Customer Segmentation
تفاصيل العمل
في المشروع ده استخدمت Mall Customers Dataset (200 صف × 5 أعمدة) لتقسيم العملاء إلى مجموعات مختلفة بناءً على العمر، الدخل السنوي، ودرجة الإنفاق بهدف مساعدة الشركات على فهم سلوك العملاء وتصميم استراتيجيات تسويق أفضل.
الخطوات:
تنظيف البيانات من القيم المفقودة والمكررة والتعامل مع القيم الشاذة.
تحليل استكشافي (EDA) باستخدام الرسوم البيانية لفهم التوزيعات والعلاقات بين المتغيرات.
تجهيز البيانات: ترميز النوع (Gender)، وتوحيد القيم باستخدام StandardScaler.
تطبيق خوارزميات التجميع:
K-Means (باستخدام Elbow Method واختيار k=5).
DBSCAN لاكتشاف المجموعات غير الخطية.
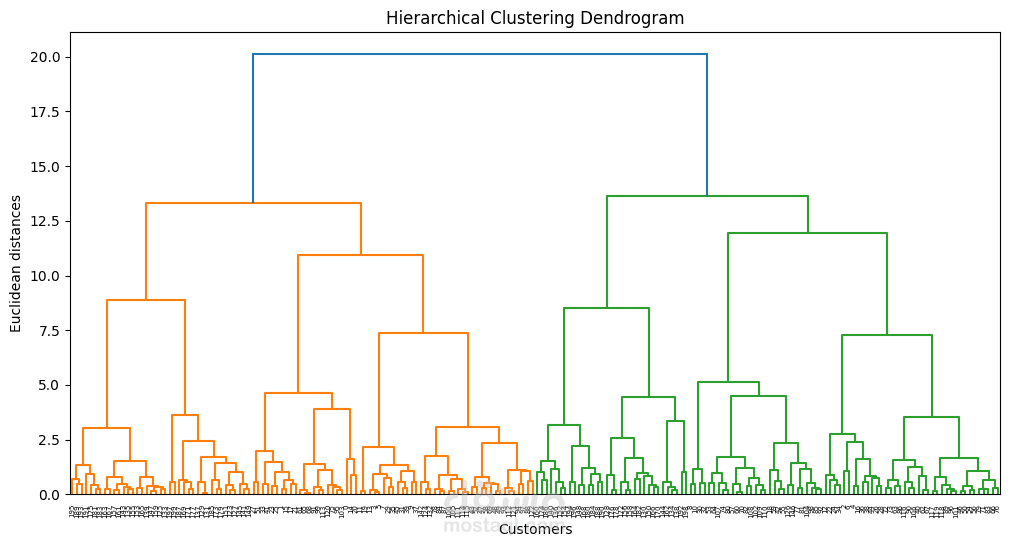
Hierarchical Clustering مع بناء Dendrogram.
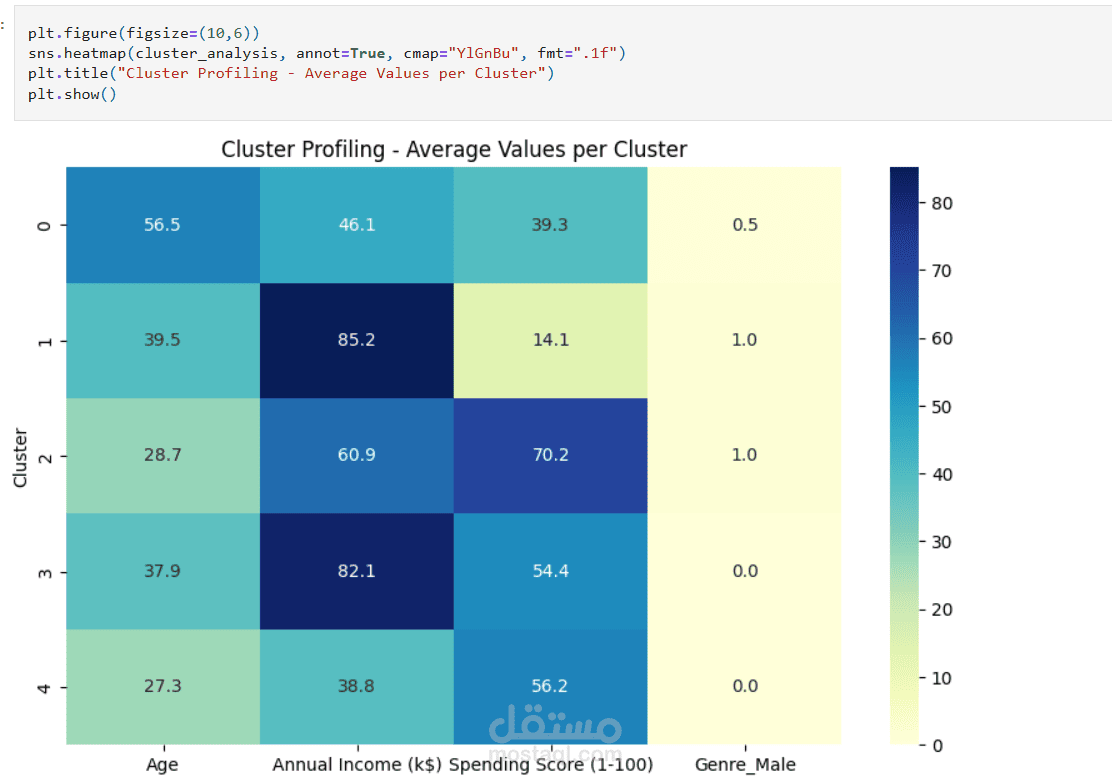
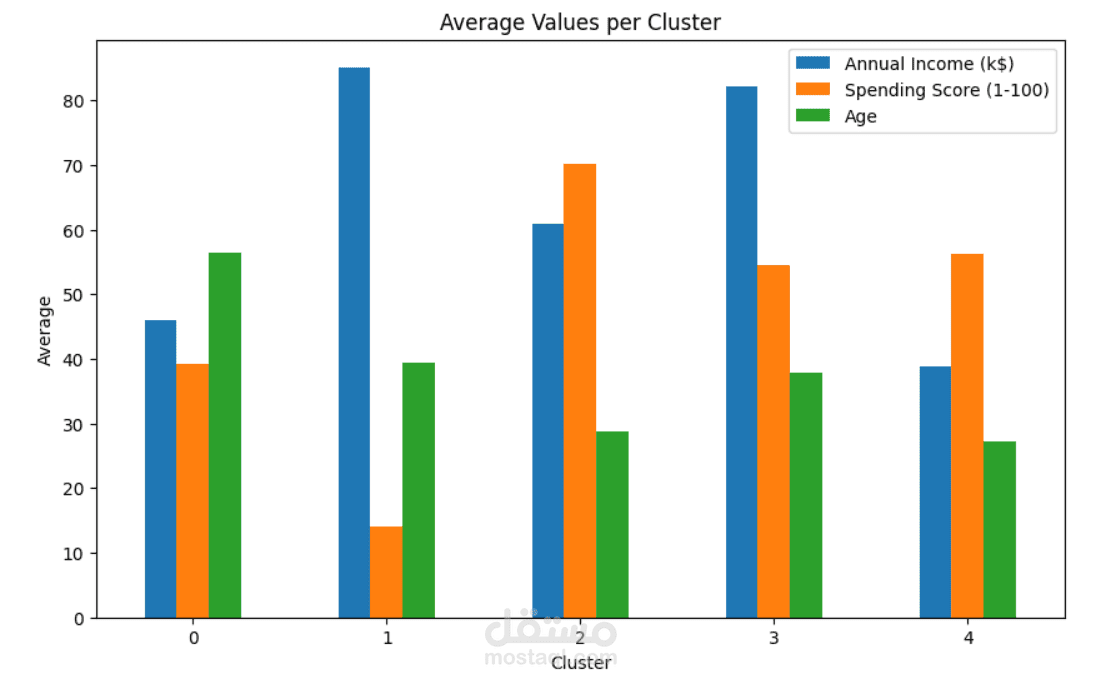
تحليل كل Cluster وتحديد خصائصه (مثل العملاء ذوي الدخل العالي لكن إنفاق منخفض، أو الشباب ذوي الإنفاق المرتفع).
النتائج:
أفضل تقسيم باستخدام K-Means لخمسة مجموعات واضحة.
أظهرت النتائج عملاء مهمين (High income & High spending) يمثلون قيمة كبيرة للشركات.
استخدمت التصورات (Scatterplots, Heatmaps, Dendrograms) لعرض النتائج بوضوح.
الأدوات والتقنيات:
Python, Pandas, NumPy, Matplotlib, Seaborn, Scikit-learn (KMeans, DBSCAN, StandardScaler), SciPy (Hierarchical Clustering).