Amazon Web scrabing
تفاصيل العمل


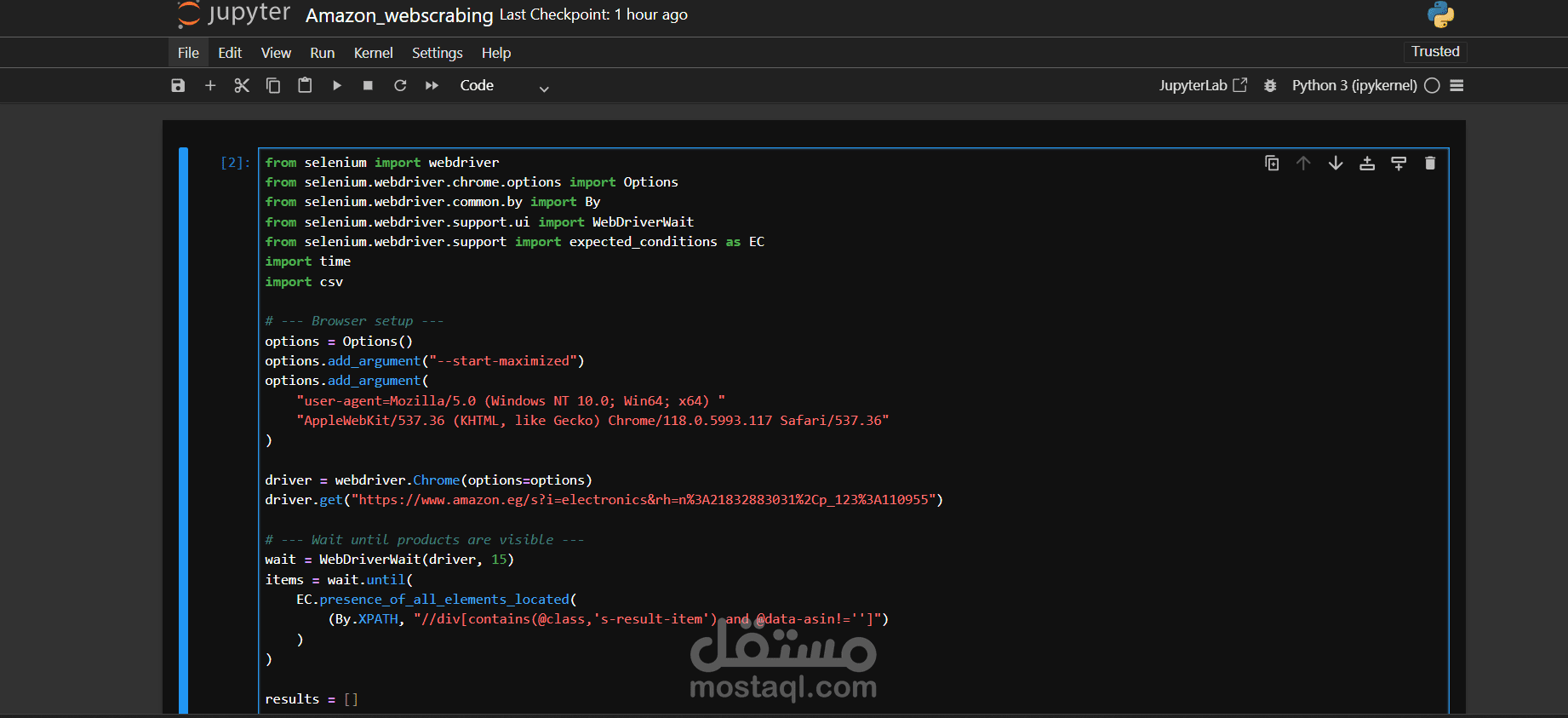
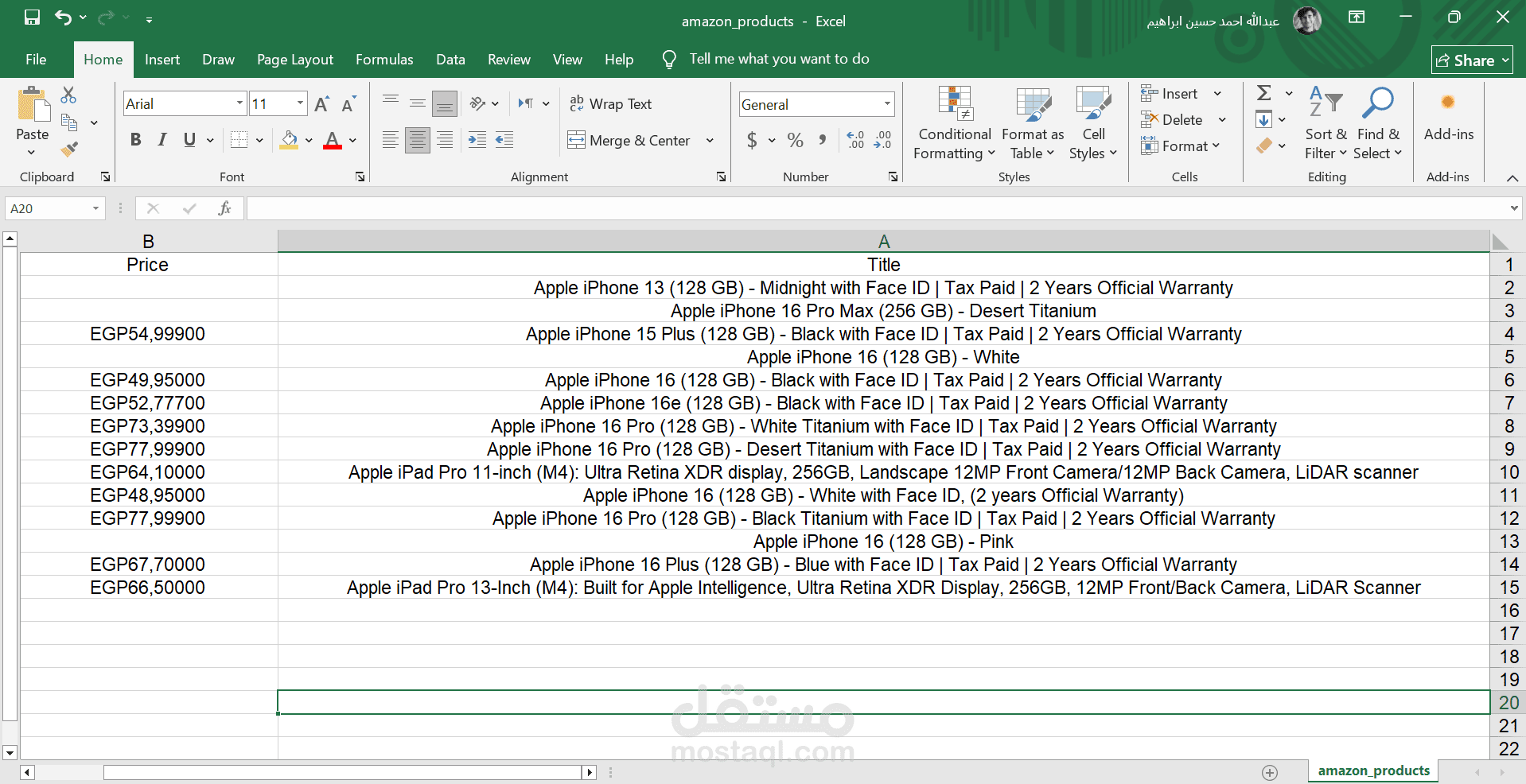
The Amazon Web Scraping Project was developed to automatically extract product data from Amazon for analysis and comparison. The project was built using Python with Selenium to handle Amazon’s dynamic pages, allowing smooth navigation, data collection, and storage in a structured format.
Key Tasks:
Automated navigation to Amazon’s website using Selenium.
Searching for products based on specific keywords.
Extracting essential product details such as:
Product Title
Price
Rating
Number of Reviews
Product URL
Handling pagination to scrape data across multiple result pages.
Exporting the collected data into CSV/Excel files for further analysis.
Features:
Efficient scraping of hundreds of products from Amazon.
Flexible code that can be customized for different categories (Electronics, Books, Fashion, etc.).
Ability to schedule scraping tasks for daily or weekly updates.
Clean and well-structured data export for research or business use.
Use Cases:
Price monitoring and comparison for e-commerce.
Customer feedback analysis through reviews and ratings.
Building a market research database.
Supporting businesses and researchers with up-to-date product insights.