التنبؤ باللياقة باستخدام الذكاء الاصطناعي
تفاصيل العمل


نظيف البيانات: معالجة القيم المفقودة، إزالة التكرارات، والتعامل مع القيم الشاذة.
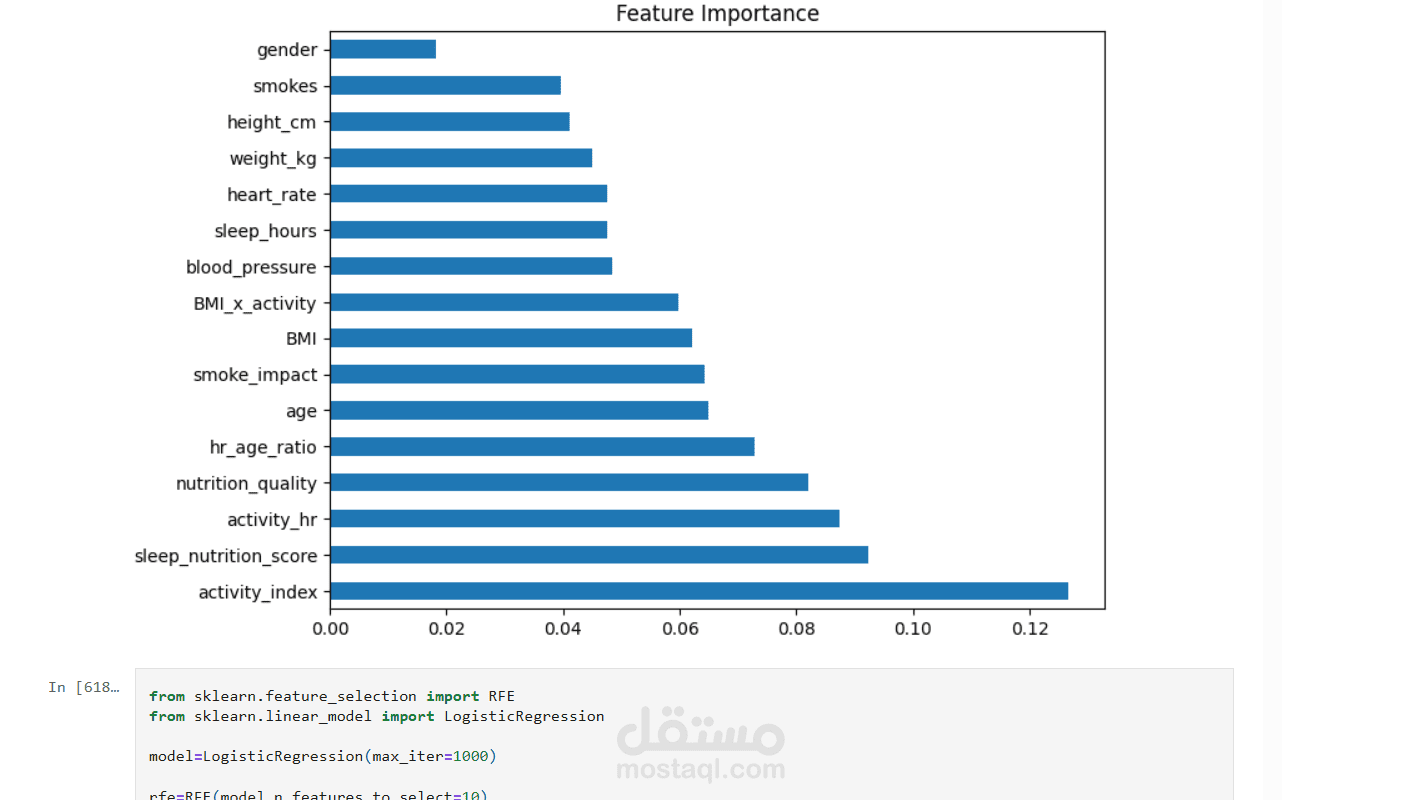
هندسة الخصائص: إنشاء خصائص جديدة مثل:
مؤشر كتلة الجسم (BMI)
نسبة معدل ضربات القلب إلى العمر (hr_age_ratio)
مقياس النوم والتغذية (sleep_nutrition_score)
تأثير التدخين على ضغط الدم (smoke_impact)
التحليل الاستكشافي (EDA): رسم التوزيعات، العلاقات، والارتباطات بين المتغيرات.
اختيار الخصائص: باستخدام تقنيات (RFE, SFS, Feature Importance).
