تجربة مقارنة بين نماذج تعليم الآلة
تفاصيل العمل
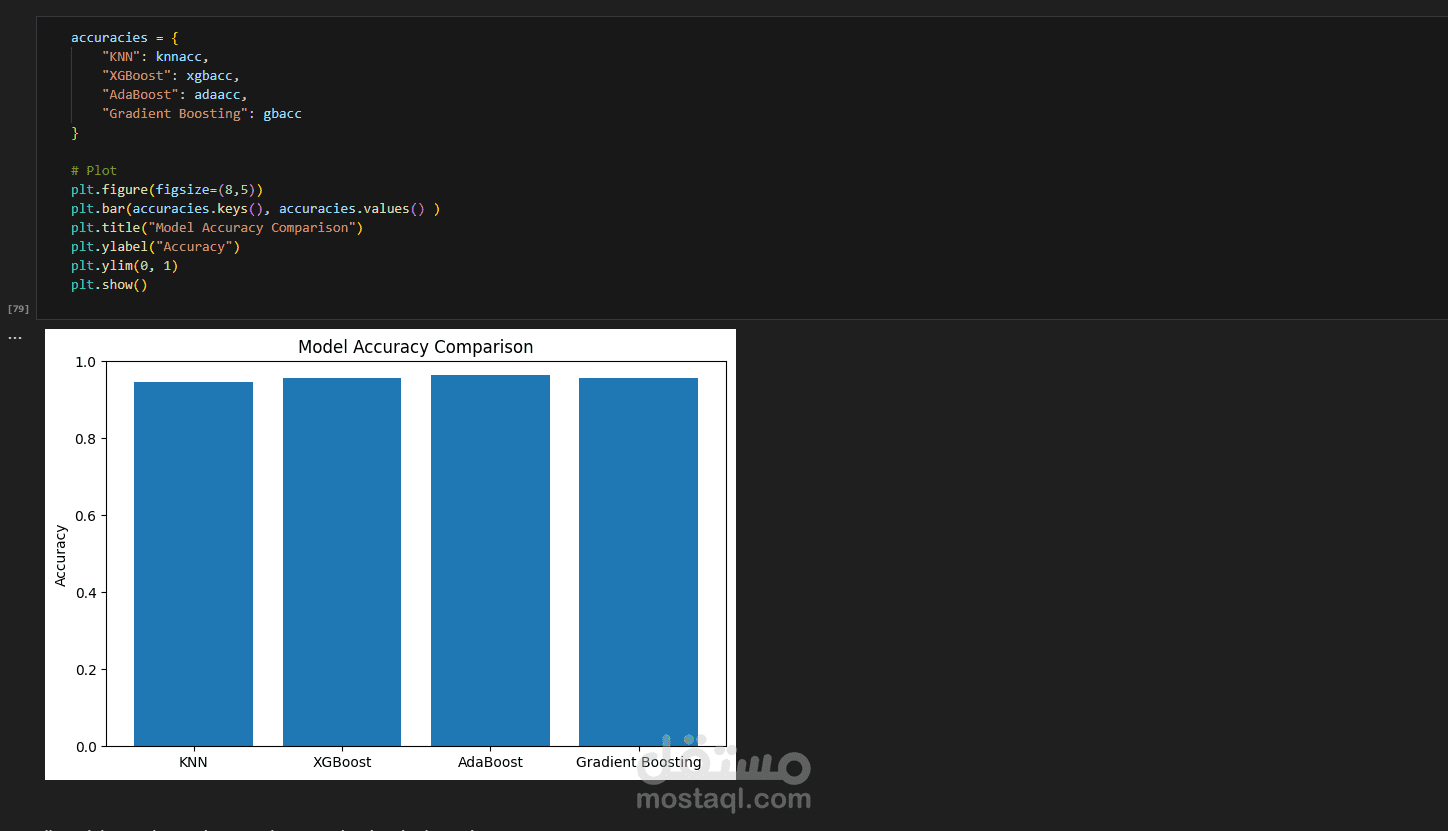
في إطار عملي على تحليل البيانات وبناء نماذج ذكاء اصطناعي، قمت باستخدام عدة خوارزميات مختلفة على نفس مجموعة البيانات، وذلك بهدف اختيار النموذج الأفضل من حيث الدقة والكفاءة.
النماذج المستخدمة:
Logistic Regression
بسيط وسهل التفسير.
مناسب كبداية للمقارنة.
Random Forest
يعتمد على عدة أشجار قرار (Decision Trees).
قوي في التعامل مع البيانات المعقدة ويقلل من مشكلة Overfitting.
Support Vector Machine (SVM)
يحدد أفضل خط فاصل بين الفئات.
فعال مع البيانات ذات الأبعاد العالية.
K-Nearest Neighbors (KNN)
يعتمد على التشابه بين النقاط.
سهل الفهم لكنه أبطأ مع البيانات الكبيرة.