اكتشاف الأخبار الكاذبة باستخدام تقنيات التعلم الآلي و التعلم العميق
تفاصيل العمل
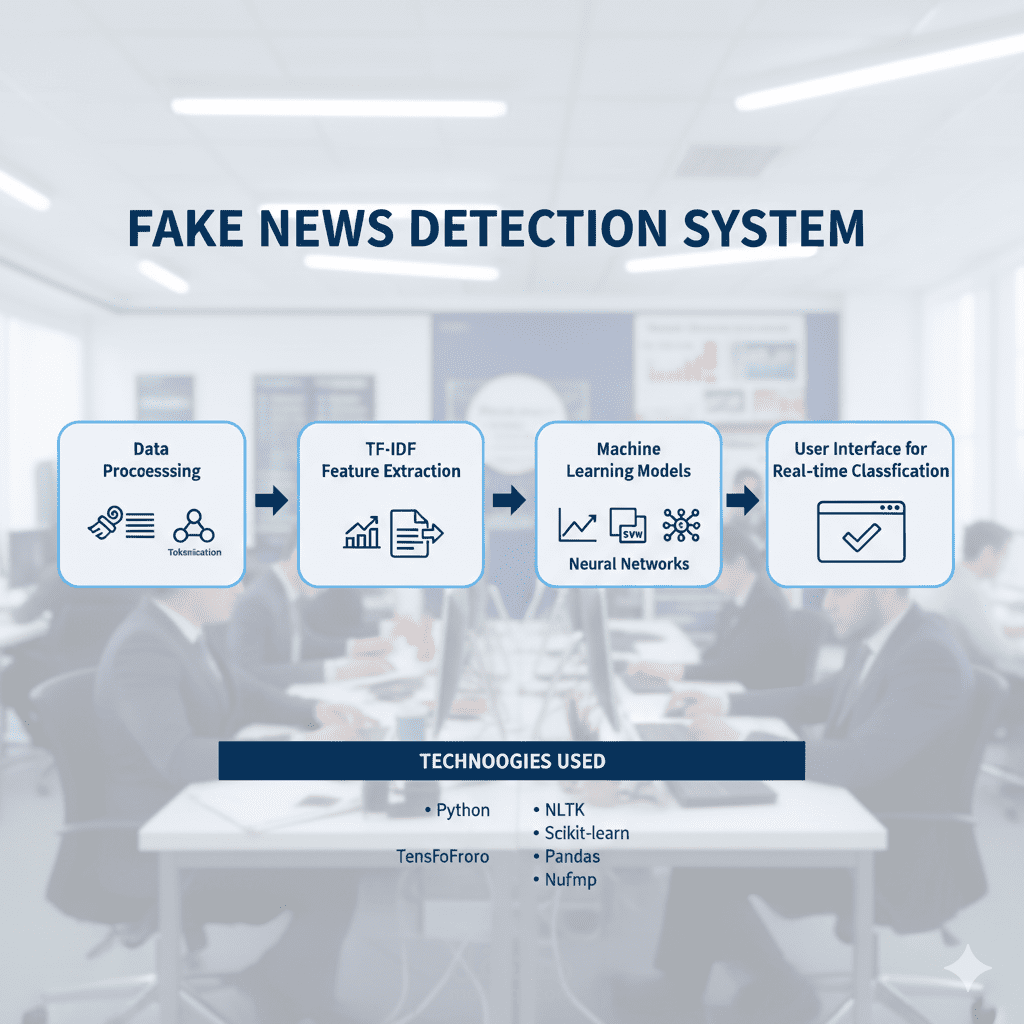
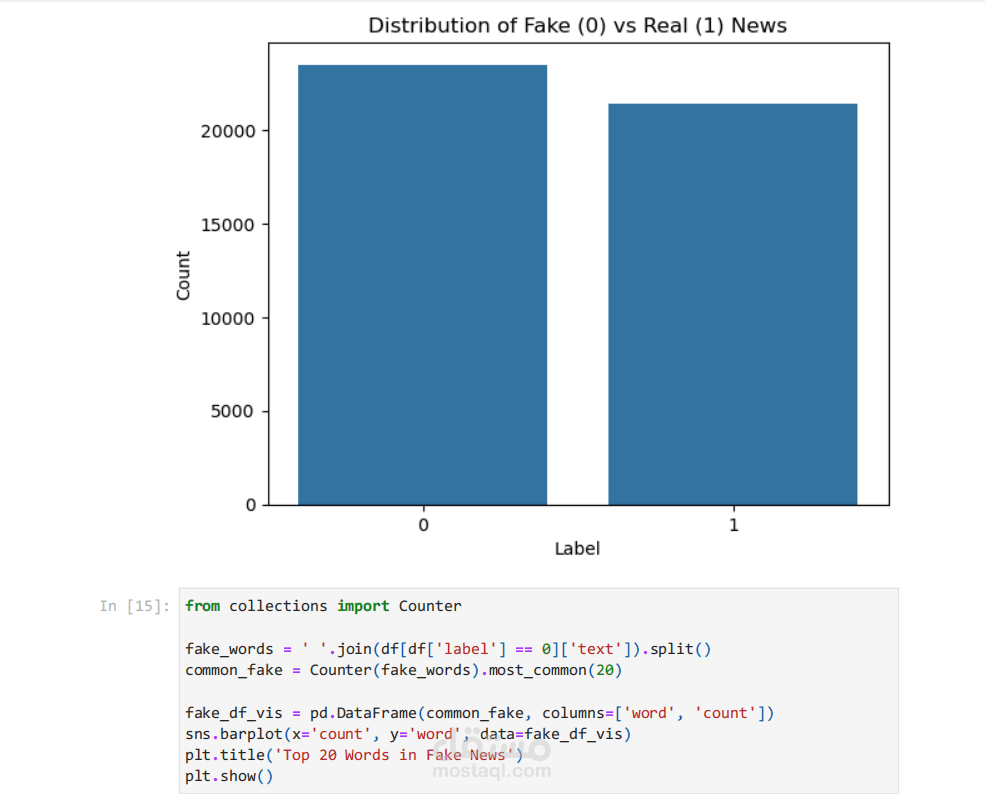
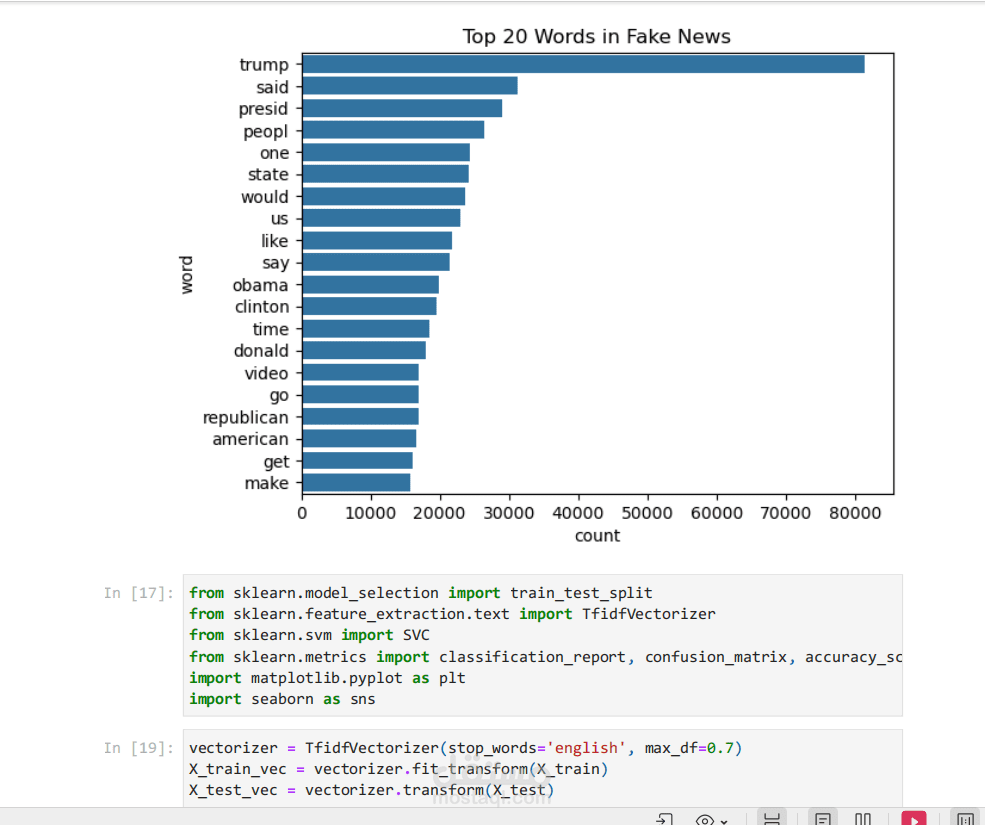
يهدف هذا المشروع إلى اكتشاف الأخبار الكاذبة باستخدام تقنيات التعلم الآلي و التعلم العميق. اعتمدنا على مجموعة بيانات تحتوي على أخبار حقيقية وأخرى مزيفة، حيث تم تجهيز النصوص من خلال عمليات تنظيف تشمل إزالة الأرقام وعلامات الترقيم، وتحويل الكلمات إلى صيغة موحدة (Stemming)، بالإضافة إلى التخلص من الكلمات الشائعة غير المفيدة (Stopwords). بعد ذلك تم تحويل النصوص إلى تمثيل عددي باستخدام طريقة TF-IDF.