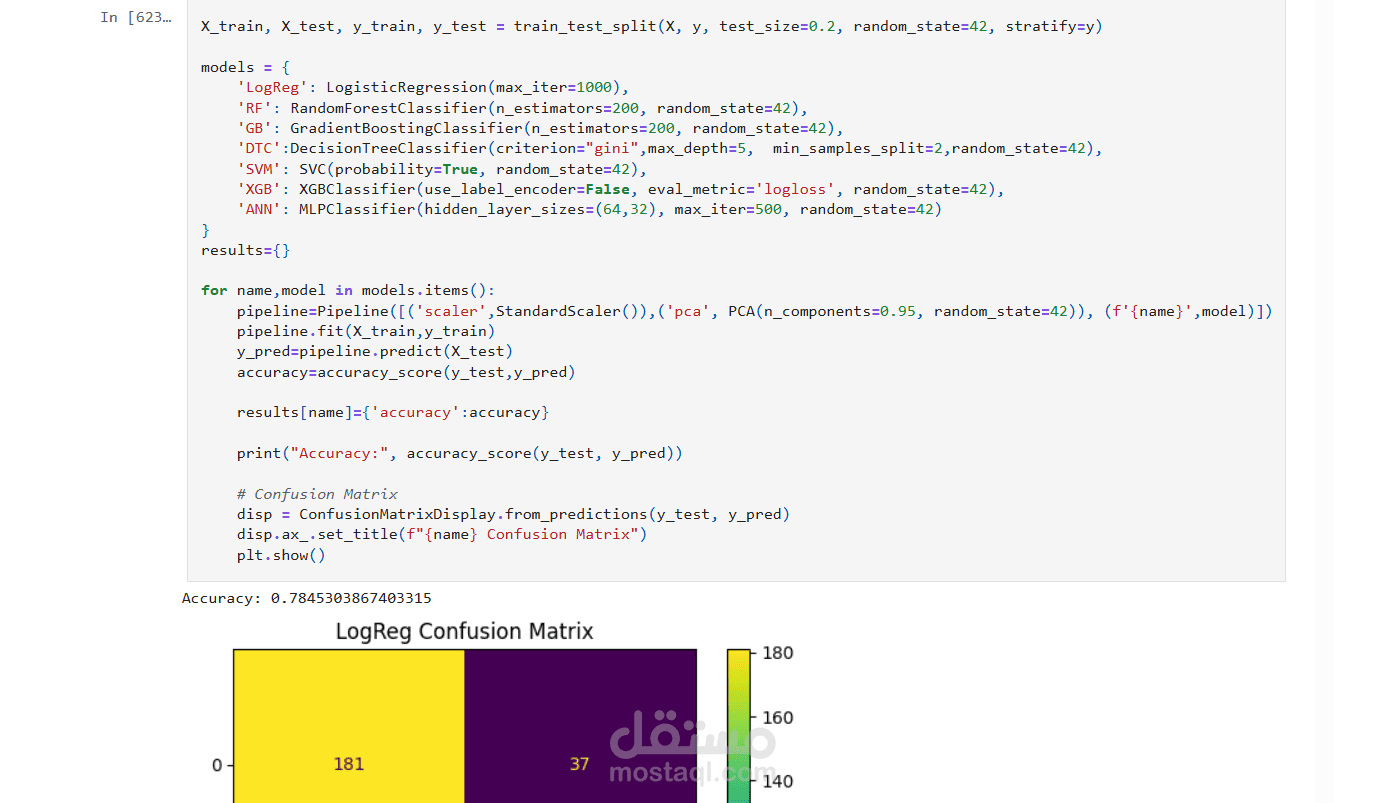
تدريب النماذج: اختبار عدة خوارزميات مثل: Logistic Regression, Decision Tree, Random Forest, Gradient Boosting, SVM, XGBoost, ANN.
تحسين النماذج: استخدام GridSearchCV لضبط المعاملات.
النموذج النهائي: اختيار الانحدار اللوجستي (Logistic Regression) كأفضل نموذج وحفظه بصيغة .pkl.
جاهز للنشر: تصميم المشروع ليتم نشره عبر تطبيق Streamlit للتفاعل مع المستخدم.
المخرجات (Deliverables)
ملف Jupyter Notebook أو سكربت Python موثق بشكل احترافي.
النموذج المدرب محفوظ بصيغة .pkl.
ملف README يشرح خطوات العمل بالتفصيل.
رسوم بيانية ونتائج التحليل.
️ التقنيات المستخدمة
Python (Pandas, NumPy, Scikit-learn, XGBoost, Matplotlib, Seaborn).
أساليب اختيار الخصائص (RFE, SFS, PCA).
خوارزميات تعلم الآلة للتصنيف.
Streamlit لواجهة الاستخدام والتطبيق العملي.
القيمة المضافة
يساعد مراكز اللياقة والمدربين والأطباء على تحليل بيانات الصحة واللياقة.
يمكن دمجه مع تطبيقات صحية للتنبؤ باللياقة بشكل فوري.
قابل للتطوير بإضافة بيانات أكبر وأكثر تنوعًا.