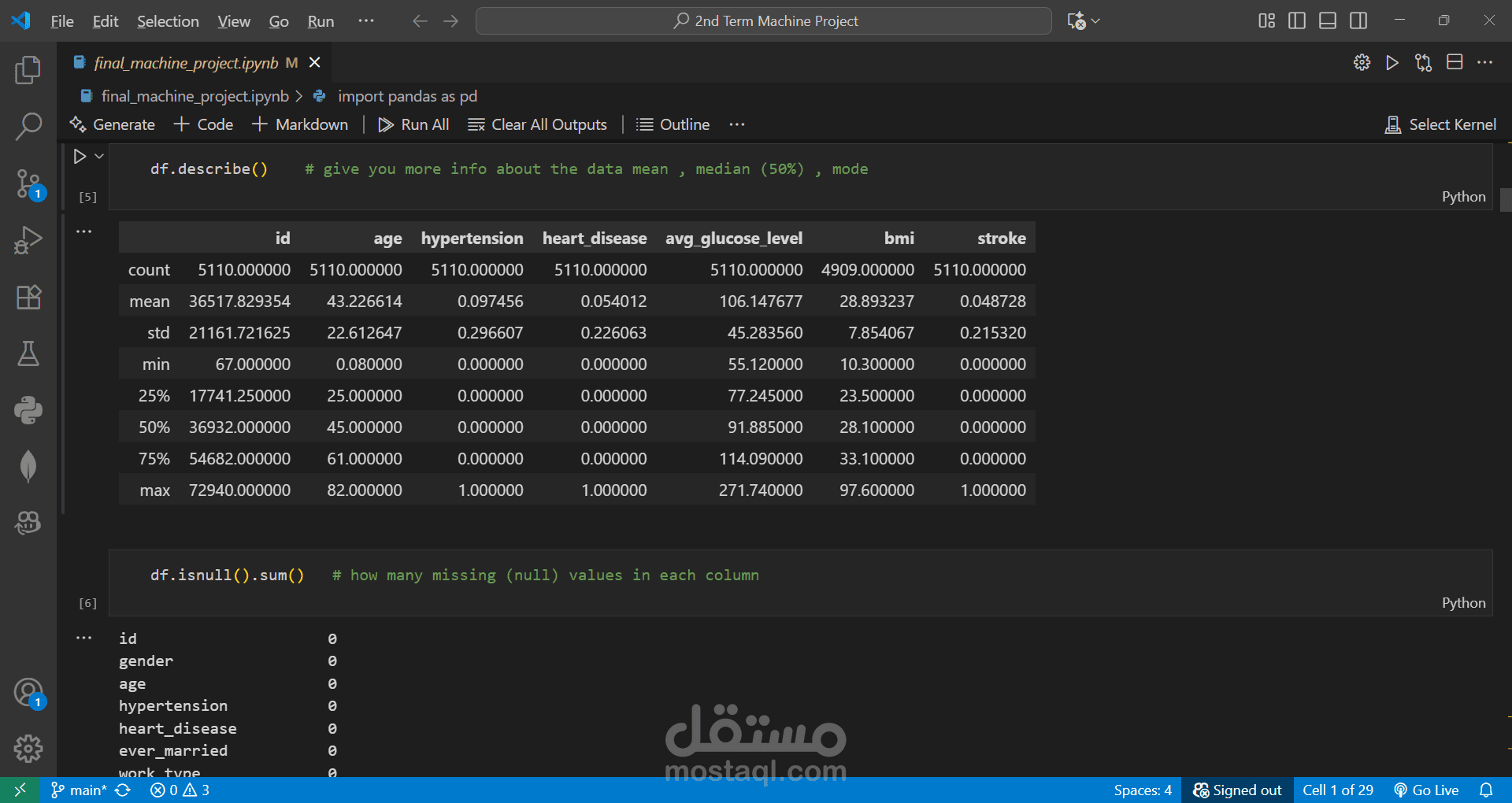
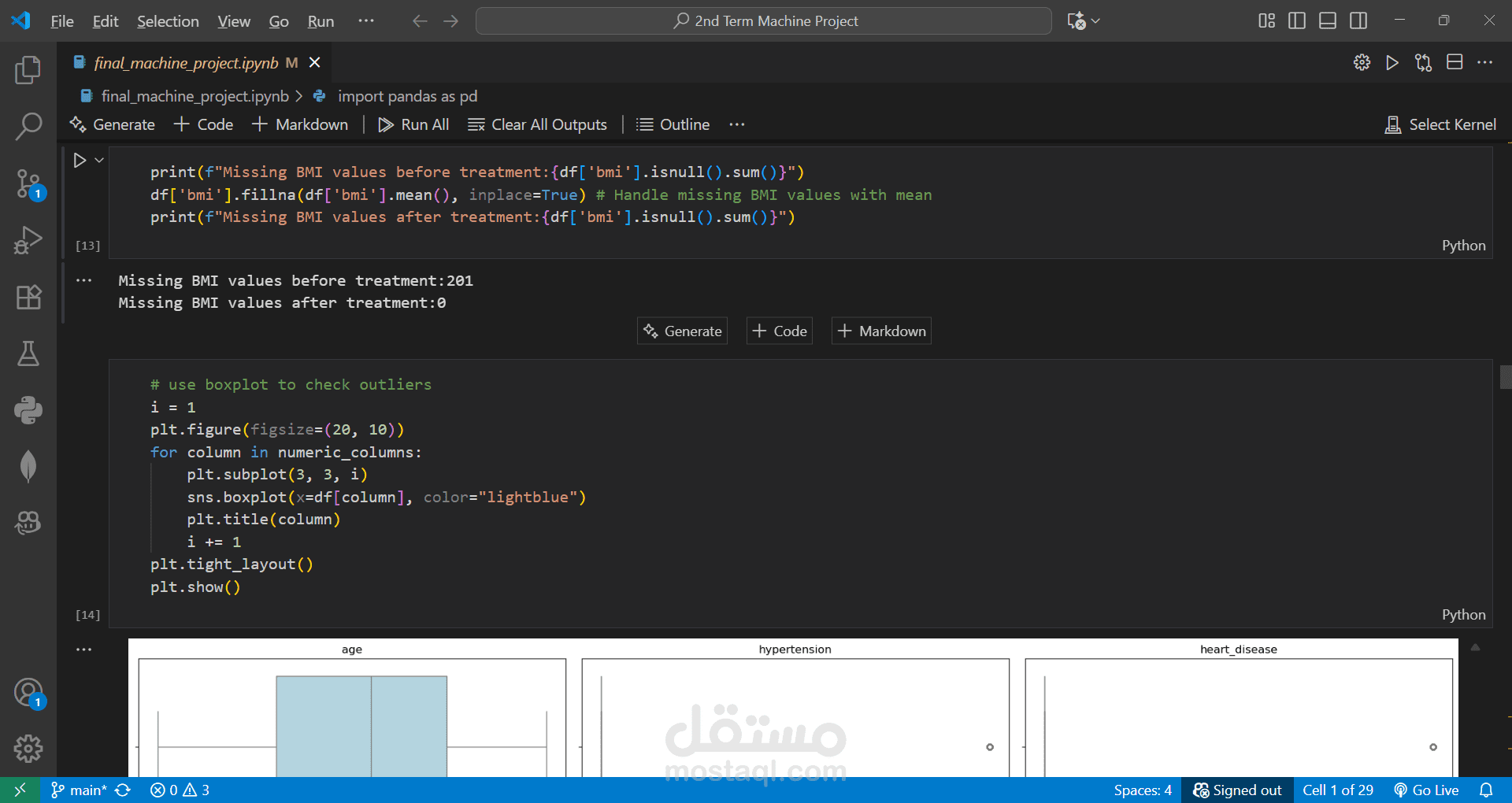
