Cinema Dataset ETL Project
تفاصيل العمل
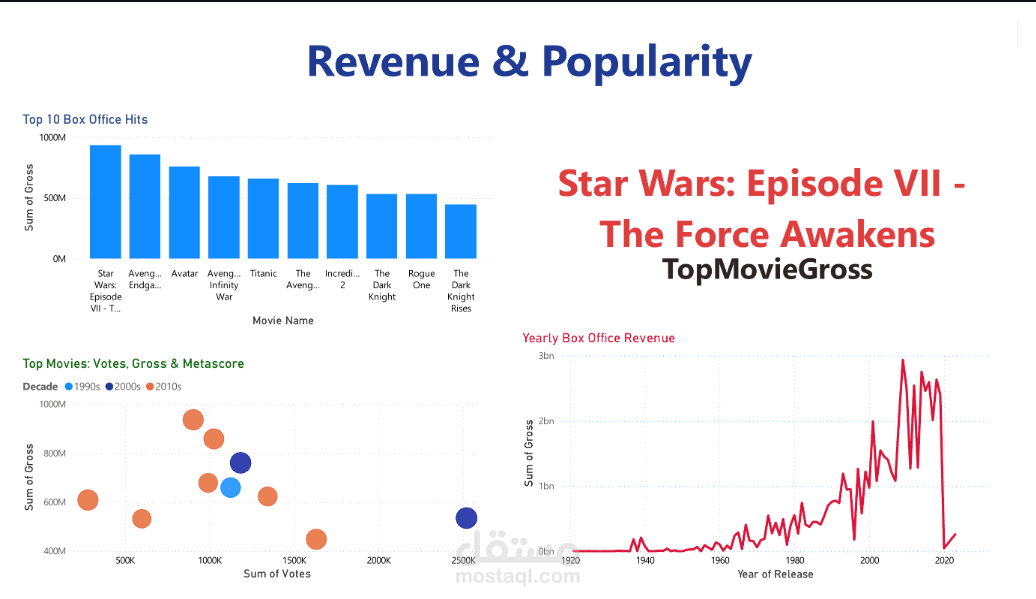
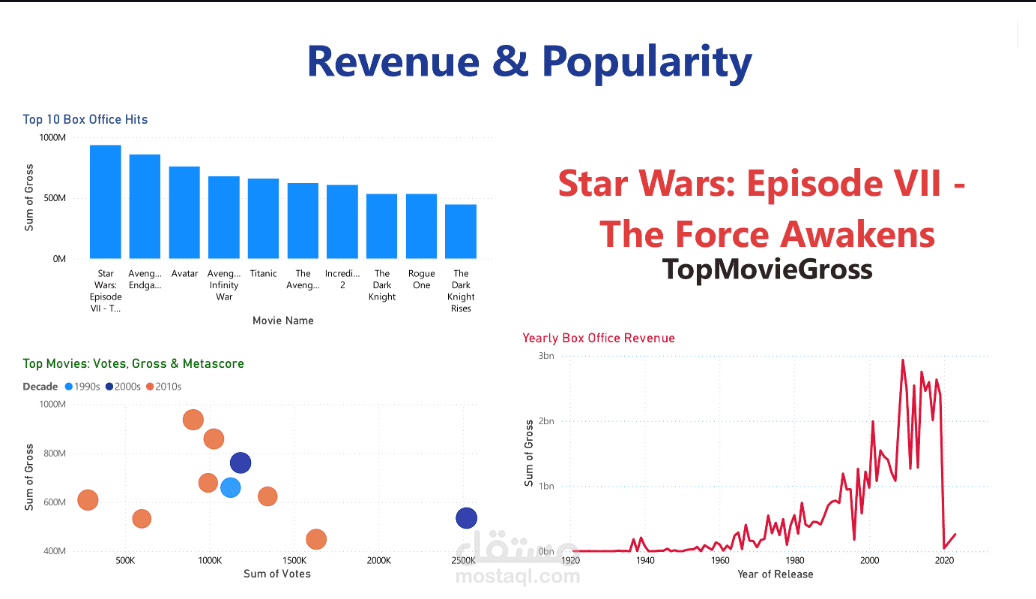
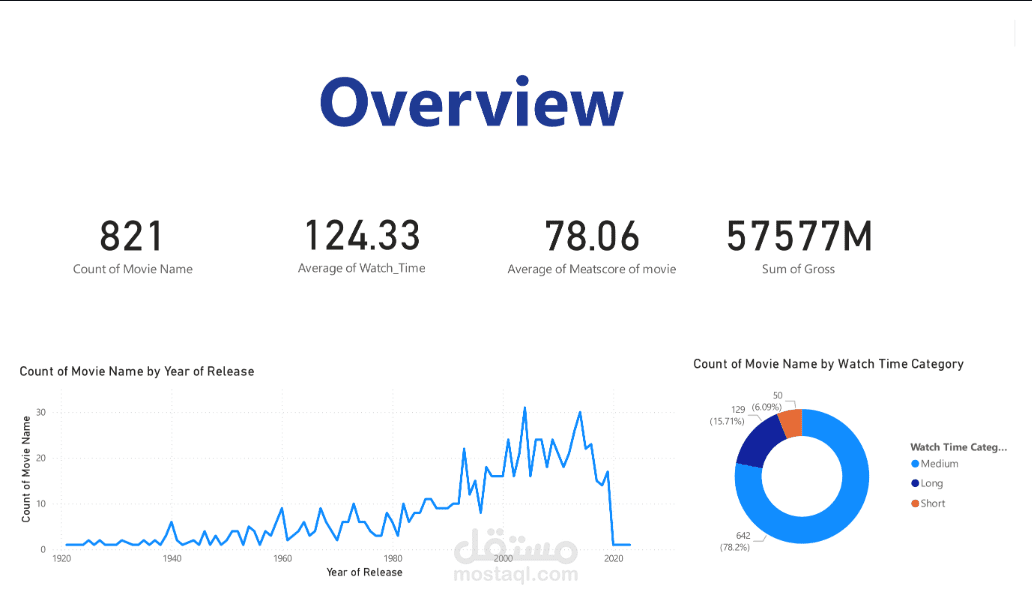
