Fake Job web Scrabing
تفاصيل العمل


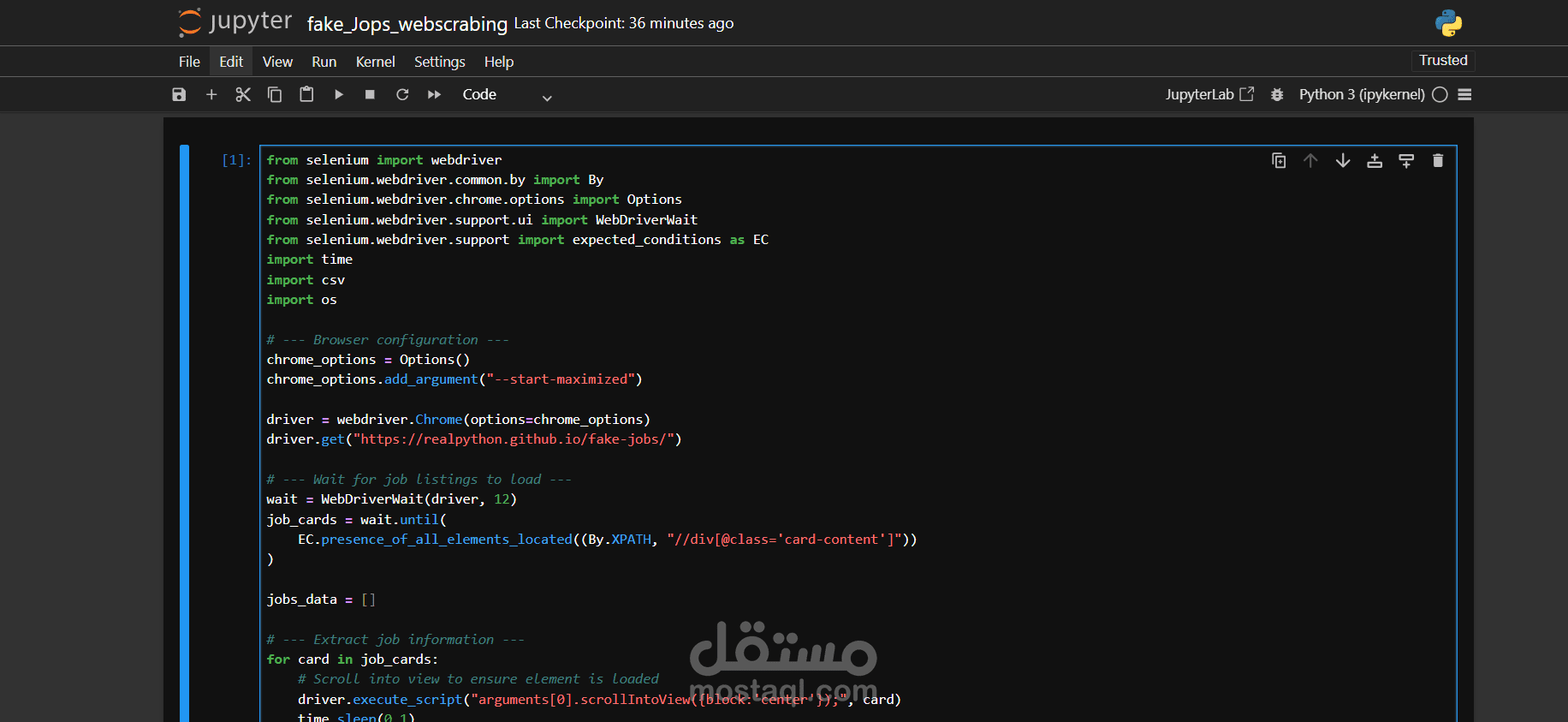
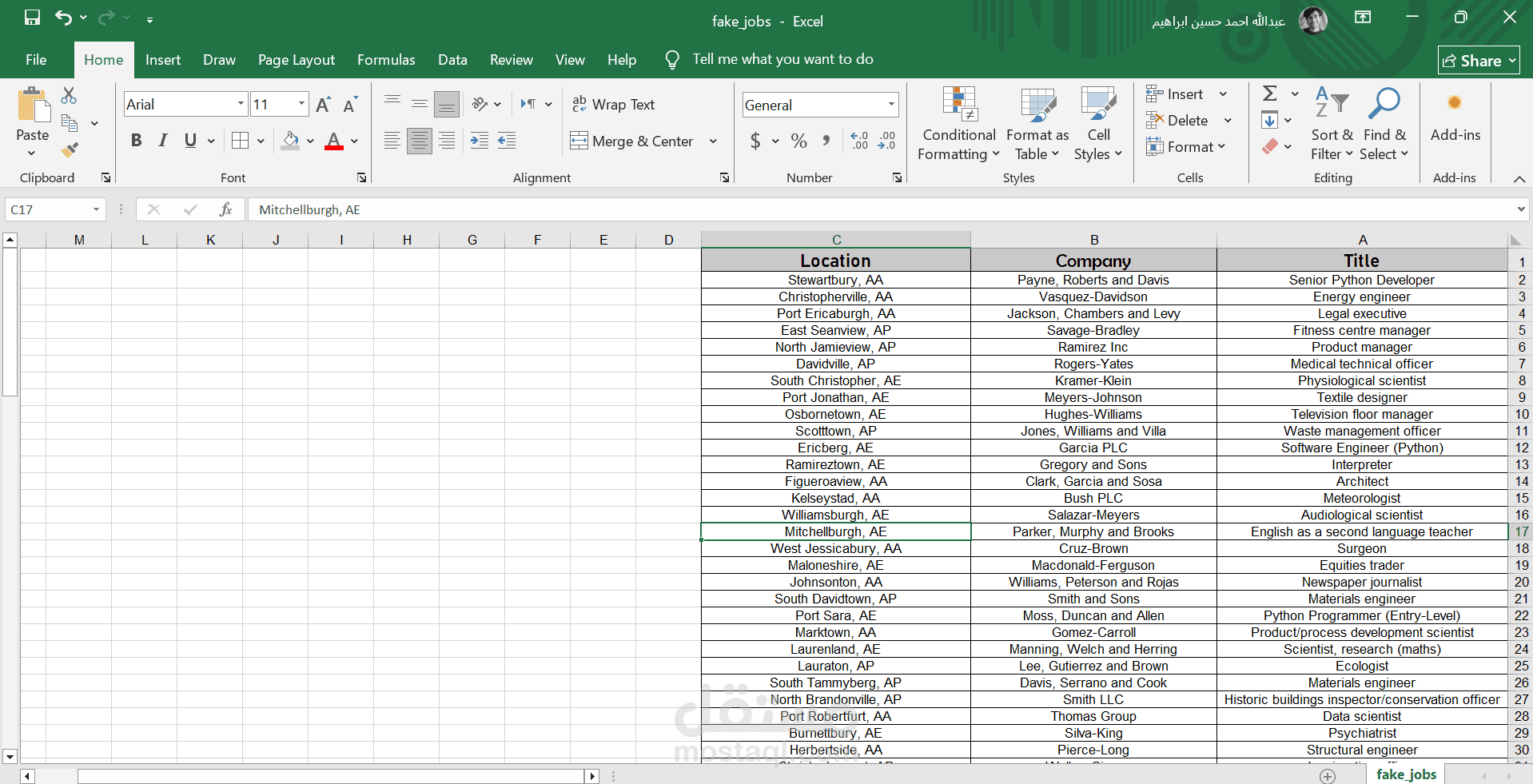
The Fake Jobs Web Scraping Project was designed to collect and analyze job postings data for the purpose of identifying and classifying fake job advertisements. Using Python with BeautifulSoup/Selenium, the project extracted job-related information from job boards and online listings, cleaned the data, and prepared it for further analysis and machine learning tasks.
Key Tasks:
Scraping job postings from online job portals.
Extracting details such as:
Job Title
Company Name
Location
Job Description
Requirements
Cleaning and preprocessing the scraped data.
Structuring the dataset for Fake Job Detection Models.
Exporting the dataset into CSV/Excel format.
Features:
Automated data extraction from multiple job listings.
Scalable scraping solution adaptable to different job portals.
Dataset prepared for Natural Language Processing (NLP) and classification tasks.
Helps in detecting fraudulent job advertisements.
Use Cases:
Building and training Machine Learning models to detect fake jobs.
Enhancing job platforms’ ability to flag suspicious postings.
Supporting researchers in studying patterns of fraudulent job offers.
Providing clean, structured datasets for academic and practical projects.