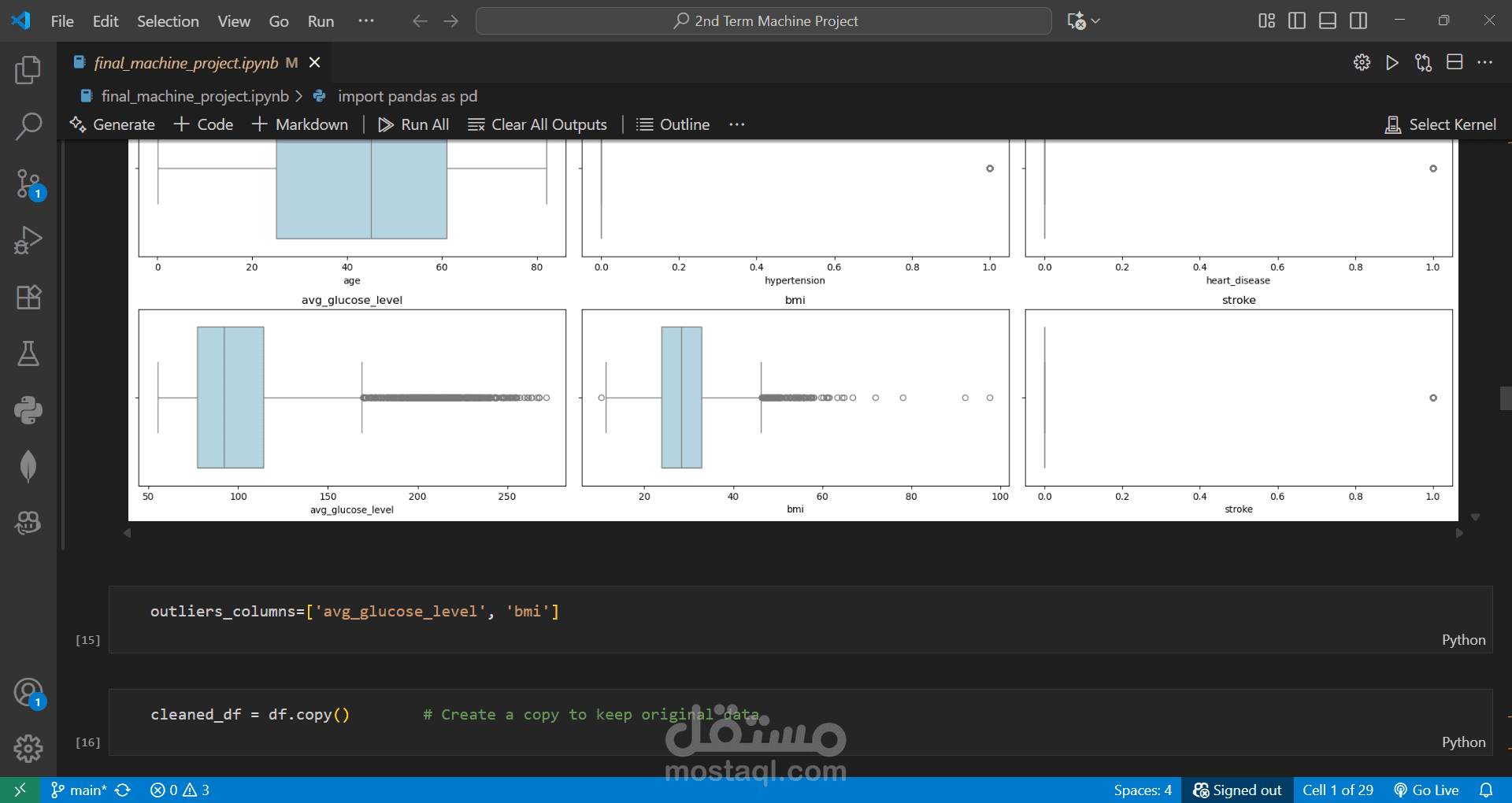