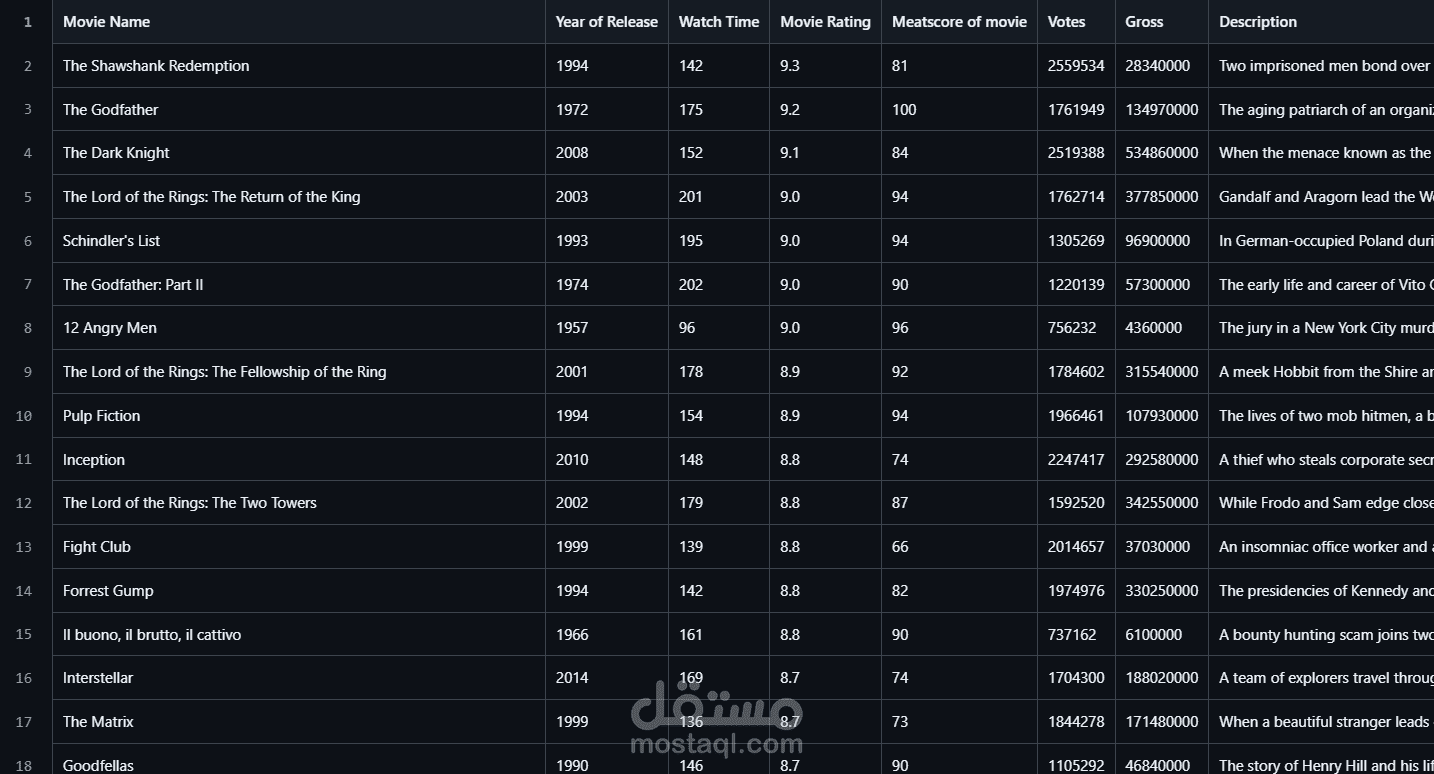
مشروع Cinema Dataset ETL
المشروع كان الهدف منه بناء ETL Pipeline باستخدام ملف بيانات عن الأفلام (مصدره من Kaggle).
