Simple Naive Bayes project
تفاصيل العمل
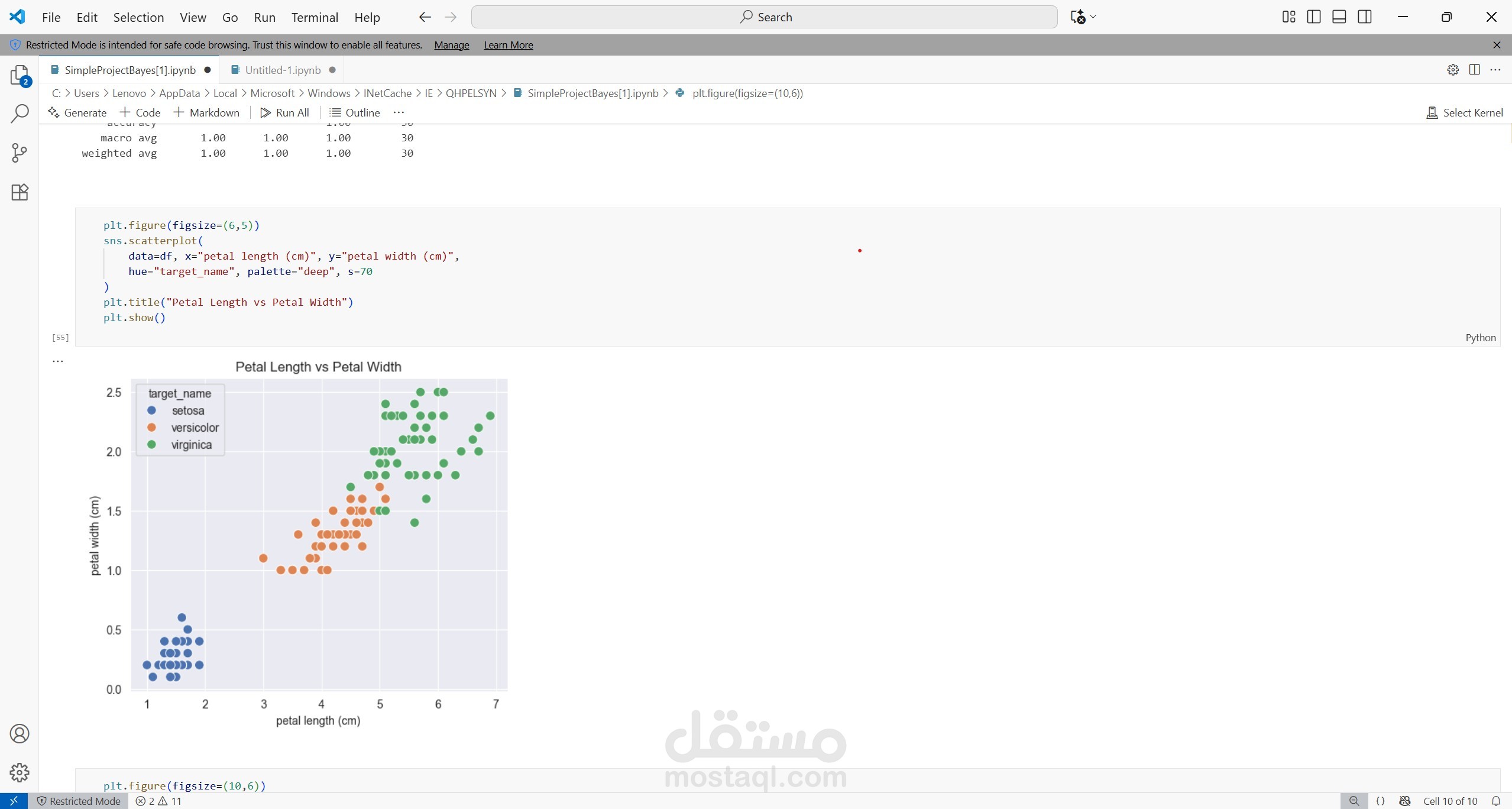
مشروع: تطبيق خوارزمية Naive Bayes في التصنيف
في هذا المشروع قمت بتطبيق خوارزمية Naive Bayes (إحدى خوارزميات التعلم الآلي الاحتمالية) بهدف تصنيف البيانات والتنبؤ بالنتائج بناءً على السمات (Features).
الخوارزمية تعتمد على نظرية بايز Bayes’ Theorem مع افتراض استقلالية المتغيرات، وهو ما يجعلها سريعة وبسيطة وفعالة في التعامل مع مجموعات البيانات المختلفة.
خطوات المشروع شملت:
معالجة البيانات: تنظيف البيانات وتجهيزها للتدريب.
تقسيم البيانات: إلى بيانات تدريب (Training) وبيانات اختبار (Testing).
تطبيق نموذج Naive Bayes: باستخدام مكتبة Scikit-learn في Python.
تقييم النموذج: عبر مقاييس مثل الدقة (Accuracy)، المصفوفة الالتباس (Confusion Matrix)، والدقة/الاستدعاء (Precision/Recall).
أمثلة لاستخدام النموذج:
تصنيف الرسائل إلى Spam / Not Spam.
التنبؤ بالصحة أو العادات (مثل علاقة القهوة بالنوم والصحة في قواعد البيانات).
تحليل المشاعر (Sentiment Analysis) للنصوص.
نتائج المشروع:
أظهر النموذج دقة جيدة في التصنيف، خاصة مع البيانات النصية والفئوية.
تميز بسرعة التنفيذ مقارنة بخوارزميات أكثر تعقيدًا.
مناسب كنموذج أساسي (Baseline Model) للمقارنة مع نماذج أخرى أكثر تطورًا.
الأدوات المستخدمة: Python (Pandas, NumPy, Scikit-learn, Matplotlib, Seaborn).