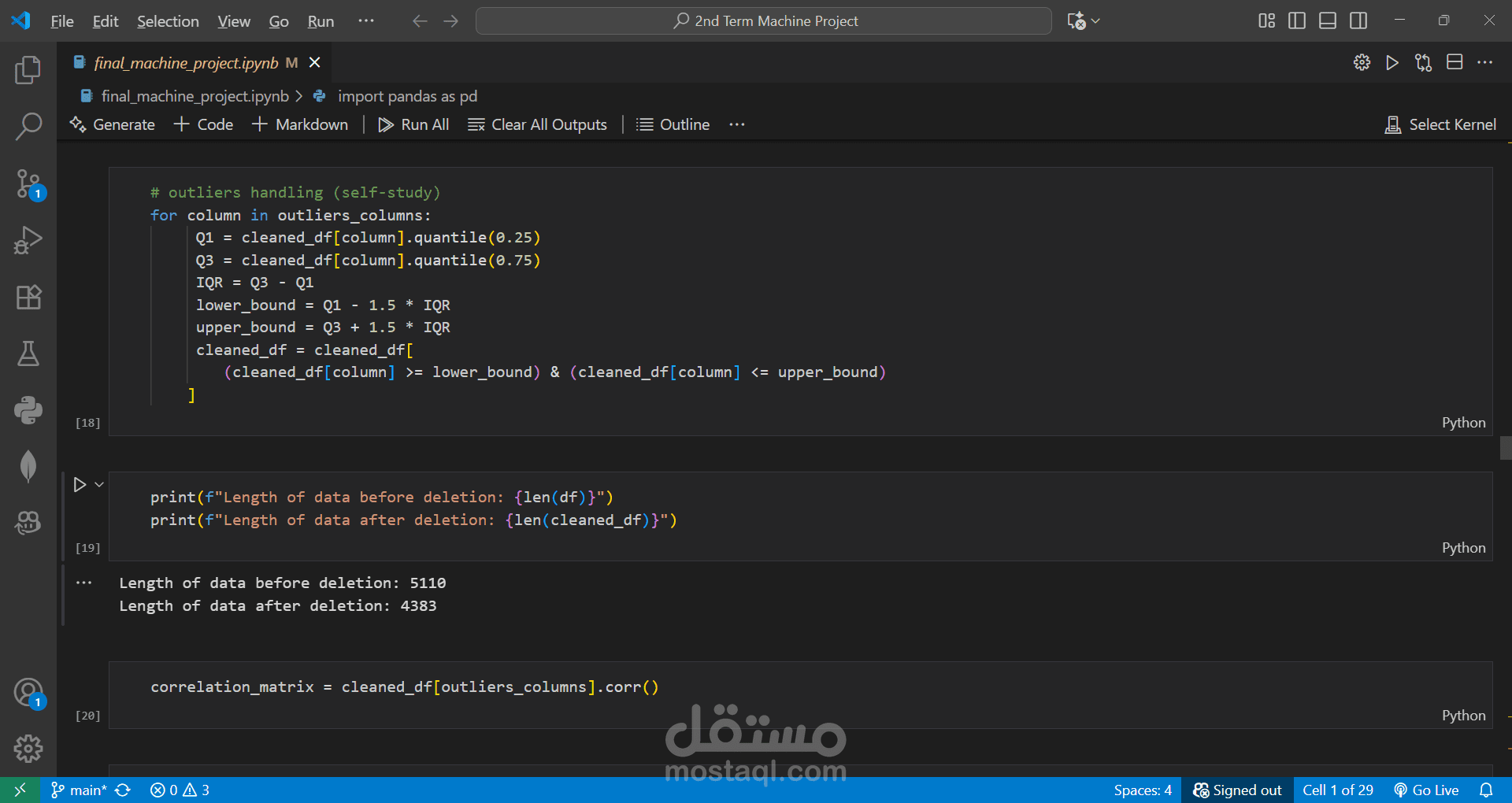
Cleaned and preprocessed the dataset by handling