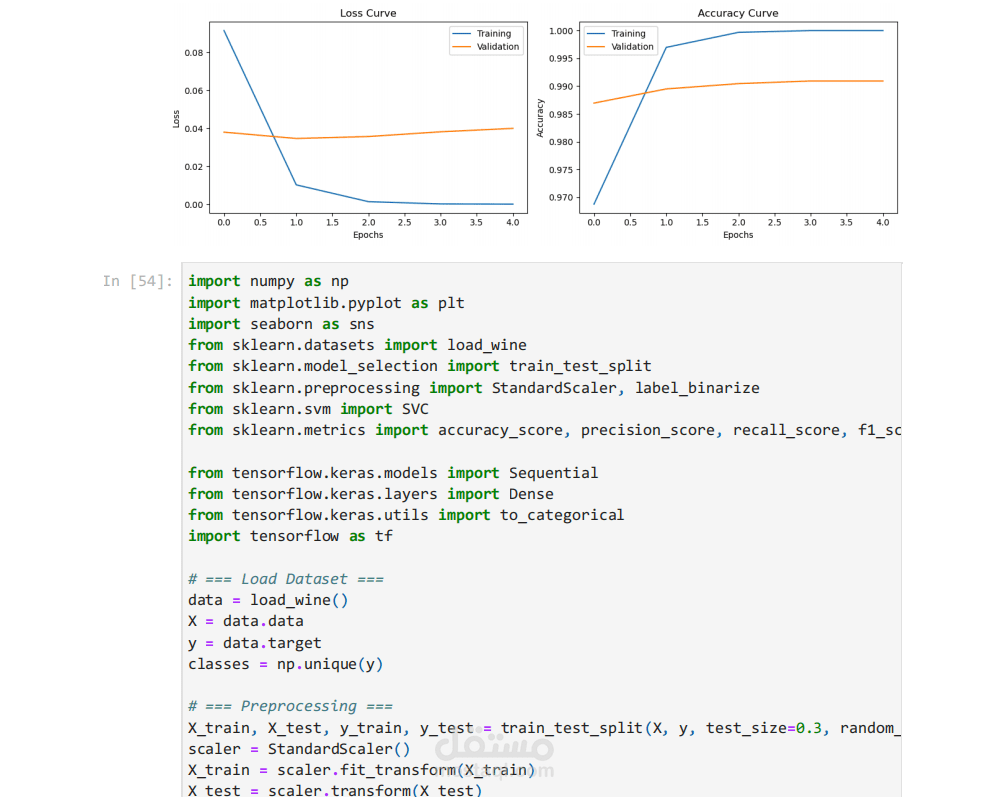
تم تدريب عدة نماذج لتصنيف الأخبار، أهمها آلة متجه الدعم (SVM) باستخدام أنواع مختلفة من النوى (linear, poly, rbf)، وكذلك شبكة عصبية مبنية باستخدام مكتبة TensorFlow/Keras. تم تقييم النماذج باستخدام مقاييس مثل الدقة (Accuracy) و الاستدعاء (Recall) و المعامل F1، إلى جانب عرض مصفوفة الالتباس (Confusion Matrix) ومنحنيات الأداء. وقد حققت النماذج دقة عالية وصلت إلى حوالي %99 في التمييز بين الأخبار الحقيقية والمزيفة.
كما تضمن المشروع تجربة إضافية على مجموعة بيانات النبيذ (Wine Dataset) لتصنيف الأنواع المختلفة باستخدام كل من SVM والشبكات العصبية، ومقارنة أدائهما في حالة التصنيف متعدد الفئات.
وبشكل عام، يوضح هذا المشروع مدى فعالية الجمع بين تقنيات معالجة اللغة الطبيعية (NLP) وخوارزميات التعلم الآلي والعميق في بناء أنظمة موثوقة لاكتشاف الأخبار الكاذبة.