الاستخراج (Extraction)
تم الحصول على البيانات في صورة ملف (CSV) يحتوي على معلومات عن الأفلام: الاسم، سنة الإصدار، مدة العرض، التقييمات، عدد الأصوات، والإيرادات.
التحويل (Transformation)
تنظيف وتجهيز البيانات للتحليل:
توحيد أسماء الأفلام وإضافة سنة الإصدار للأسماء المكررة لجعلها فريدة.
استخراج وتوحيد سنة الإصدار كقيمة رقمية.
تحويل مدة العرض من صيغة "min" إلى أعداد صحيحة.
ملء القيم المفقودة في التقييمات بالقيمة الوسيطية (Median).
تحويل عدد الأصوات إلى أعداد صحيحة بعد إزالة العلامات مثل الفواصل.
تنظيف الإيرادات من الرموز ($, M) وتحويلها إلى قيم رقمية صحيحة.
التحميل (Loading)
تم تحميل البيانات النظيفة في قاعدة بيانات SQL Server داخل جدول Movies لتمكين الاستعلام والتحليل.
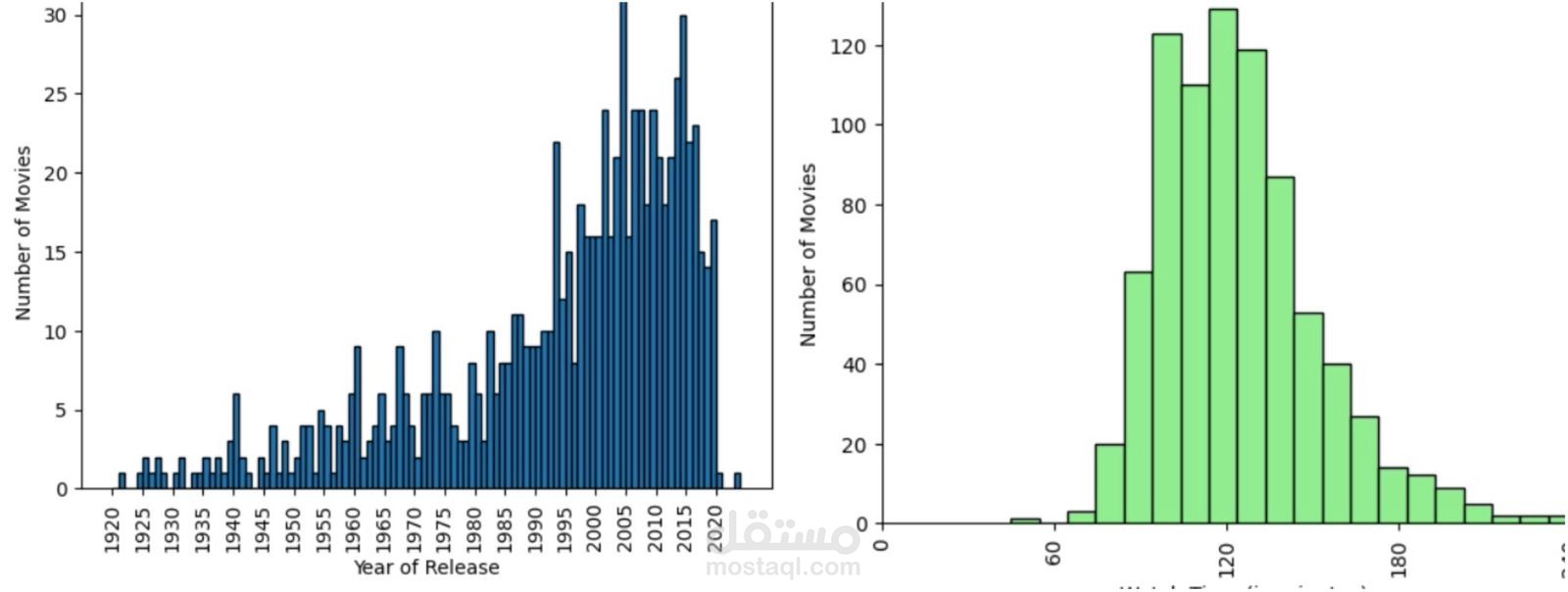
التصور والتحليل (Visualization & EDA)
باستخدام Seaborn و Matplotlib تم عمل تحليلات استكشافية شملت:
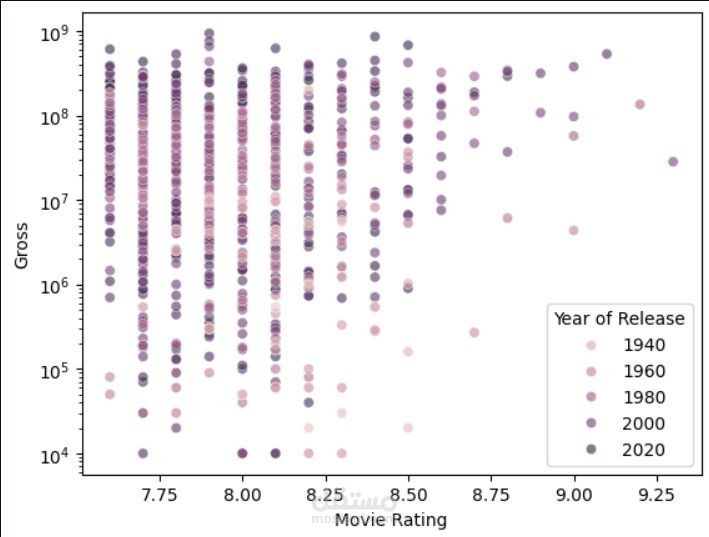
Histograms: لفحص توزيع مدة العرض، الأصوات، والإيرادات.
Countplots: لعرض عدد الأفلام المنتجة كل سنة.