missing values and removing outliers.
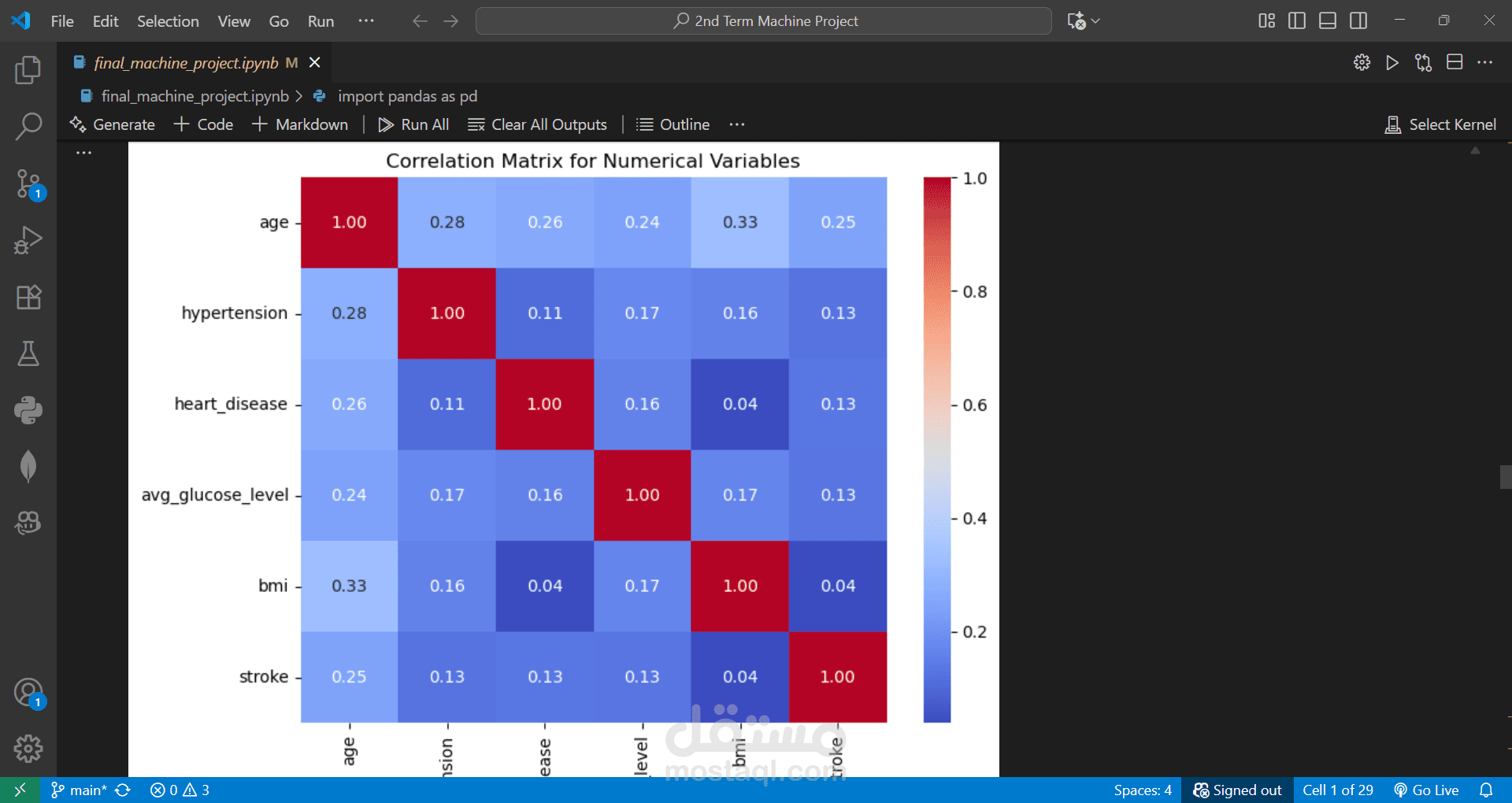
