Machine learning model
تفاصيل العمل
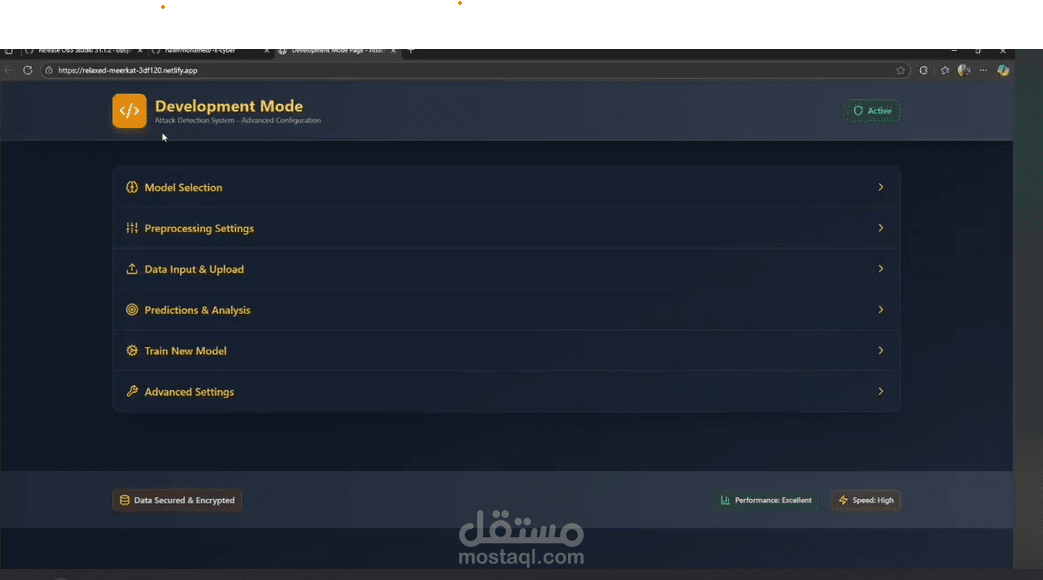
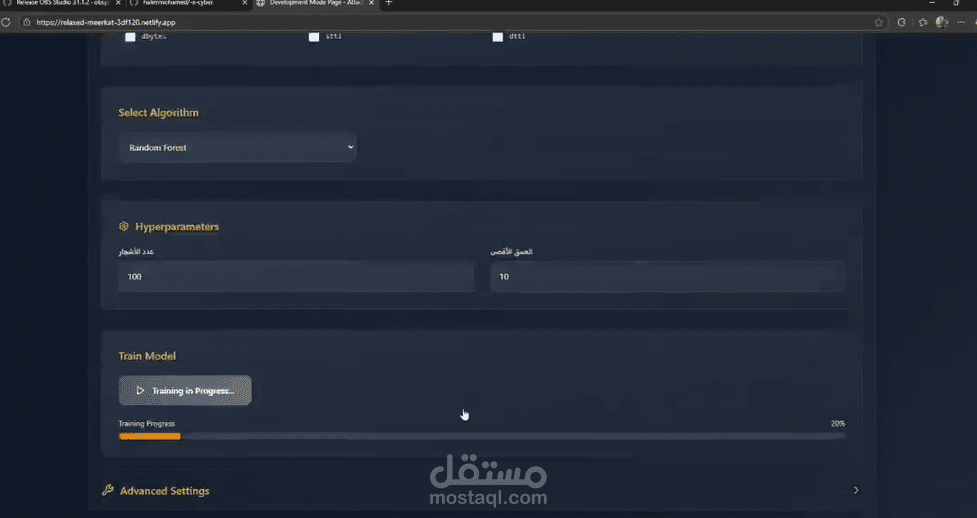
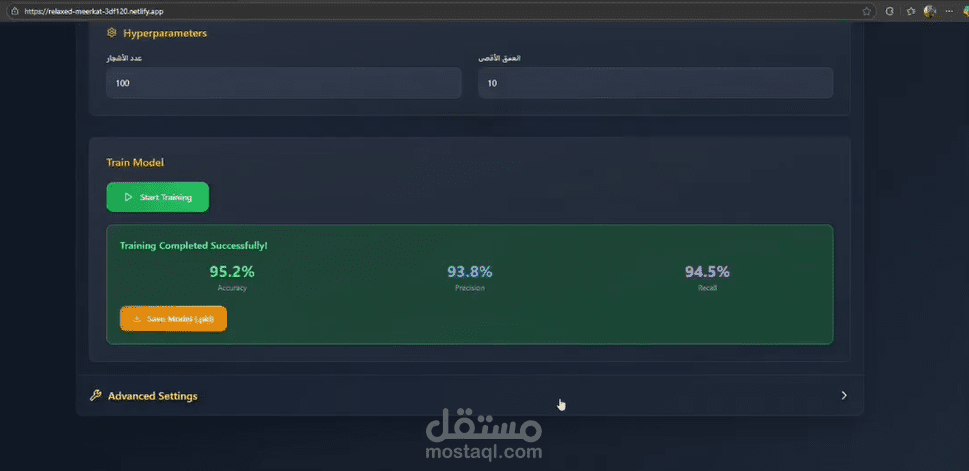
فكرة المشروع
الهدف: تصنيف الهجمات اللي ممكن تحصل على الشركات (زي DoS, Brute Force, Phishing …إلخ) باستخدام خوارزميات تعلم الآلة.
الفايدة: تساعد فرق الأمن السيبراني في الكشف المبكر عن الهجمات وتقليل الخسائر.
خطوات المشروع (Pipeline)
تجهيز البيانات (Data Preparation):
جمع البيانات (مثلاً UNSW-NB15 أو أي dataset خاصة بالهجمات).
تنظيف البيانات: إزالة الفراغات، القيم الغلط، والدوبلكيت.
معالجة القيم المفقودة (imputation أو استبعاد).
تقسيم الأعمدة لـ عددية (numeric) و تصنيفية (categorical).
تحويل البيانات (Preprocessing):
StandardScaler للأعمدة العددية.
OneHotEncoder أو Target Encoding للأعمدة النصية.
التعامل مع عدم توازن الكلاسات باستخدام SMOTE أو class weights.
اختيار النماذج (Models):
Logistic Regression (baseline).
Random Forest.
SVM.
XGBoost / LightGBM (الأكثر قوة عادة).
تدريب وتقييم (Training & Evaluation):
تقسيم Train/Test (مثلاً 80/20).
استخدام cross-validation.
تقييم بمقاييس مهمة:
Accuracy (لكن مش كافية لو فيه عدم توازن).
Precision, Recall, F1-score.
Confusion Matrix.
ROC-AUC و PR-AUC.
تحليل النتائج (Results Analysis):
مقارنة أداء الموديلات.
أفضل موديل غالبًا بيكون XGBoost أو Random Forest.
عرض أهم الميزات (Feature Importance).
التفسير (Explainability):
استخدام SHAP أو LIME لفهم ليه الموديل اختار الهجوم ده.
ده مهم جدًا في مجال الأمن عشان يبقى فيه ثقة في الموديل.
النشر (Deployment):
حفظ الموديل بـ joblib أو pickle.
بناء واجهة (API) باستخدام Flask أو FastAPI.
أو استخدام Gradio / Streamlit لواجهة سهلة للتجربة.