sql code
تفاصيل العمل
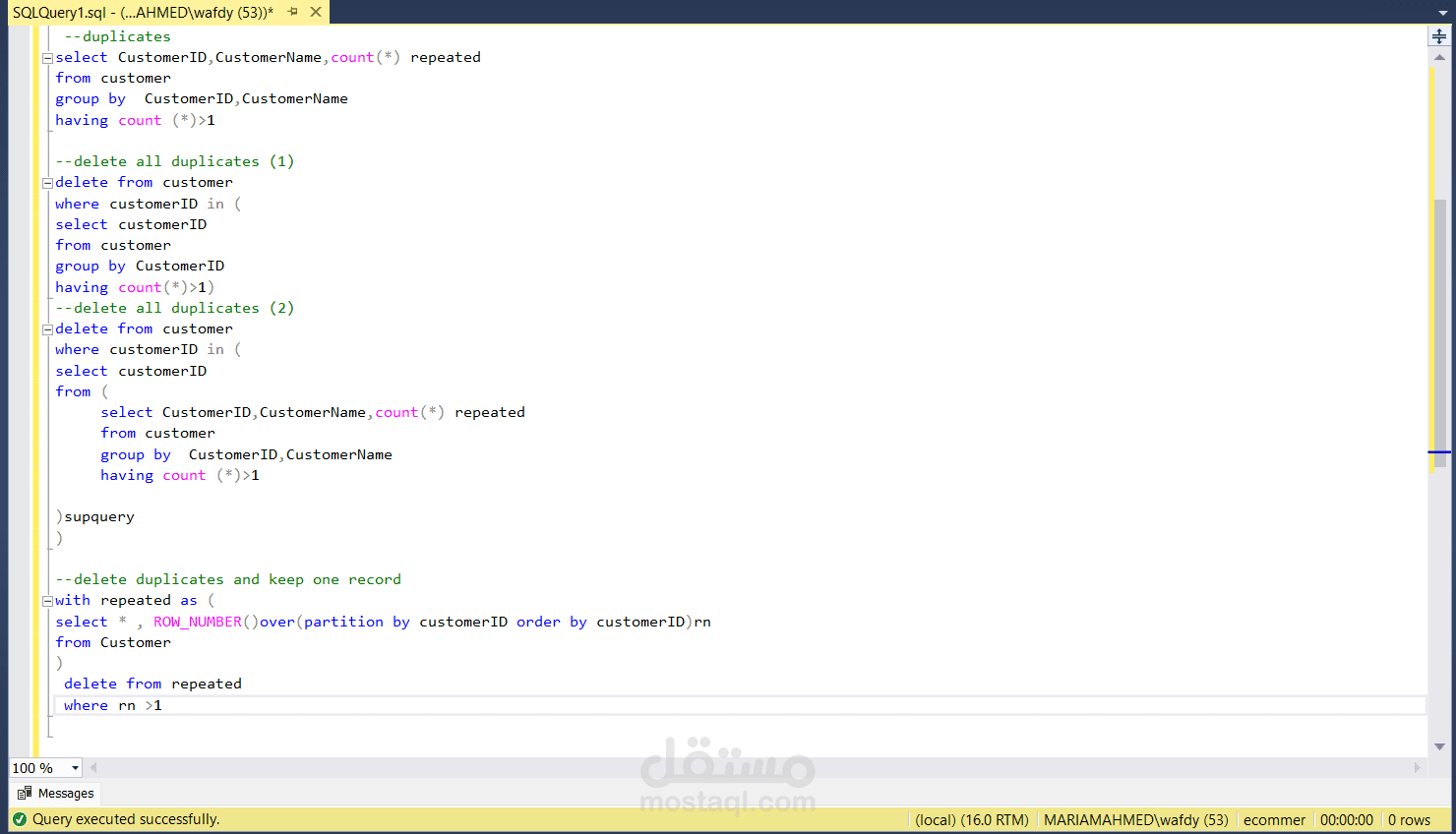
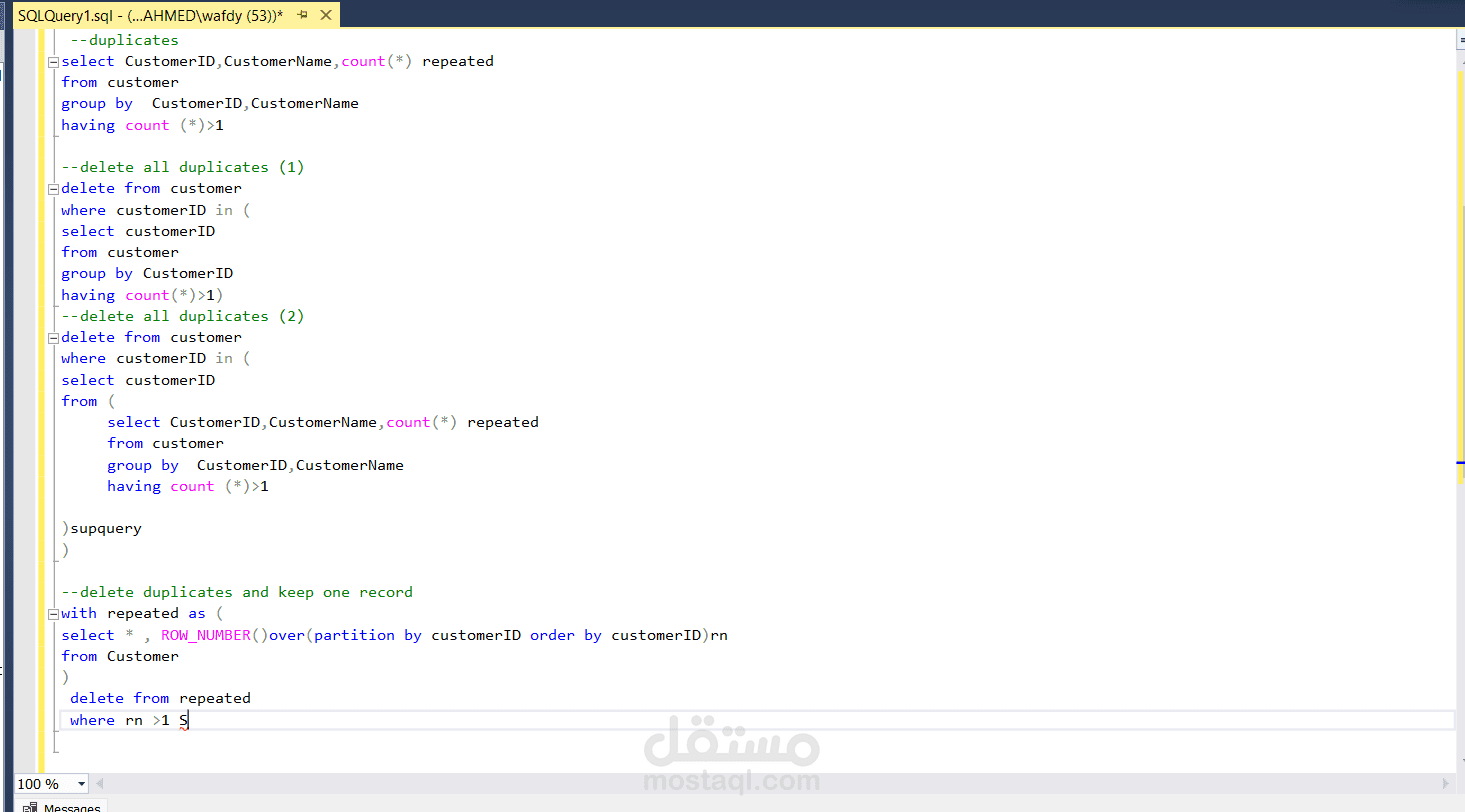
Today I practiced handling duplicate records in SQL Server, which is a very common challenge in data management and analysis.
I tried different approaches:
Identifying duplicates using GROUP BY and HAVING.
Deleting all duplicates.
Deleting duplicates while keeping one clean record using ROW_NUMBER().
This exercise helped me strengthen my understanding of data cleaning, which is a crucial step before any meaningful analysis.
Data quality is the foundation of reliable insights, and improving my SQL skills is one step closer to becoming more effective in Data Analysis & AI projects.