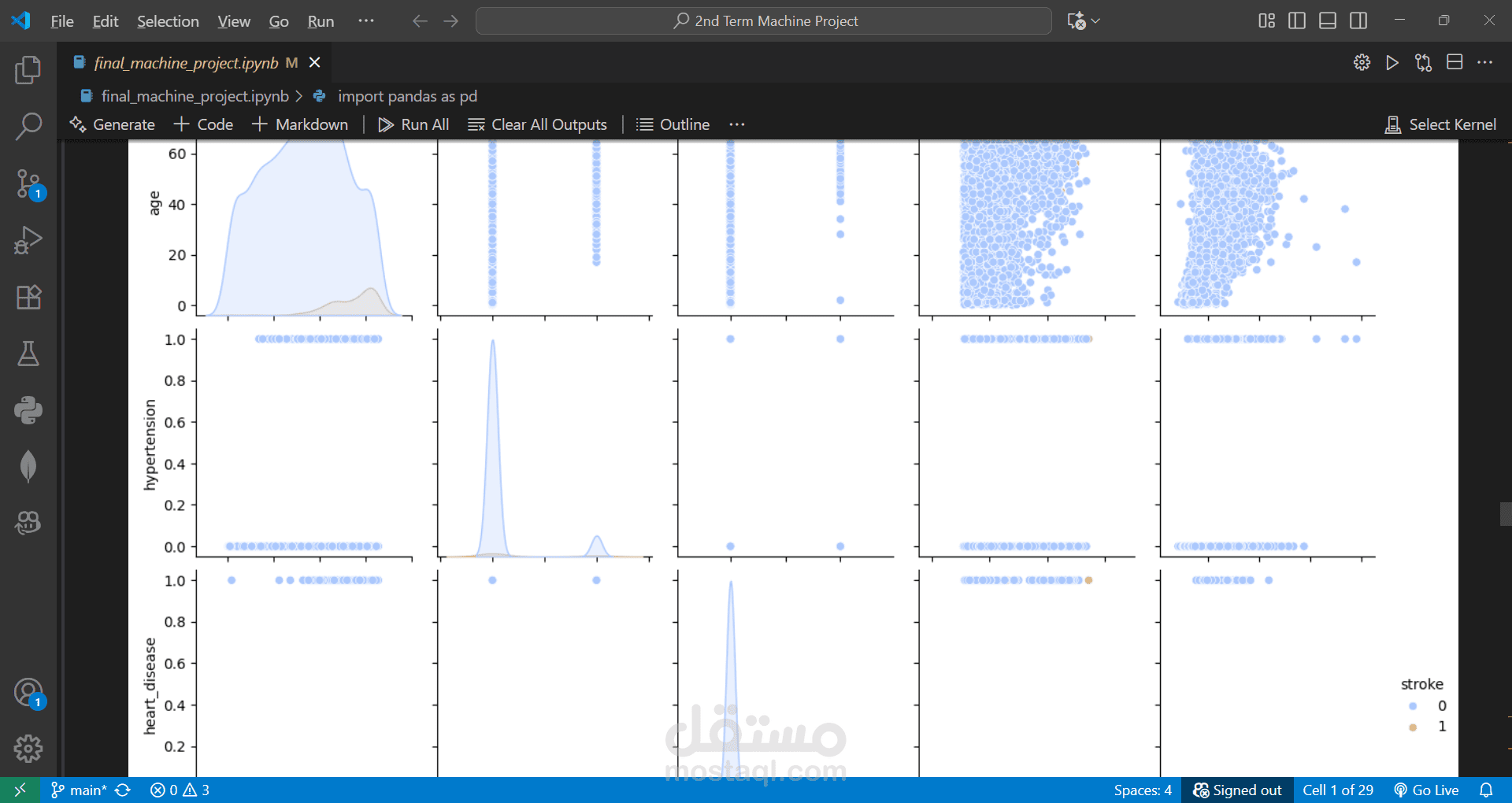
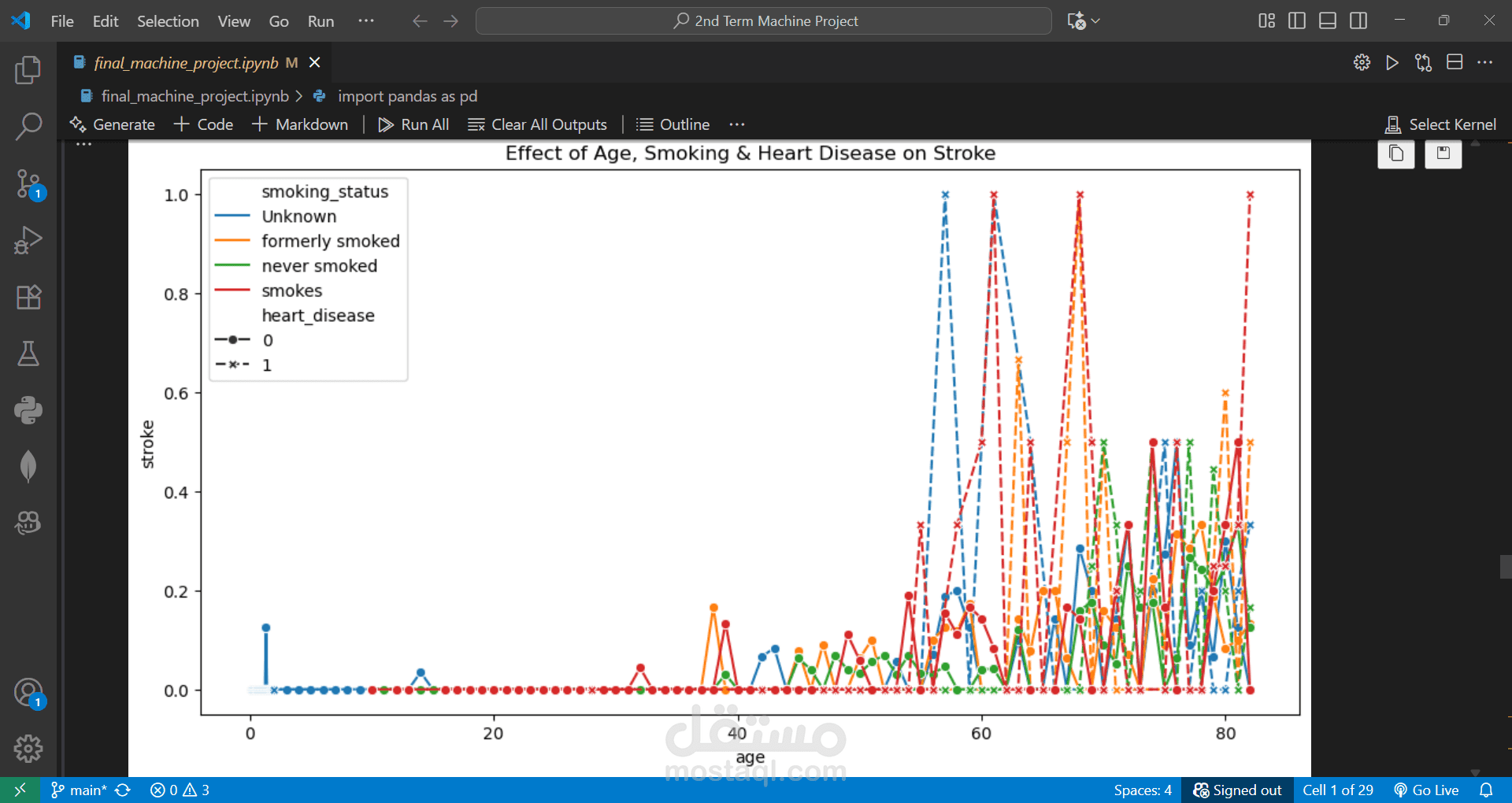