Line Charts: لإظهار اتجاه الإيرادات والتقييمات عبر السنوات.
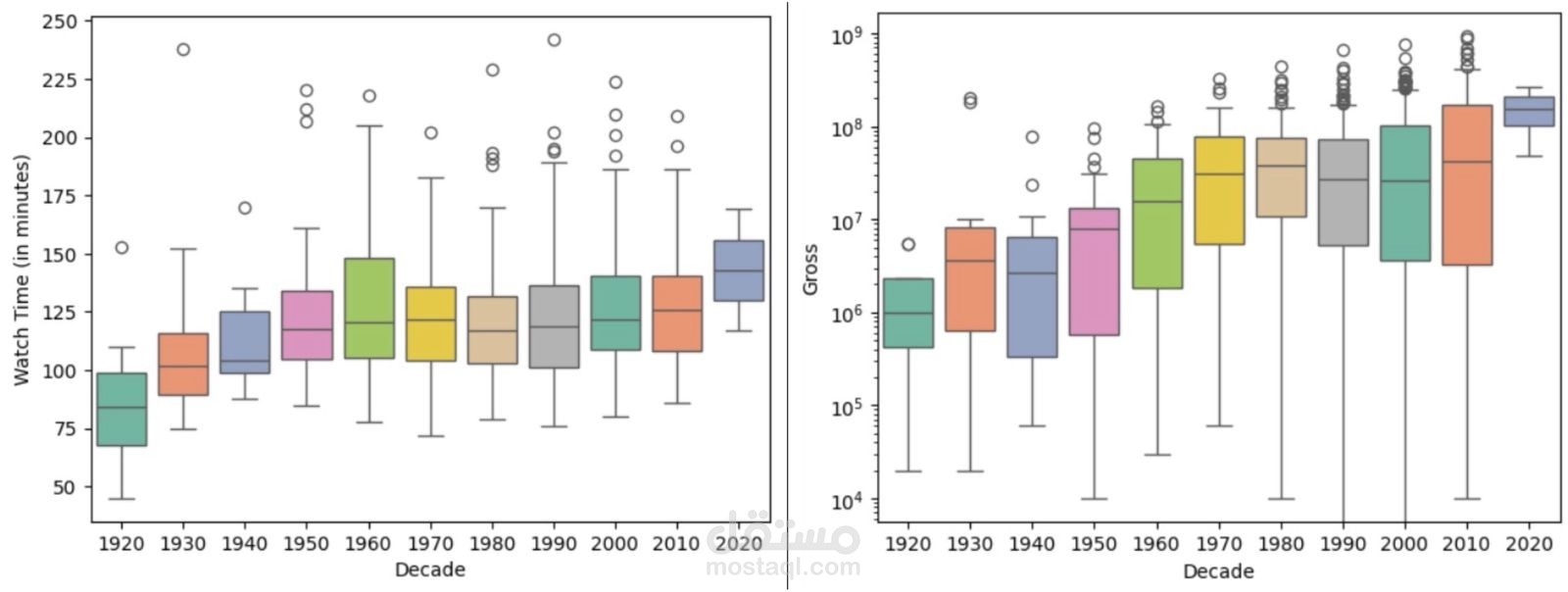
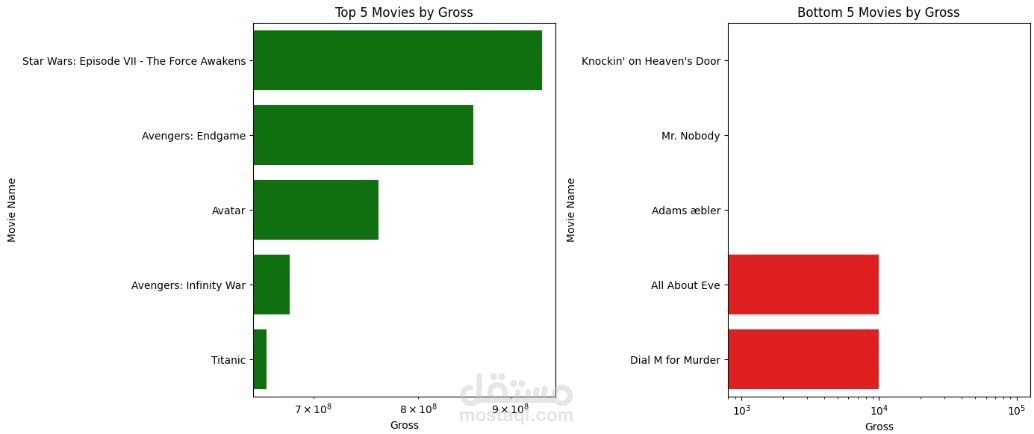
Boxplots: للكشف عن القيم المتطرفة في الإيرادات والتقييمات.
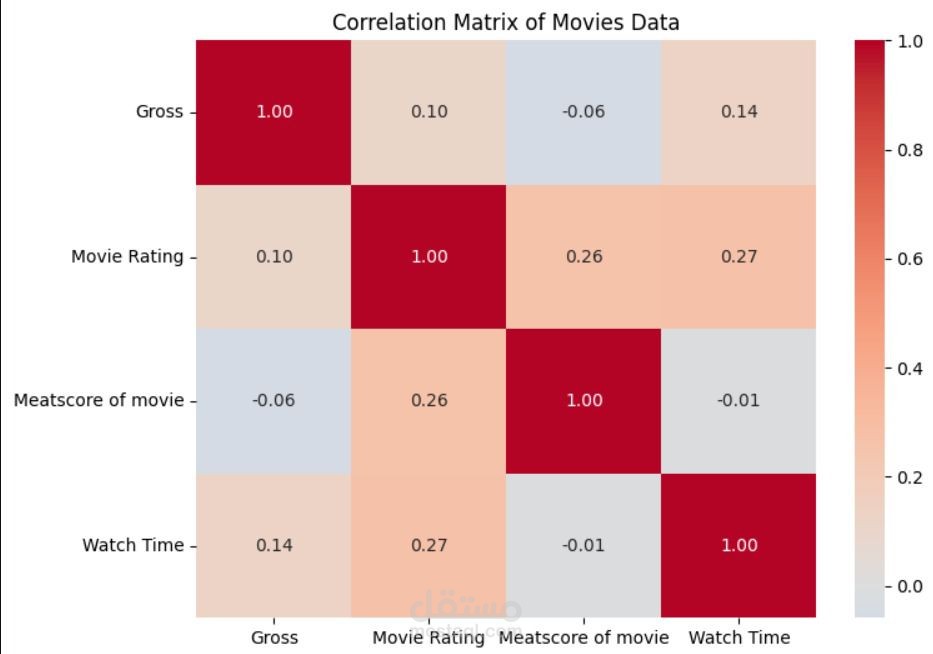
Heatmap: لفحص العلاقات بين الأصوات، الإيرادات، والتقييمات.
النتيجة
البيانات أصبحت نظيفة وموحدة، جاهزة للتحليل والنمذجة.
التحليل كشف عن:
زيادة إنتاج الأفلام في سنوات معينة.
ارتباط قوي بين عدد الأصوات والإيرادات.
وجود أفلام استثنائية جدًا (outliers) سواء في الإيرادات أو التقييمات.