بناء نموذج تعلم آلة (Machine Learning) للتنبؤ بالناجين من سفينة تايتانيك
تفاصيل العمل
مشروع علم بيانات متكامل لتحليل مجموعة البيانات الشهيرة الخاصة بركاب سفينة تايتانيك، بهدف بناء نموذج تعلم آلة (Machine Learning) قادر على التنبؤ بفرص نجاة الركاب.
مر المشروع بالمراحل الكاملة لمشاريع علم البيانات:
تنظيف وإعداد البيانات (Data Preprocessing): التعامل مع البيانات المفقودة (مثل العمر)، وتحويل البيانات الوصفية (مثل الجنس) إلى بيانات رقمية.
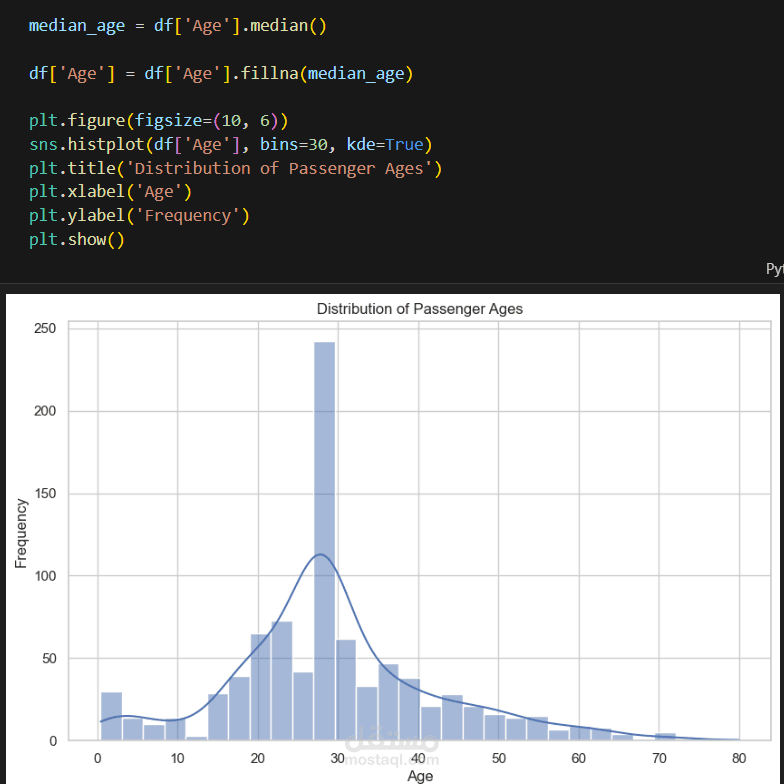
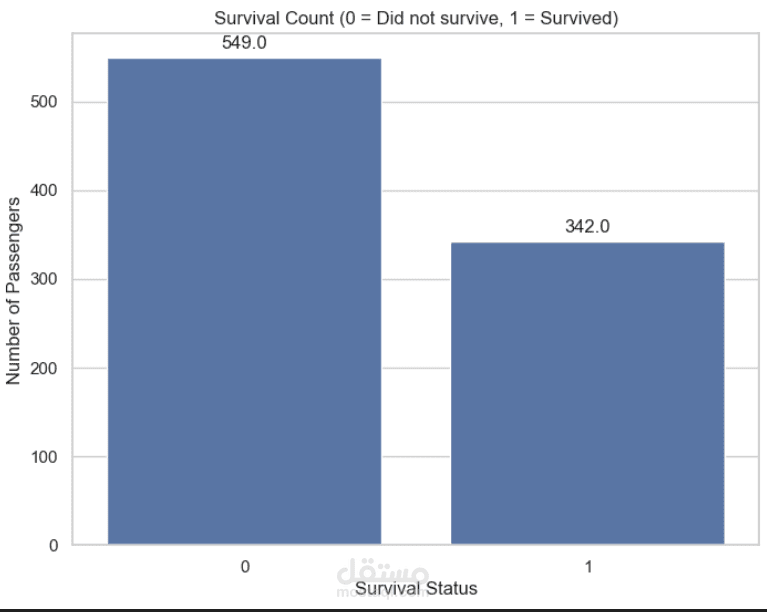
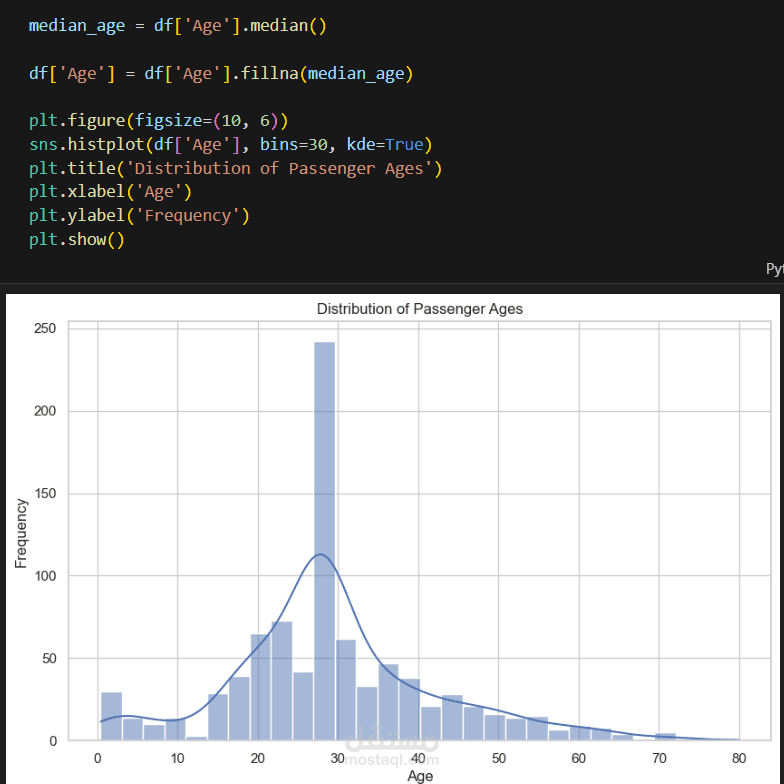
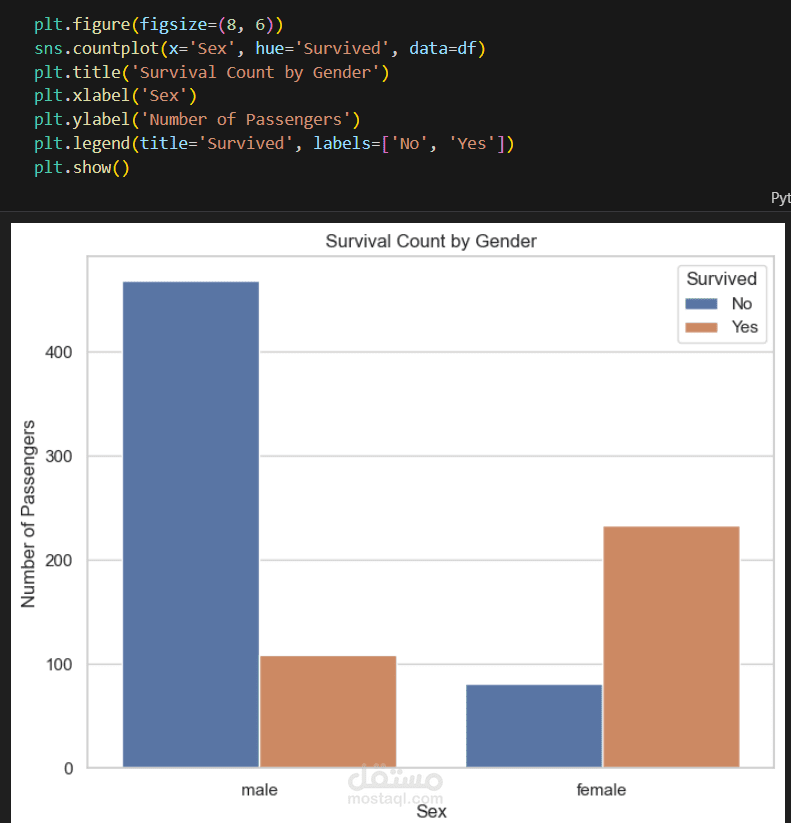
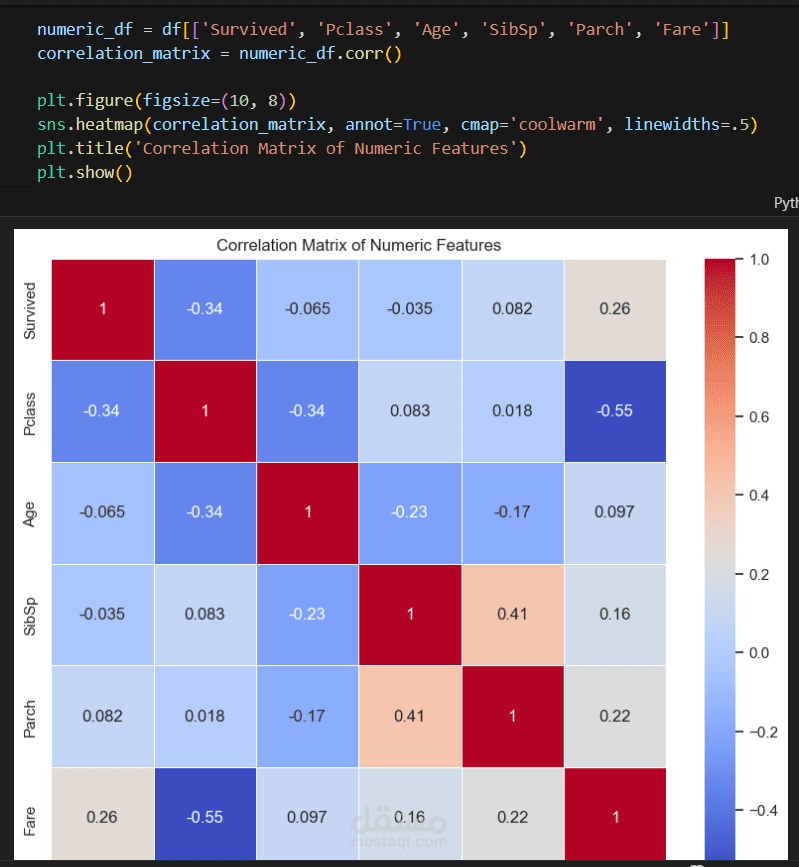
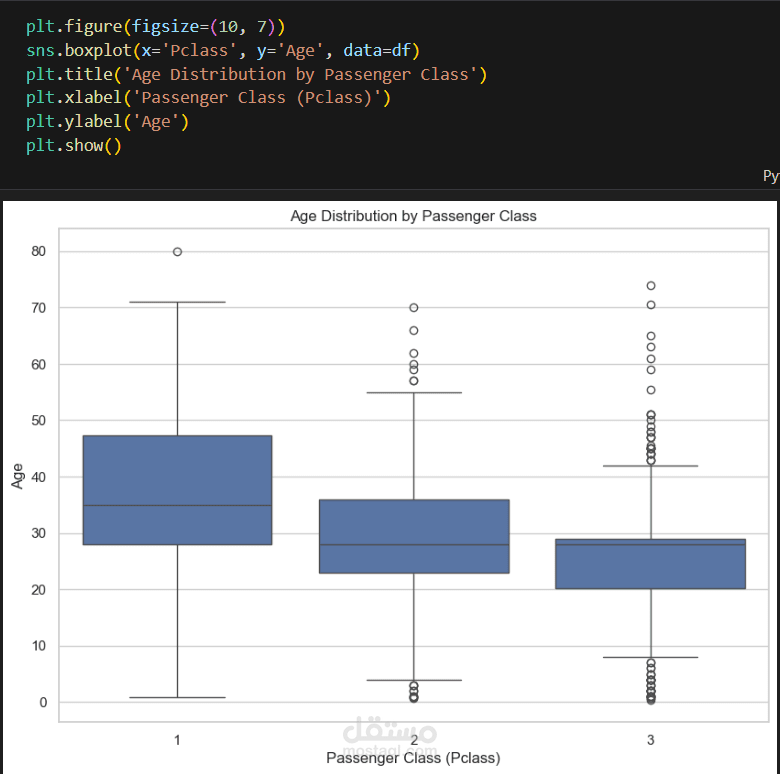
التحليل الاستكشافي للبيانات (EDA): إنشاء تصورات ورسوم بيانية لفهم العوامل التي أثرت في نسبة النجاة، مثل درجة السفر، الجنس، والعمر.
بناء النماذج التنبؤية (Model Building): تدريب وتقييم عدة خوارزميات تصنيف مختلفة مثل (Logistic Regression, Decision Tree, Random Forest).
تقييم النماذج (Model Evaluation): مقارنة أداء النماذج باستخدام مقياس الدقة (Accuracy) لاختيار النموذج الأفضل أداءً.
تم تنفيذ المشروع باستخدام Python ومكتبات علم البيانات الأساسية مثل Pandas, NumPy, Matplotlib, Seaborn, ومكتبة تعلم الآلة Scikit-learn.