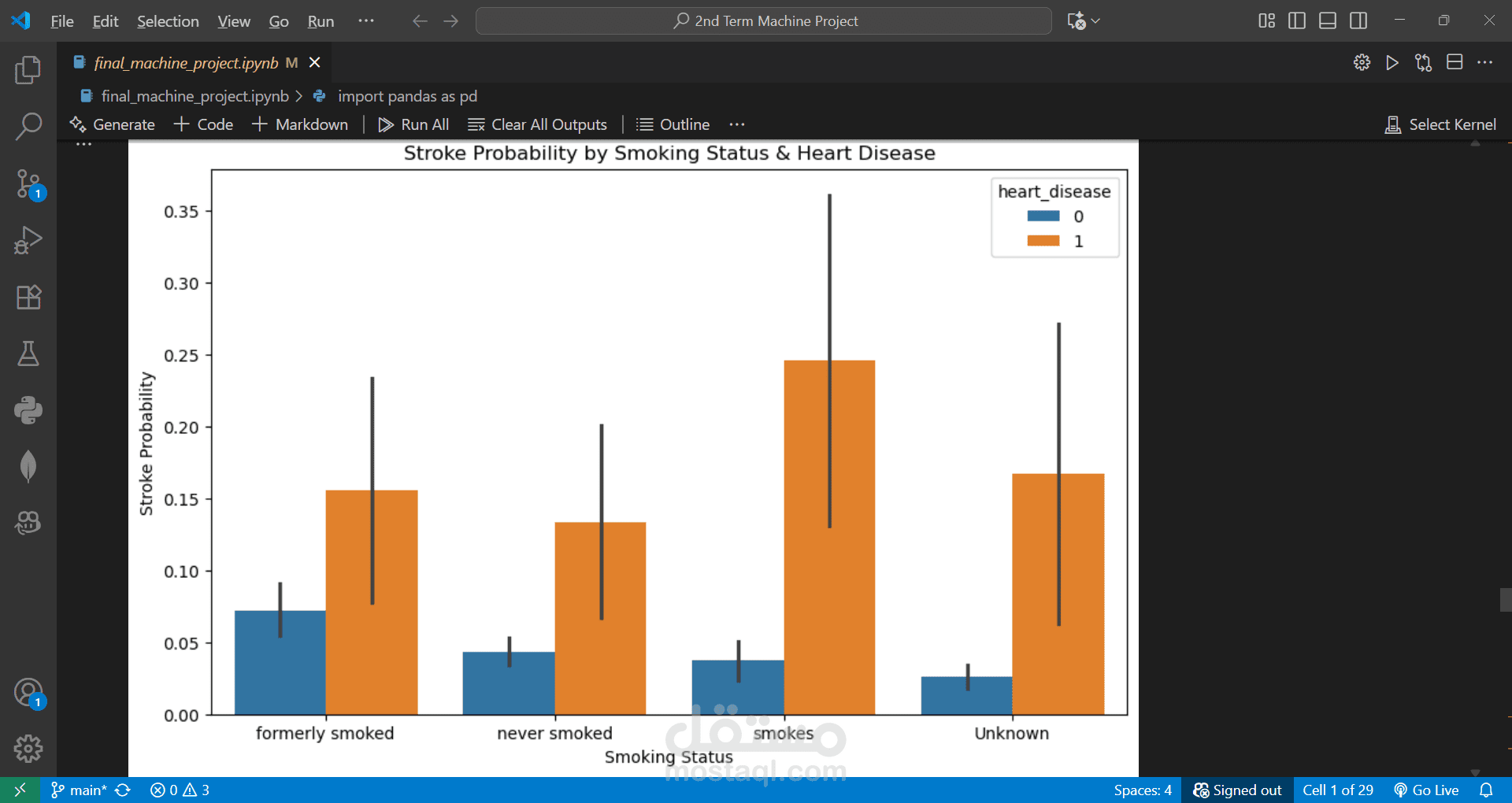
Performed EDA and created visualizations to understand patterns and correlations.
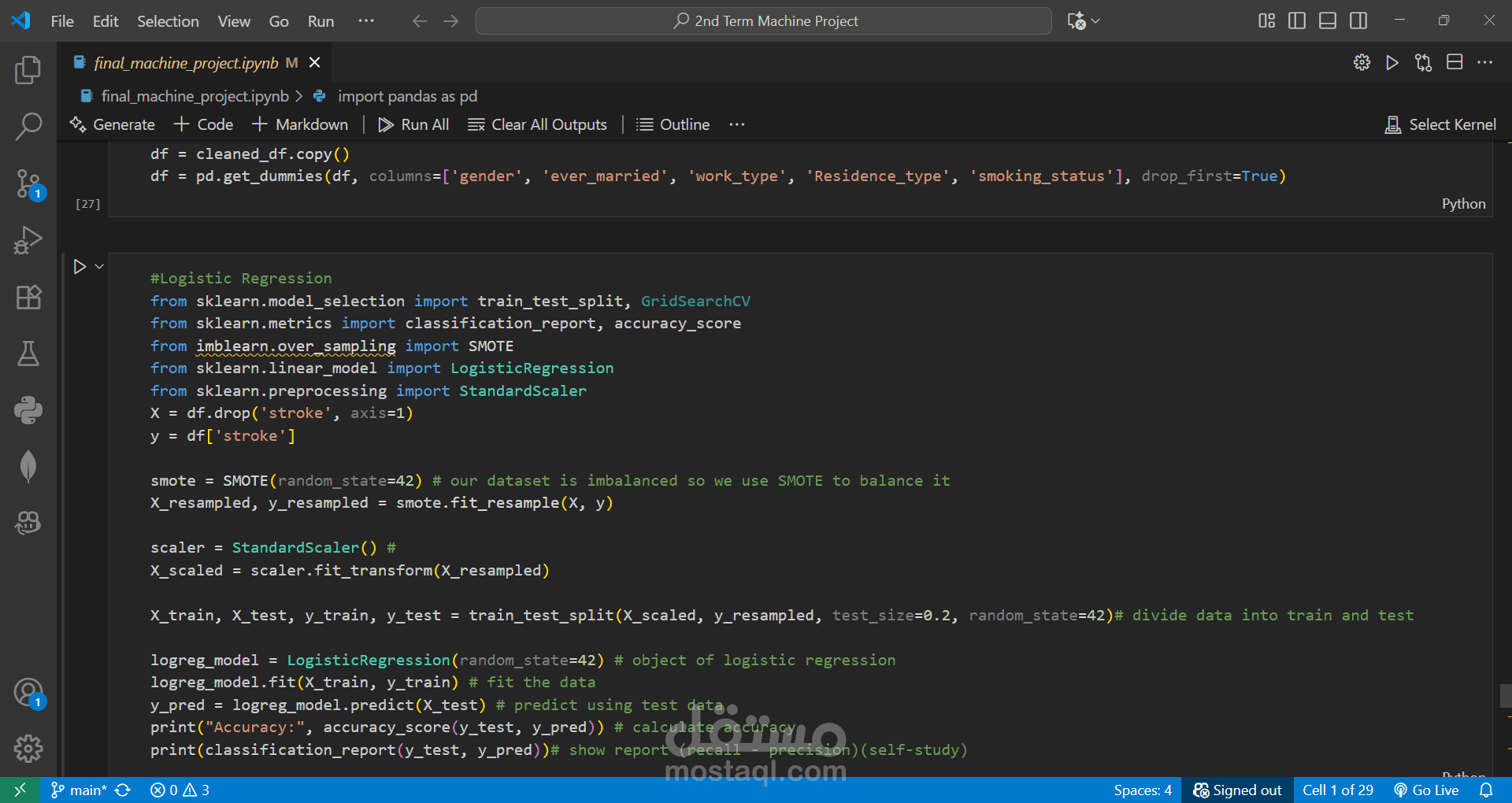
Applied Logistic Regression and KNN algorithms for binary classification.
Evaluated models using an accuracy matrix and other performance metrics.
Libraries: Pandas, NumPy, Scikit-learn, Matplotlib, Seaborn.
Outcome: Successfully built a machine learning pipeline for stroke prediction, with comparative performance insights.